
AI创作莎士比亚风格的作品 训练一个循环神经网络模仿莎士比亚
FLORIZEL:
Should she kneel be?
In shall not weep received; unleased me
And unrespective greeting than dwell in, thee,
look’d on me, son in heavenly properly.
这是谁写的,莎士比亚还是机器学习模型?
答案是后者!上面这篇文章是一个经过TensorFlow训练的循环神经网络的产物,经过30个epoch的训练,并给出了一颗“FLORIZEL:”的种子。在本文中,我将解释并给出如何训练神经网络来编写莎士比亚戏剧或任何您希望它编写的东西的代码!
导入和数据
首先导入一些基本库
import tensorflow as tf
import numpy as np
import os
import timeTensorFlow内置了莎士比亚作品。如果您在像Kaggle这样的在线环境中工作,请确保连接了互联网。
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
数据需要用utf-8进行解码。
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# length of text is the number of characters in it
print ('Length of text: {} characters'.format(len(text))) [输出]:
Length of text: 1115394 characters
它里面有很多的数据可以用!
我们看看前250个字符是什么
print(text[:250])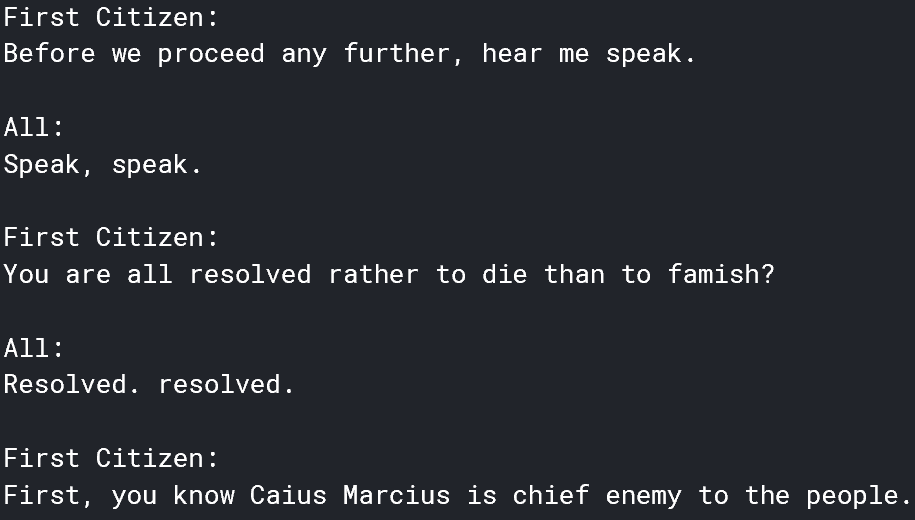
向量化
首先看看文件里面有多少不同的字符:
vocab = sorted(set(text))
print ('{} unique characters'.format(len(vocab)))[输出]:
65 unique characters
在训练之前,字符串需要映射到数字表示。
下面创建两个表—一个表将字符映射到数字,另一个表将数字映射到字符。
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])查看向量字典:
print('{')
for char,_ in zip(char2idx, range(20)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...
}')[输出]:
{
'
': 0,
' ' : 1,
'!' : 2,
'$' : 3,
'&' : 4,
"'" : 5,
',' : 6,
'-' : 7,
'.' : 8,
'3' : 9,
':' : 10,
...
}
每一个不一样的字符都有了编号。
我们看看向量生成器如何处理作品的前两个单词 'First Citizen'
print ('{} ---- characters mapped to int ---- > {}'.format(repr(text[:13]), text_as_int[:13]))
这些单词被转换成一个数字向量,这个向量可以很容易地通过整数到字符字典转换回文本。
制造训练数据
给定一个字符序列,该模型将理想地找到最有可能的下一个字符。
文本将被分成几个句子,每个输入句子将包含文本中的一个可变的seq_length字符。
任何输入语句的输出都将是输入语句,向右移动一个字符。
例如,给定一个输入“Hell”,输出将是“ello”,从而形成单词“Hello”。
首先,我们可以使用tensorflow的.from_tensor_slices函数将文本向量转换为字符索引。
# The maximum length sentence we want for a single input in characters
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
# Create training examples / targets
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
for i in char_dataset.take(5):
print(idx2char[i.numpy()])[输出]:
F
i
r
s
t
批处理方法允许这些单个字符成为确定大小的序列,形成段落片段。
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
for item in sequences.take(5):
print(repr(''.join(idx2char[item.numpy()])))[输出]:
'First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You ' 'are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you k' "now Caius Marcius is chief enemy to the people. All: We know't, we know't. First Citizen: Let us ki" "ll him, and we'll have corn at our own price. Is't a verdict? All: No more talking on't; let it be d" 'one: away, away! Second Citizen: One word, good citizens. First Citizen: We are accounted poor citi'
对于每个序列,我们将复制它并使用map方法移动它以形成一个输入和一个目标。
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)现在,数据集已经变成了我们想要的输入和输出。
Input data: 'First Citizen:
Before we proceed any further, hear me speak.
All:
Speak, speak.
First Citizen:
You'
Target data: 'irst Citizen:
Before we proceed any further, hear me speak.
All:
Speak, speak.
First Citizen:
You '对向量的每个索引进行一次性处理;对于第0步的输入,模型接收“F”的数值索引,并尝试预测“i”作为下一个字符。在下一个时序步骤中,它做同样的事情,但是RNN不仅考虑前面的步骤,而且还考虑它刚才预测的字符。
for i, (input_idx, target_idx) in enumerate(zip(input_example[:5], target_example[:5])):
print("Step {:4d}".format(i))
print(" input: {} ({:s})".format(input_idx, repr(idx2char[input_idx])))
print(" expected output: {} ({:s})".format(target_idx, repr(idx2char[target_idx])))[输出]:
Step 0
input: 18 ('F')
expected output: 47 ('i')
Step 1
input: 47 ('i')
expected output: 56 ('r')
Step 2
input: 56 ('r')
expected output: 57 ('s')
Step 3
input: 57 ('s')
expected output: 58 ('t')
Step 4
input: 58 ('t')
expected output: 1 (' ')
Tensorflow的 tf.data 可以用来将文本分割成更易于管理的序列——但首先,需要将数据打乱并打包成批。
# Batch size
BATCH_SIZE = 64
# Buffer size to shuffle the dataset
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
dataset[输出]:
<BatchDataset shapes: ((64, 100), (64, 100)), types: (tf.int64, tf.int64)>
构建模型
最后,我们可以构建模型。让我们先设定一些重要的变量:
# Length of the vocabulary in chars
vocab_size = len(vocab)
# The embedding dimension
embedding_dim = 256
# Number of RNN units
rnn_units = 1024模型将有一个嵌入层或输入层,该层将每个字符的数量映射到一个具有变量embedding_dim维数的向量。它将有一个GRU层(可以用LSTM层代替),大小为units = rnn_units。最后,输出层将是一个标准的全连接层,带有vocab_size输出。
下面的函数帮助我们快速而清晰地创建一个模型。
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None]),
tf.keras.layers.GRU(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
return model通过调用函数组合模型架构。
model = build_model(
vocab_size = len(vocab),
embedding_dim=embedding_dim,
rnn_units=rnn_units,
batch_size=BATCH_SIZE)让我们总结一下我们的模型,看看有多少参数。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (64, None, 256) 16640
_________________________________________________________________
gru (GRU) (64, None, 1024) 3938304
_________________________________________________________________
dense (Dense) (64, None, 65) 66625
=================================================================
Total params: 4,021,569
Trainable params: 4,021,569
Non-trainable params: 0
_________________________________________________________________400万的参数!我们希望把它训练的久一点。
汇集
这个问题现在可以作为一个分类问题来处理。
给定先前的RNN状态和时间步长的输入,预测表示下一个字符的类。
因此,我们将附加一个稀疏分类熵损失函数和Adam优化器。
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
example_batch_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("scalar_loss: ", example_batch_loss.numpy().mean())
model.compile(optimizer='adam', loss=loss)[输出]:
Prediction shape: (64, 100, 65) # (batch_size, sequence_length, vocab_size)
scalar_loss: 4.1746616
配置检查点
模型训练,尤其是像莎士比亚戏剧这样的大型数据集,需要很长时间。理想情况下,我们不会为了做出预测而反复训练它。tf.keras.callbacks.ModelCheckpoint函数可以在训练期间将某些检查点的权重保存到一个文件中,该文件可以在一个空白模型被后续检索。这在训练因任何原因中断时也很方便。
# Directory where the checkpoints will be saved
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)最后,执行训练
EPOCHS=30
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])这应该需要大约6个小时的时间来获得不那么令人印象深刻但更快的结果,epochs可以调整到10(任何小于5的都会完全变成垃圾)。
生成文本
冲检查点中恢复权重参数
tf.train.latest_checkpoint(checkpoint_dir)用这些权重参数我们可以重新构建模型:
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size=1)
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))生成文本的步骤:
- 首先选择一个种子字符串,初始化RNN状态,并设置要生成的字符数。
- 使用开始字符串和RNN状态获得下一个字符的预测分布。
- 使用分类分布计算预测字符的索引,并将其作为模型的下一个输入。
- 模型返回的RNN状态被反馈回自身。
- 重复步骤2和步骤4,直到生成文本。
def generate_text(model, start_string):
# Evaluation step (generating text using the learned model)
# Number of characters to generate
num_generate = 1000
# Converting our start string to numbers (vectorizing)
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
# Empty string to store our results
text_generated = []
# Low temperatures results in more predictable text.
# Higher temperatures results in more surprising text.
# Experiment to find the best setting.
temperature = 1.0
# Here batch size == 1
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
# remove the batch dimension
predictions = tf.squeeze(predictions, 0)
# using a categorical distribution to predict the character returned by the model
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# We pass the predicted character as the next input to the model
# along with the previous hidden state
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))最后,给定一个开始字符串,我们可以生成一些有趣的文本。
现在,欣赏一下两个RNN的剧本吧,一个是训练了10个epochs,另一个是30个epochs。
这是训练了10个epochs的
print(generate_text(model, start_string=u"ROMEO: "))ROMEO: how I, away too put That you shall have thieffort, are but love.
JULIET: Go, fight, sir: we say ‘Ay,’ and alack to stand and not to go to; And washt us him to-domm. Ay, my ows young; a man hear from his monsher to thee.
KING RICHARD III: Come, cease. O broteld the costime’s deforment! Thou wilt was quite.
PAULINA: I would you say the hour! Ah, hole for your company: But, good my lord; we have a king, of peace?
BALTHASAR: Cadul and washee could he ha! To curit her I may wench.
GLOUCESTER: Had you here shall such a pierce to temper; Or might his noble offery owe and speed Which seemest thy trims in a weaky amidude By this to the dother, dods citizens.
Third Citizen:
Madam sweet give reward, rebeire them With news gone! Pluck yielding: ’tis sign out things Within risess in strifes all ten times, To dish his finmers for briefily.
JULIET:
Gentlemen, God eveI come approbouting his wife as it, — triumphrous night change you gods, thou goest:
To which will dispersed and France.
哇!仅仅在10个epochs之后,就有了令人印象深刻的理解。这些词的拼写准确性令人怀疑,但其中有明显的情节冲突。写作肯定可以改进。希望30-epoch模型能有更好的表现。
这是训练了30个epochs的
欣赏一下完全由RNN一个字一个字地创作出来的作品吧!
BRUTUS:
Could you be atherveshed him, our two,
But much a tale lendly fear;
For which we in thy shade of Naples.
Here’s no increase False to’t, offorit is the war of white give again.
This is the queen, whose vanoar’s head is worthly.
But cere it be a witch, some comfort.
What, nurse, I say!
Go Hamell.
FLORIZEL:
Should she kneel be?
In shall not weep received; unleased me
And unrespective greeting than dwell in, thee,
look’d on me, son in heavenly properly,
That ever you are my father is but straing;
Unless you would repossess him, hath always louded up,
You provokest. Good faith, o’erlar I can repart the heavens like deeds dills
For temper as soon as another maiden here, and he is bann’d upon which springs;
O’er most upon your voysus, I have no thunder; and my good villain!
Alest each other’s sleepings.
A fool; if this business prating duty
Does these traitors other sorrow.
LUCENTIO:
Tell me, they’s honourably.
Shepherd:
I know, my lord, to London, and you my moved join under him,
Great Apollo’s stan to make a book,
Both yet my father away towards Covent. Tut, And thou still’d by the earthmen lord r sensible your mother?
Servant:
Go, vill! We muster yet, for you’ll not: you are took good mad within your company in rage, I would you fight it so, his eye for every days,
To swear the beam of such a detects,
To Clarence dead to call upon you all I thank your grace, my father and my father, and yourself prevails
My father, hath a sword for hither;
Nor when thy heart is grown grave done.
QUEEN MARGARET: *
*Thou art a lodging very good and give thanks
With him.
But There is now in hand:
Therefore it be possish’d with Romeo dead.
MENENIUS:
Ha! little very welcome to my daughter’s sword,
Which haply my prayer’s legs, such as he does.
I am banks, sir, I’ll make you say ‘nough; for hither so better now to be so, sent it: it is stranger.
哇!有趣的是,这个模型甚至学会了在某些情况下押韵(特别是Florizel的台词)。想象一下,在50甚至100个epochs之后,RNN能写些什么!
嗯,我猜想AI会让作家失业
不完全是这样——但我可以想象未来人工智能会发表大量设计成病毒式传播的文章。这是一个挑战——收集与主题相关的顶级文章,比如Human Parts或其他类似出版物的文章,然后训练人工智能撰写热门文章。发布RNN的输出,逐字地,看看效果如何!注意——我不建议在更专业的出版物上训练RNN,比如Towards Data Science 或 Better Programming,因为它需要RNN在合理的时间内无法学习的技术知识。然而,在RNN目前的能力范围内,更多的哲学和非技术的写作还行。
随着文本生成变得越来越先进,它将有潜力比人类写得更好,因为它有一个眼睛,什么内容将像病毒一样,什么措辞让读者感觉良好,等等。令人震惊的是,有一天,机器可以在人类最擅长的事情——写作上击败人类。诚然,它无法真正理解自己在写什么,但它会掌握人类的交流方式。
我想如果你不能打败他们,那就加入他们吧!
原文地址:https://imba.deephub.ai/p/051053806a5211ea90cd05de3860c663
