【一、项目目标】
获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名、专辑名、播放链接。
由浅入深,层层递进,非常适合刚入门的同学练手。
【二、需要的库】
主要涉及的库有:requests、json、openpyxl
【三、项目实现】
1.了解 QQ 音乐网站的 robots 协议

只禁止播放列表,可以操作。
2.进入 QQ 音乐主页 https://y.qq.com/
3.输入任意歌手,比如邓紫棋
4.打开审查元素(快捷键 Ctrl+Shift+I)
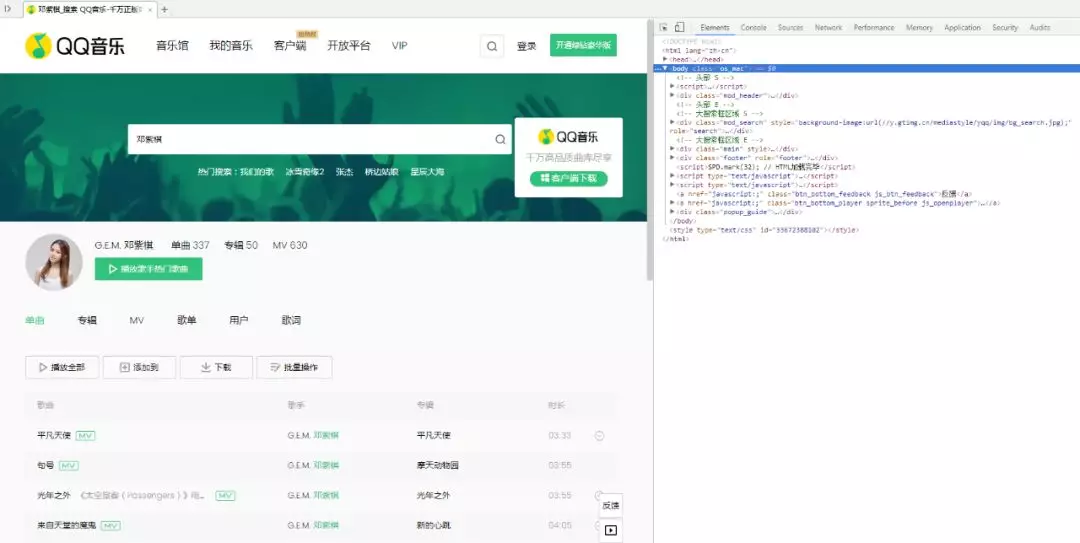
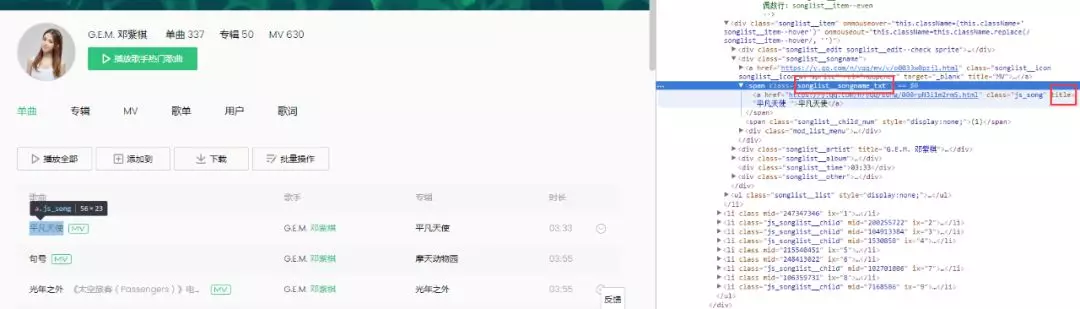
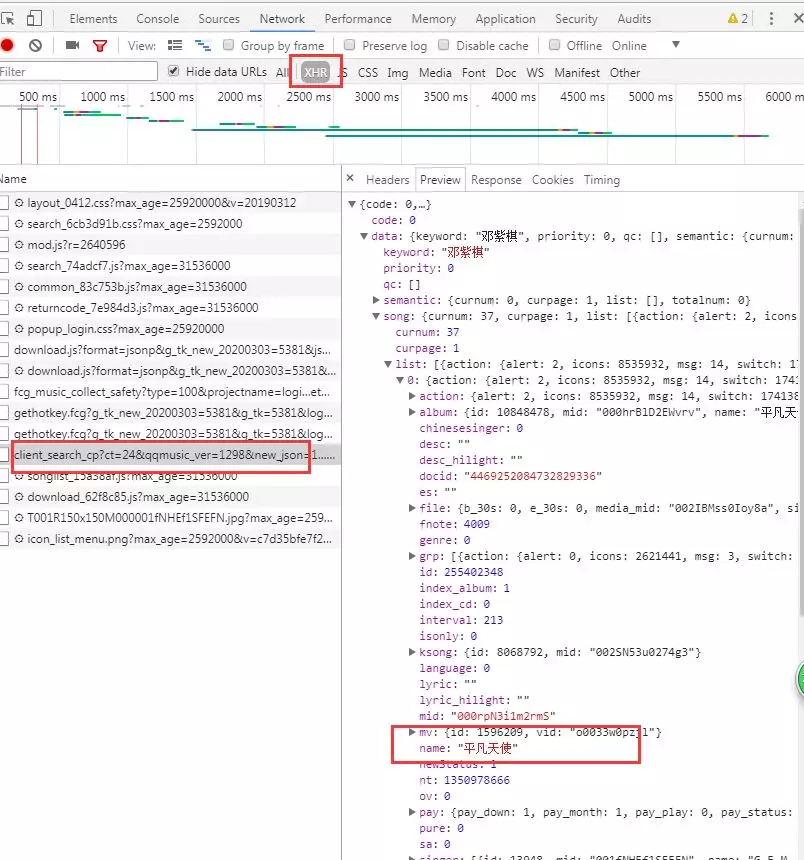
5.分析网页源代码 Elements,发现无歌曲信息,无法使用 BeautifulSoup,如下图所示,结果为空。
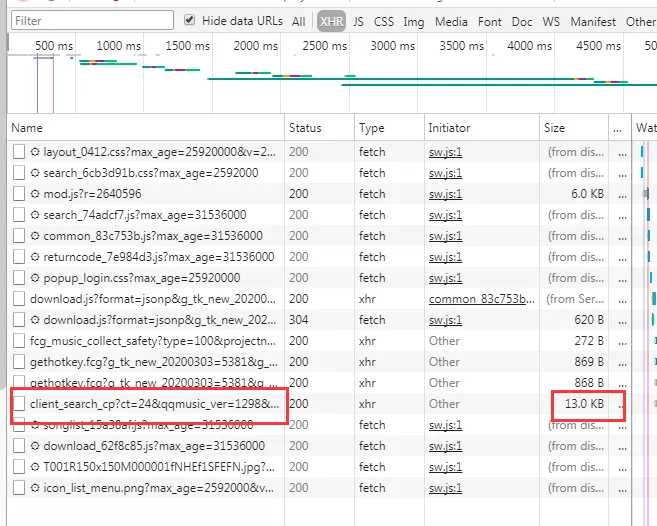
6.点击 Network,看数据在不在 XHR(无刷新更新页
面),我的经验是先看 Size 最大的,然后分析 Name,
查看 Preview,果然在里面!
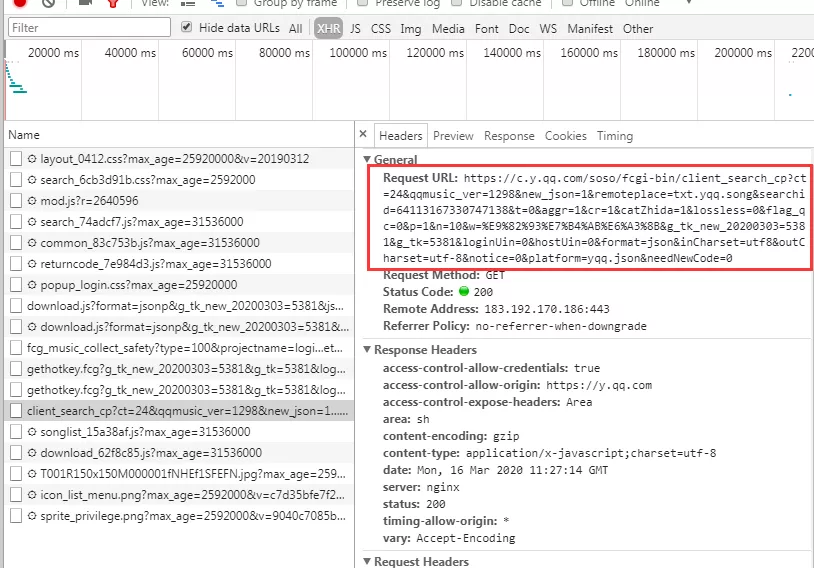
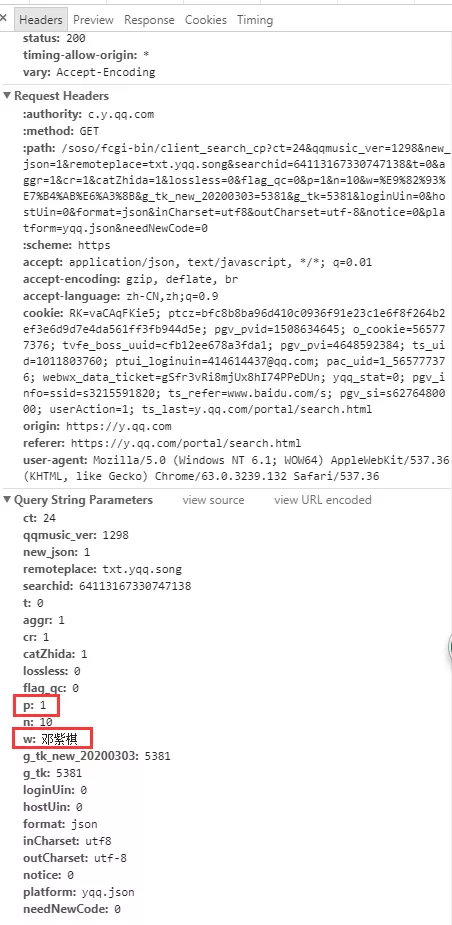
7.点击 Headers,拿到相关参数。如下图,仔细观察
url 与 Query String Parameters 参数的关系,发现
url 中的 w 代表歌手名,p 代表页数。
