安装 pywin32 和python版本一致
地址 https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/
安装过程中提示找不到Python2.7
解决方法:http://blog.csdn.net/pppii/article/details/48679403
安装Scrapy 使用pip
1、使用命令行创建爬虫项目
scrapy startproject myspider # cmd进入指定文件夹后创建一个名为 myspider的爬虫
2、启动pyCharm
打开项目 myspider ,在文件夹spiders下创建MySprider.py文件
添加我的爬虫 class Channel9Spider(scrapy.Spider):
name 表示爬虫的名称 属于唯一属性
allowed_domins=[] 爬虫允许的域
start_urls=[] 爬虫开始的页面
def parse(self,response): 访问地址后调用的方法
def details_parse(self,response): 处理详情页面的方法
MySprider.py遇到的问题:
1、windows命令提示符中打印爬取的文件名报错
原因:是命令行字符集和网页字符集不一致
处理方法:print item["title"].encode("gbk","ignore")
2、回调方法报错
原因:PyScrapy默认给回调加了个括号
处理方法:去掉回调方法后的括号,需要传参使用Request(url=.. , meta={'name':'yancl',....},calback=self.details_parse,dont_filter=True)
3、提示访问被拒绝
原因:1、robots 协议问题 2、由于设置了允许爬取的域
处理方法:1、修改settings.py 设置ROBOTSTXT_OBEY = True
2、调用Request方法设置dont_filter=True
打开 items.py
添加在处理页面后要传递给pipeline的item数据对象
用到了下载所以添加 file_urls,files,file_paths
打开 pipeline.py
1、添加一个继承FilesPipeline文件下载管道的实现方法 MyFilesPipeline
2、添加一个记录文件方法 JsonWithEncodingPipeline
打开settings.py
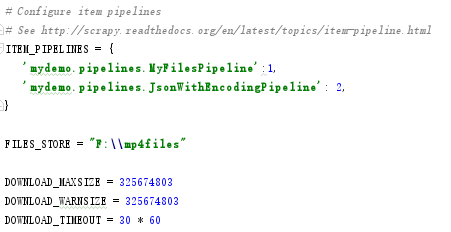
1、启用我的Item Pipeline组建。我打算下载一个视频就记录一条对应的Json信息
2、添加视频下载保存文件的路径
再次启动爬虫 scrapy crawl myspider
遇到的问题:
1、下载文件过大
2、连接超时
3、文件下载的路径问题,默认添加full的文件夹
4、文件名问题
对于问题1、2、3 修改settings
DOWNLOAD_MAXSIZE = 325674803 #字节
DOWNLOAD_WARNSIZE = 325674803 #字节
DOWNLOAD_TIMEOUT = 30 * 60 #单位秒
FILES_STORE = "F:\mp4files" #直接使用绝对路径
对于问题3,修改MyFilesPipeline方法 重写file_path方法
再次启动爬虫运行正常,但是还有2个小问题,1、有一个文件自动添加了文件夹 2、有几个文件没有后缀大小为0KB
根据日志分析是文件名导致了 文件名中不能有:/ 等特殊字符
MySpider.py
import scrapy
from mydemo.items import MydemoItem
from scrapy.http import Request
from scrapy.selector import Selector
download_domain = "https://channel9.msdn.com"
class Channel9Spider(scrapy.Spider):
name = "myspider"
allowed_domains = [".msdn.com"]
start_urls = [
"https://channel9.msdn.com/Events/Ignite/Microsoft-Ignite-China-2016?sort=status&direction=desc"
]
def parse(self,response):
sale = Selector(response)
for a in sale.xpath("//h3"):
title = a.xpath("a/text()").extract()[0]
line = a.xpath("a/@href").extract()[0]
fileurl = download_domain + line
yield Request(url=fileurl,meta={'title':title},callback=self.details_parse,dont_filter=True)
next_page = sale.xpath("//a[@rel='next']/@href").extract()
if next_page:
pagepath = download_domain+next_page[0]
yield Request(url=pagepath,callback=self.parse,dont_filter=True)
def details_parse(self,response):
sale = Selector(response)
item = MydemoItem()
item["title"] = response.meta['title']
fileurl = sale.xpath("//*[@id='format']/option/@value").extract()[0]
item["file_urls"] = [fileurl]
yield item
items.py
class MydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
content = scrapy.Field()
file_urls = scrapy.Field()
files = scrapy.Field()
file_paths = scrapy.Field()
pass
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
import codecs
import json
import time
from scrapy.pipelines.files import FilesPipeline
from scrapy.exceptions import DropItem
class MydemoPipeline(object):
def process_item(self, item, spider):
return item
class JsonWithEncodingPipeline(object):
def __init__(self):
self.file = codecs.open('file.json','w',encoding='utf-8')
def process_item(self,item,spider):
timeSatamp = time.time()
timeTuple = time.localtime(timeSatamp)
curTime = time.strftime("%Y-%m-%d %H:%M:%S",timeTuple)
line = "["+curTime+"] "+json.dumps(dict(item),ensure_ascii=False)+"
"
self.file.write(line)
return item
def spider_closed(self,spider):
self.file.close()
class MyFilesPipeline(FilesPipeline):
def get_media_requests(self,item,info):
for file_url in item['file_urls']:
yield scrapy.Request(file_url,meta={'title':item['title']})
def item_completed(self, results, item, info):
file_paths = [x['path'] for ok, x in results if ok]
if not file_paths:
raise DropItem("Item contains no Files")
item["file_paths"] = file_paths
return item
def file_path(self,request,response=None,info=None):
title = request.meta['title']
file_guid = title + '.'+request.url.split('/')[-1].split('.')[-1]
filename = u'{0}'.format(file_guid)
return filename
settings.py
生成的日志截图如下:

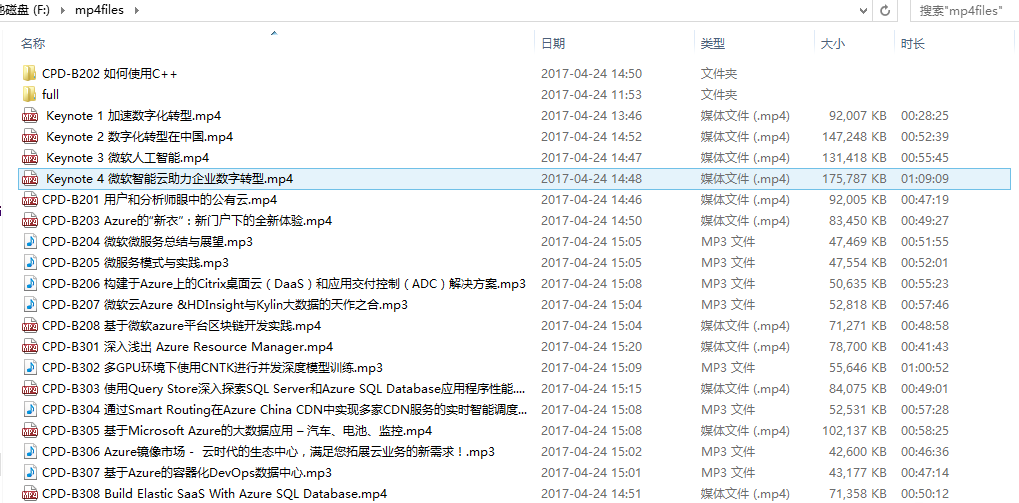
爬取的文件截图: