我们都讨厌对文章进行冗长而毫无意义的介绍所以我就直奔主题了。2021年还有10天就过去了, 以下是我认为 2021 年最有趣、最有前途的深度学习论文。
本篇文章的目的是简单地解释它们,并结合非常简单/复杂的冗长文字,这样可以让本文对初学者和有知识的人同时都有一定的帮助。
说明:本文的主题的选择是个人的并且非常有偏见,它们将涵盖更多的计算机视觉主题,而NLP,GANs会比较少,后面我们还会梳理更多论文的推荐文章。
CLIP
视觉+语言的多模态学习变得流行的原因就是这篇 OpenAI 论文,它可以更轻松地扩展图像识别任务,因为它不需要耗时的手动标记。它可以从原始文本中学习而不需要手动确定标签,并且在几个著名的数据集中获得了最先进的结果。
这是一个新的学习概念吗?不是,但它是迄今为止最有“野心的”的。OpenAI收集了一个包含 4 亿个图像+文本对的数据集来训练这个模型:对于文本编码使用修改后的 Transformer 架构,对于图像编码使用 ResNet-50、ResNet-101、EfficientNet 和 Vision Transformers(均已修改)。通过对比测试表现最好的是 Vision Transformer ViT-L/14。
它是如何工作的?理论非常的简单:对比学习(Contrastive Learning),一种众所周知的zeroshot和自监督学习技术。给定一对带有文本描述的图像,将它们的特征靠的近一些。如果给定一对文本描述错误的图像,将它们的特征拉远。这样在用句子查询图像时,越接近的就是“更正确”的。
带有 N 个文本描述的 N 个图像分别使用图像和文本编码器进行编码,以便将它们映射到较低维的特征空间。接下来使用另一个映射,从这些特征空间到混合特征空间的简单线性投影映射称为多模态嵌入空间,通过余弦相似度(越接近越相似)使用正+负的对比学习对它们进行比较。
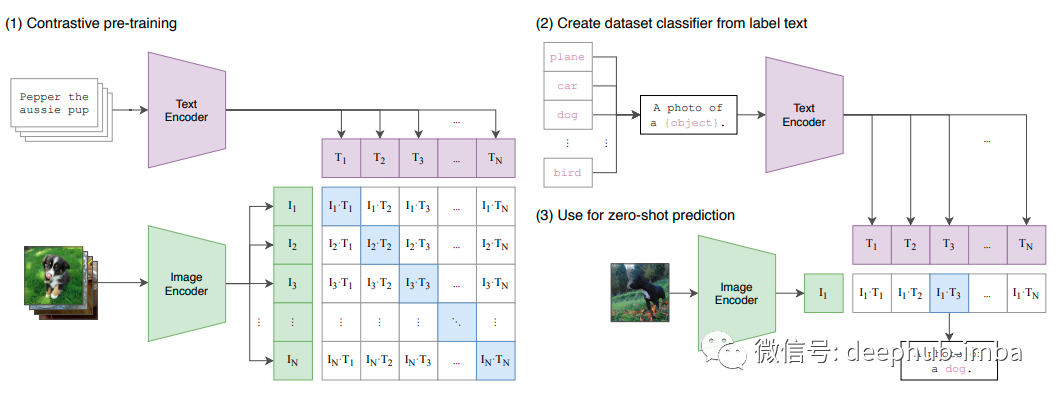
CLIP 能够解决多个文本表示同一图像的问题(即多义性),并且在一些最著名的数据集(如 ImageNet、CIFAR 和 Pascal VOC)上的表现优于最先进的模型。此外由于它使用对比学习所以它是一个zeroshot的学习器,可以比以前的模型更好地泛化到未出现的类别。
扩散模型(Diffusion Models)
我讨厌 GAN的主要原因是它学习非常不稳定,需要花费大量时间进行微调,尤其是英伟达在 GitHub 中实现的 StyleGAN 。如果你也跟我的想法一样,那么GANs不再是图像生成和翻译的最先进的技术,这个你会相信吗?替换掉GANs的是 VQ-VAE 吗?基于流的生成模型Generative flows?都不是。

完整文章: