cuda shared memory读写带宽大于global memory(10倍以上),读写延时低(20~30倍),例如cuda parllel reduction的例子就先将数据从global memory搬运至shared memory,然后再做运算,从而提高程序性能.
为了提高读写带宽,cuda将shared memory按照4字节或8字节(默认4字节,可以设置为8字节)被划分到32个bank中,每个bank的内存能同时读写,但是同一个bank的不同地址的数据则只能串行读写(如果是同一个地址则进行broadcast,不会出现冲突),因此当同一个warp的线程去访问shared memory数据时,如果有两个以上线程访问了同一个bank的不同地址的数据,就会影响程序的性能.例如__shared__ float data[32][32],申请了1024个float数据,每个float正好是4字节,data按行存储,data[0][0]就位于第0个bank,data[0][1]位于第一个bank,以此类推.因此data[row][col]就被划分在了第col个bank中,即列数相同的数据划分至了同一个bank中.如果一个warp的线程按列处理data那么就会造成bank conflict.
查看cuda bank size函数为:cudaDeviceGetSharedMemConfig(cudaSharedMemConfig* pConfig),结果存储在pConfig中,是个枚举,如下图所示.
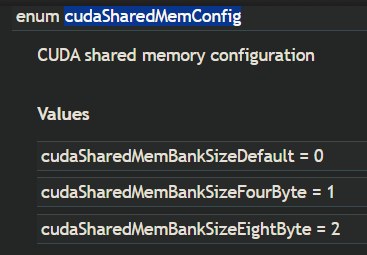
通过cudaDeviceSetSharedMemConfig(cudaSharedMemConfig config),可以设置bank size,计算能力3以上的支持8字节的bank size.
验证程序:
#include<stdio.h> #include<time.h> #define WARPSIZE 32 __global__ void kernel1(float* A) { __shared__ float data[32][32]; int tid = threadIdx.x; int col = tid/WARPSIZE; int row = tid%WARPSIZE; data[row][col] = 100.f; A[tid] = data[row][col]; } __global__ void kernel2(float* A) { __shared__ float data[32][32]; int tid = threadIdx.x; int row = tid/WARPSIZE; int col = tid%WARPSIZE; data[row][col] = 100.f; A[tid] = data[row][col]; } __global__ void warmup(float* A) { __shared__ float data[32][32]; int tid = threadIdx.x; int col = tid/WARPSIZE; int row = tid%WARPSIZE; data[row][col] = 100.f; A[tid] = data[row][col]; } void checkValue(float* A, int len, int val = 100.f) { for(int i = 0; i < len; i++) { if(A[i] != val) { printf("Error accured"); } } } int main() { clock_t start, end; int blocksize = 32*32; float* h_A = (float*)malloc(sizeof(float)*blocksize); float* d_A; cudaMalloc(&d_A, sizeof(float)*blocksize); start = clock(); warmup<<<1, blocksize>>>(d_A); cudaDeviceSynchronize(); end = clock(); printf("warmup : %f ",(double)(end - start) / CLOCKS_PER_SEC); cudaMemcpy(h_A, d_A, blocksize*sizeof(float), cudaMemcpyDeviceToHost); checkValue(h_A, blocksize); start = clock(); kernel1<<<1, blocksize>>>(d_A); cudaDeviceSynchronize(); end = clock(); printf("kernel1: %f ",(double)(end - start) / CLOCKS_PER_SEC); cudaMemcpy(h_A, d_A, blocksize*sizeof(float), cudaMemcpyDeviceToHost); checkValue(h_A, blocksize); start = clock(); kernel2<<<1, blocksize>>>(d_A); cudaDeviceSynchronize(); end = clock(); printf("kernel2: %f ",(double)(end - start) / CLOCKS_PER_SEC); cudaMemcpy(h_A, d_A, blocksize*sizeof(float), cudaMemcpyDeviceToHost); checkValue(h_A, blocksize); cudaFree(d_A); free(h_A); return 0; }
kernel1按照列访问shared memory,kernel2按照行访问,按照bank conflict的理论,kernel1会产生bank conflict,虽然结果是相同的,但性能必然不如kernel2.