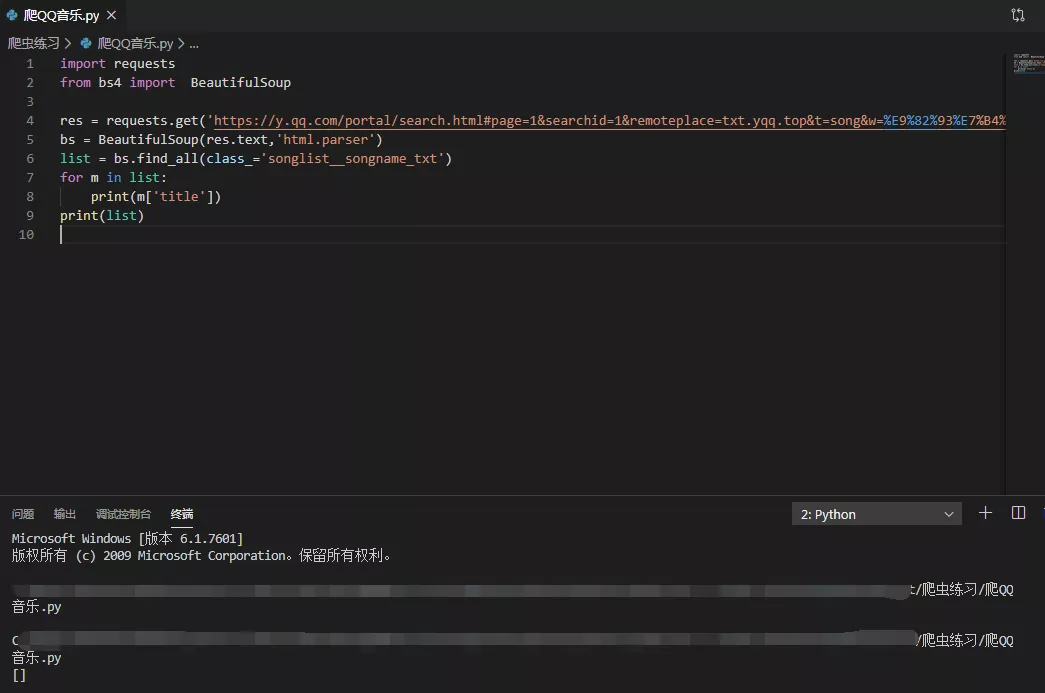
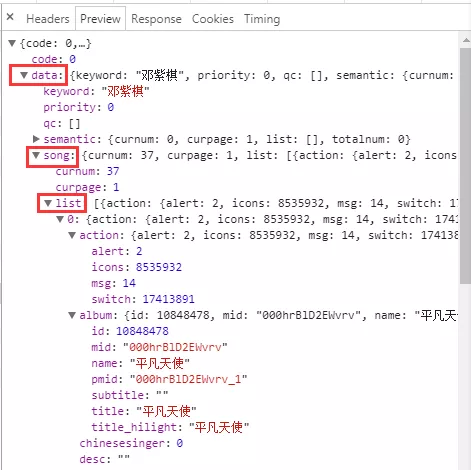
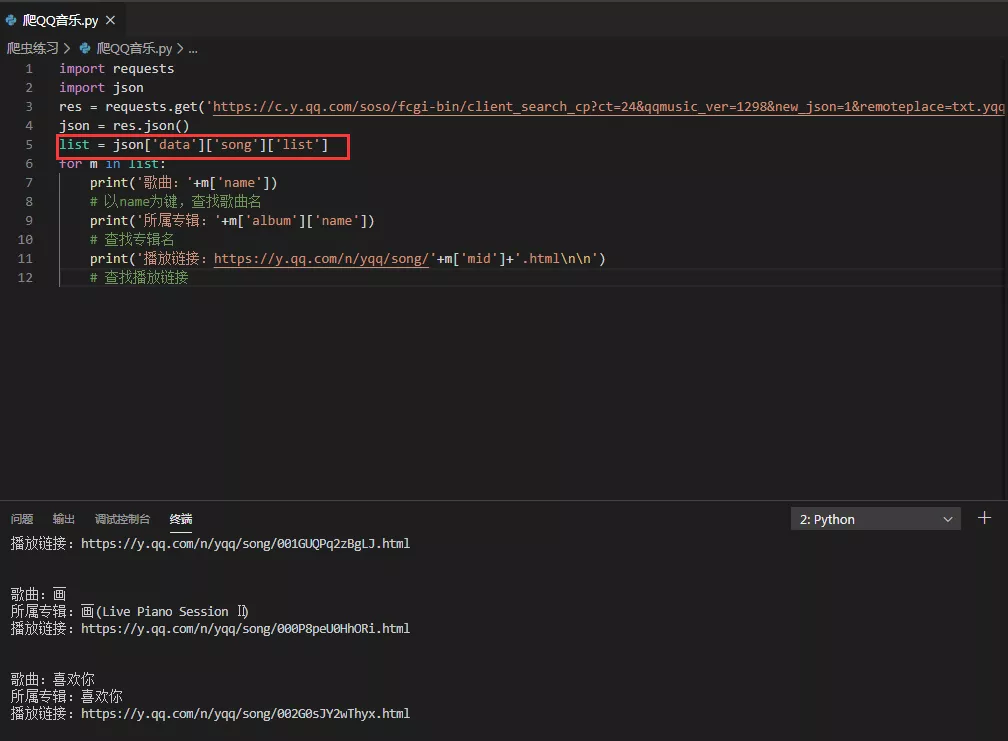
8.通过 json 代码实现,首先小试牛刀,爬取第一页
的数据,url 直接复制过来。成功!
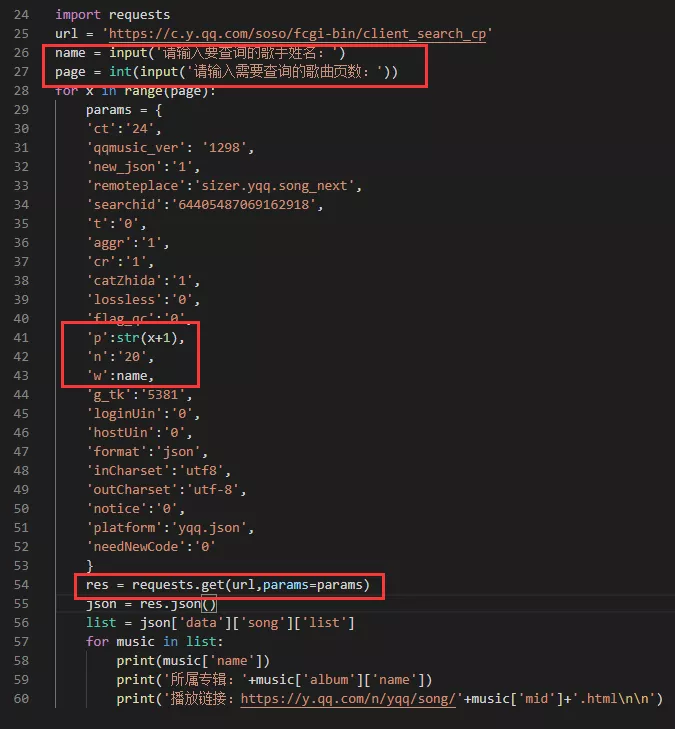
9.引入 params 参数,实现指定歌手、指定页数的查询。
注意代码url为上一步url中“?”之前的部分, params两边的参数都需要加 ’’,requests.get 添加 params,参数(也可顺便添加 headers 参数)
- 添加存储功能,保存到本地(Excel)。也可保存为 csv 格式或存入数据库,操作类似。


【四、总结】
1.爬取 QQ 音乐比爬取豆瓣等网站稍难,所需信息不在网页源代码,需查看 XHR;
2.通过 XHR 爬取数据一般要使用 json,格式为:
res = requests.get(url)
json = res.json()
list = json[‘’][‘’]…
3.仅供练手参考,不建议爬取太多数据,给服务器增大负载;
4.Python 爬取 QQ 音乐数据(二)将为大家带来如何爬取指定歌曲的歌词及评论(selenium),并生成词云图(wordcloud),敬请期待。
5.需要本文源码的话,请在公众号后台回复“QQ音乐”四个字进行获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/