字符串是开发中使用常见最多的类型,本章主要讲一些相关的骚操作
字符串(string)
初识字符串
这里太过基础,可忽略这部分内容
字符串这玩意,我们永远都不陌生。初入编程殿堂,必逃不过"hello world"的洗礼。放在""双引号中的一串字符就是字符串。
在go中,字符串的声明方式有如下是那种
str := "hi jochen" // 1
var str = "hi jochen" // 2
var str string = "hi jochen" //3
在Go中当声明了一个字符串,但没有赋值的时候,该字符串的默认值是一个空字符串"",在某些语言中如c#,字符串的默认值是null
可以给某个变量,赋予不同的string值,但是string本身是不可变的,这在很多语言都是如此。
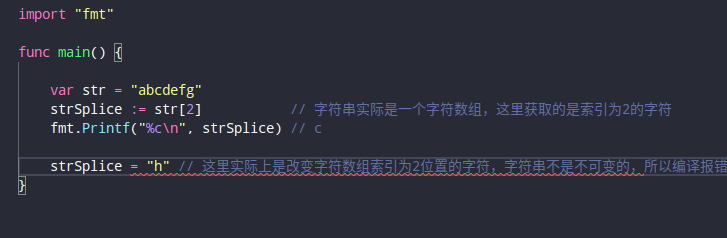
字符串的字面值(string literal)
所谓字面值就是平时我们定义变量等号右边能直观看到的值得,如"hi jochen"
字面值可以包含转义符号,如常见的
等带反斜杠的字符
有时候我们想得到"
"这个字符串,而不是换行符(
转义字符的含义),此时我们可以使用反单引号(不知道是不是这样叫,就是Esc下面那个键) ` 代替 双引号",此时该字符串字面值就叫做原始字符串字面值,如:
var str = `hi jochen
` // 此时字符串就是hi jochen
var str = "hi jochen
" // 此时字符串是hi jochen 打印或显示的时候会换行
原始字符串在我们编写文件路径字符串的时候是十分有用的
字符编码
常见的字符编码有ASCII、Unicode、Utf-8等,字符编码就如字面含义,就是为每个字符分配一个特定的数值与之对应。
-
byte
- 编码有时候我们会用到二进制数,对于表示二进制数,我们一般用
byte类型,其本质是uint8类型 - 对于ASCII定义的英语字符,可以使用byte来表示
- 编码有时候我们会用到二进制数,对于表示二进制数,我们一般用
-
Unicode
- Unicode为超过100万个字符分配类相应的数值,这个数叫做
code point,如65代表A - 为了表示Unicode的数值,Go提供了
rune类型,它实际上是int32类型的别名 - 单个字符使用''单引号框起来,如果没有显示的指定字符类型的话,其默认是
rune类型,如var cha = 'a'
- Unicode为超过100万个字符分配类相应的数值,这个数叫做
-
Utf-8
- Go中字符串是用utf-8编码的,utf-8是Unicode code point的几种编码之一
- utf-8是高效可变长度的编码,code point可以是8、16、32位
- 通过可变长度编码,utf-8从ascii的转化变得更加的直接,因为而者对应的字符完全相同
ps:当我们打印rune类型的时候,如果使用格式化%v输出会是code point,如果想输出字符我们应该使用%c(任何整数类型实际上都可以使用%c打印字符,但是使用rune可以明显的表达你的意图)
类型别名
向上述 runes<=>int32 byte<=>uint8 这样可以互换使用的类型,我们就称它们互为类型别名
我们也可以自定义类型别名
语法为:type byte = uint8
拓展:
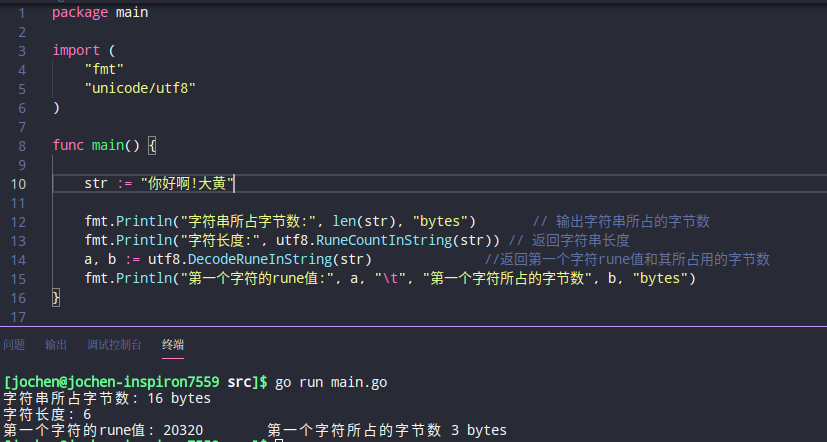
获取字符长度:
-
len()用于获取字符串的字节数,即所占的byte数。为什么不能认为是字符串长度呢,上面说到,go默认字符串采用的可变长utf-8编码,所以并非所有字符都占用一个字节
go中有许多内置函数,内置函数是不需要improt的 -
如何准确计算字符串长度呢?
使用utf-8包,里面提供了按rune计算字符串长度的方法
RuneCountIntString()方法可以按rune获取字符串长度,即我们所需要的表面长度DecondeRunelnString()函数返回两个值,第一个字符的code point ,以及该字符所占的字节数
-
range关键字可以遍历各种集合,字符串实际上就是字符集合,也是可以遍历的,其返回两个值,一是集合的索引,二是索引对应的集合元素str := "abcdef" for i, c := range str{ fmt.Printf("%v %c ", i, c) // i为索引值,c为遍历字符 注意字符串的索引默认是按照字符所占的byte去走的 } // 如果索引不要的话可以使用弃元标识符 // for _, c:= range str