编译程序:(内存:64G,CPU:12核(24线程),OS:ubuntu16.04 ,Env:1080ti + cuda10.0)(较好的配置)
nvcc -O3 bankconflict.cu -o bankconflict
运行程序:
./bankconflict
结果如下:
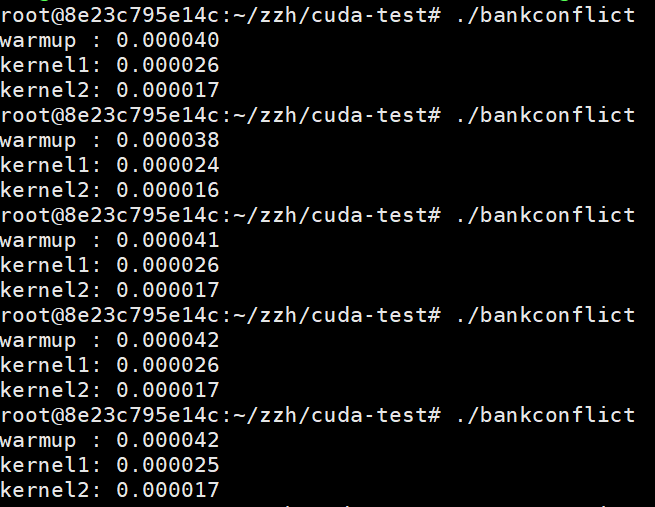
注:通常来说通过记录CPU的时间也能反应kernel函数的执行时间,但是如果kernel时间较接近很有可能测不出来准确时间(经过我的测试发现,这个CPU时间在性能好的服务器上一般准一些,在差一点的机器上就会很明显出现时间不准确,比如垃圾游戏本...). 所以一般使用nvprof确定kernel真实的执行时间;另外第一次启动kernel函数时,会有初始化cuda上下文等操作,CPU记录的时间会比后面的kernel费时,因此第一次只能算warmup,不参与时间比较,如果使用nvprof就不存在这个问题了;warmup和kernel1完全相同,起不同的名字是因为nvprof按名字区分不同的kernel函数,如果一个kernel调多次,那么显示kernel运行的时间是叠加在一起的,这样就不好确定是否初次执行更耗时(首次是否耗时与kernel有关<试试就知道了).
执行:
nvprof ./bankconflict
结果如下:
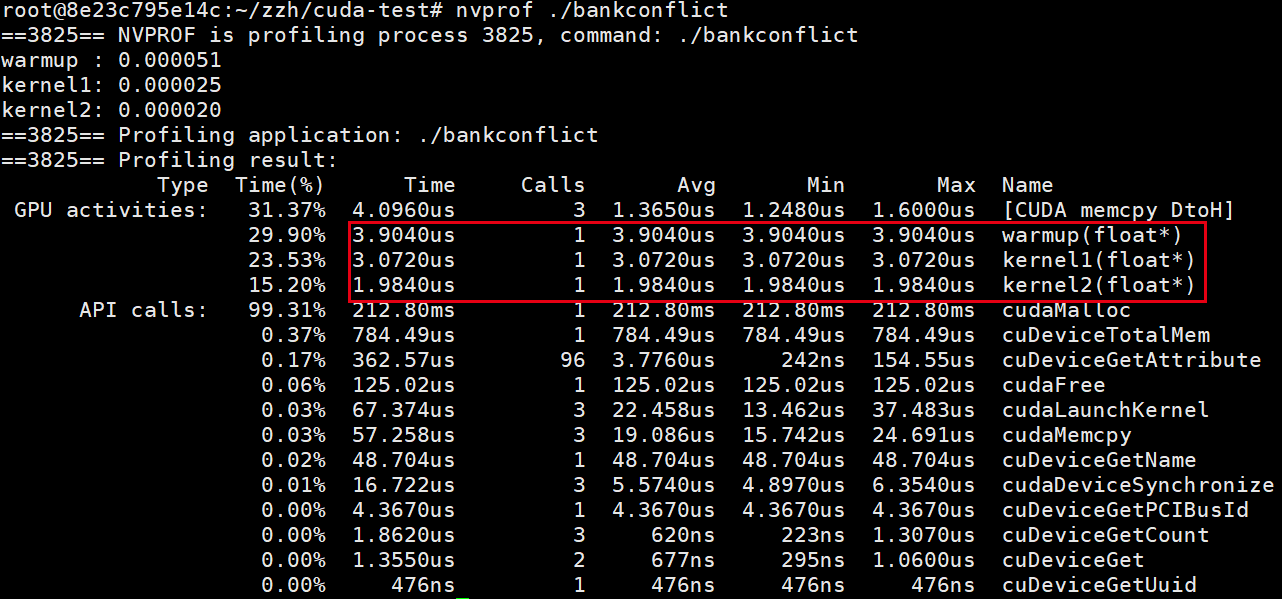
可以明显看出kernel2的执行速度比kernel1快了很多.
另外,使用nvprof还能分析程序发生bank conflict的次数,执行:
nvprof --events shared_ld_bank_conflict,shared_st_bank_conflict ./bankcon
注:docker内执行nvprof --events或者--metrics时,要在启动docker时使用--privileged选项,赋予特权,或者在配置好环境的host(不用docker)上使用root用户执行,否则会报Internal Error,原因是使用--events或者--metrics时貌似要生成分析文件,没有权限就生成不了...
结果如下:
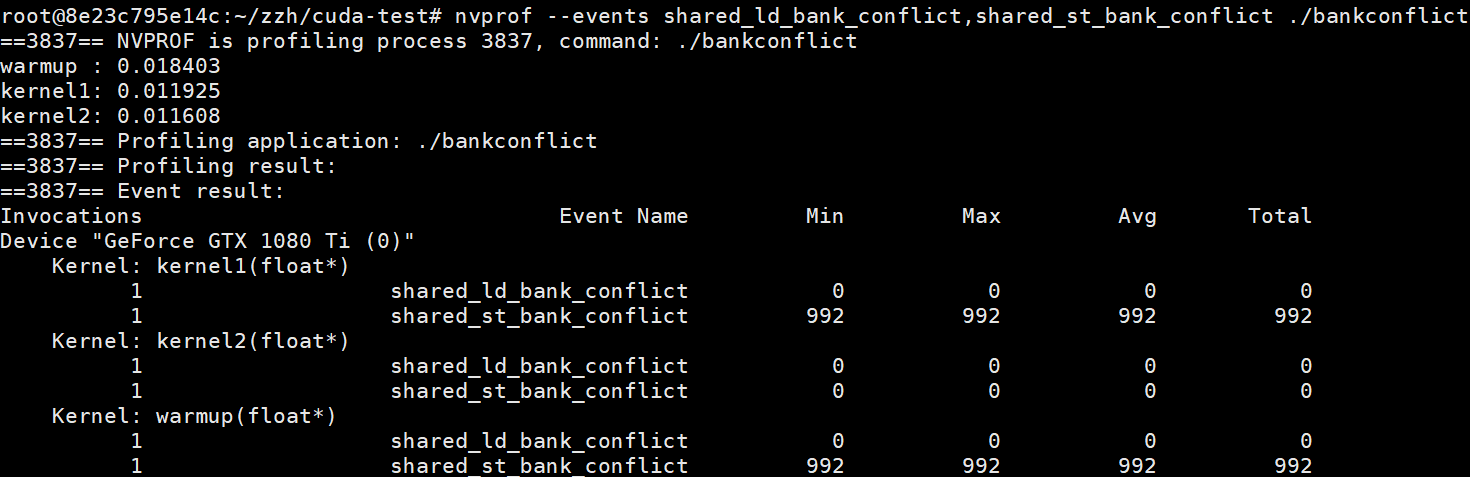
其中shared_ld_bank_conflict是load bank conflict次数,shared_st_bank_conflict是store bank conflict次数.
可以看出kernel1有992次的store bank conflict,992 = 31*32,正好符合预期.
这里还有一个问题:kernel1最后执行了A[tid] = data[row][col],按道理来说应该也存在load bank conflict.但是为什么使用nvprof显示的结果却没有呢?原因是我们编译的时候使用了-O3编译优化,编译器优化了我们的程序,减少了bank conflict的次数.可以通过禁止编译优化来观察结果,重新编译:
nvcc -g -G bankconflict.cu -o bankconflict
然后再通过上面的命令分析bank conflict情况,结果如下:
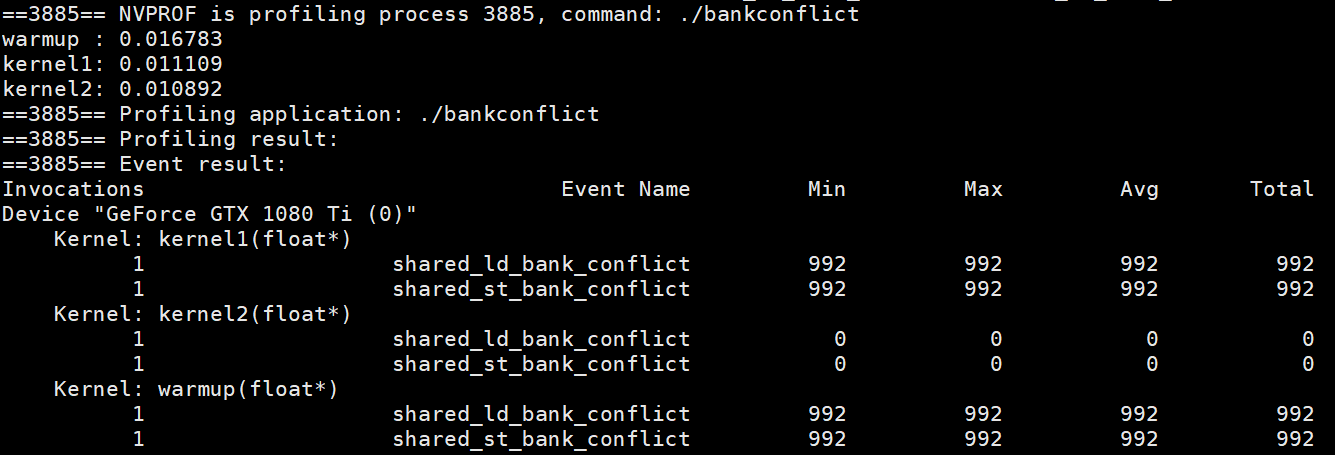
可以看到这时kernel1也存在992次的load bank conflict.
如何避免bank conflict?
《Professional CUDA C Programming》中给出了一种memory padding的小技巧,这篇文章有对应的示例:https://blog.csdn.net/kebu12345678/article/details/82982579,将shared memory大小设置为[32][7]可以避免访问首元素时出现bank conflict(浪费了空间换取不冲突),当数组列数是奇数时,以7为例,首元素的bank位置为bankpos=(tid*7)%32,当tid从0取到31时,bankpos的值也正好从0取到31,可以写个程序测一下或者使用反证法可以证明bankpos没有重复的元素:假设有两个相同bankpos,tid分别为t1,t2,那么(t1-t2)*7必定是32的倍数,32不含7这个因子,所以这显然是不可能的.
参考文档:
1.https://blog.csdn.net/kebu12345678/article/details/82982579
2.《Professional CUDA C Programming》->chapter 5