原文地址:http://kerrigan.sinaapp.com/post-7.html
Linux System and Performance Monitoring
http://www.houstondad.com/papers/oscon2009-linux-monitoring.pdf
Darren Hoch
译:Roger
这是[叔度]给我的一篇非常不错的关于Linux性能监控的文档,可惜是英文的,网上只能找到些中文节选,并不完整。
准备花些时间将原文共43页认真学习一下,顺便翻译分享给大家。当然,还是推荐阅读英文文档,要么使用google翻译,最后再考虑读这篇。:)
Linux系统与性能监控
目录
- 1. 性能监控介绍
- 确定应用类
- 确定统计基线
- 2. 安装监控工具
- 3. CPU介绍
- 上下文切换
- 运行队列
- CPU使用率
- 4. CPU性能监控
- 使用vmstat工具
- 案例学习:持续的CPU使用率
- 案例学习:超负荷的调度程序
- 使用mpstat工具
- 案例学习:未充分使用的处理器负载
- 总结
- 5. 虚拟内存介绍
- 虚拟内存分页
- 内核内存分页调度
- 页框回收算法
- kswapd
- 通过pdflush内核分页调度
- 案例学习:大的入站I/O
- 总结
- 6. I/O监控介绍
- 读和写 - 内存分页
- 主和辅页错误
- 文件缓冲区缓存
- 内存分页类型
- 数据页写回磁盘
- 7. I/O监控
- 计算每秒的I/O
- 随机vs顺序I/O
- 当虚拟内存杀掉I/O
- 总结
- 8. 网络监控介绍
- 以太网配置
- 监控网络吞吐量
- 连接统计tcptrace
- 总结
- 9. 附录:一步一步开始性能监控 - 案例学习
- 性能分析的步骤
- 性能跟踪
- 10. 参考文献
性能监控介绍
性能优化是找到并消除系统瓶颈的过程。很多系统管理员觉得性能优化能通过学习一本“cookbook”实现,也就是说设置一些内核参数就能简单地解决问题。事实上并不是这样。性能优化实际上是为了在操作系统下的不同子系统之间获得平衡。这些子系统包括:
-
- CPU
- Memory
- IO
- Network
这些子系统相互之间高度依赖。任何一个子系统的高负载都会引起其它子系统出现问题。例如:
-
- 大量的页调入请求对内存造成阻塞
- 网卡的大吞吐量造成CPU开销
- CPU开销造成内存请求队列
- 大量从内存来的磁盘写请求造成CPU和IO通道的开销
为了优化系统,我们必须定位瓶颈在哪。即使问题看起来像是某个子系统引起,也有可能是因为其它子系统高负载导致。
确定应用类型
为了明白从哪里开始优化瓶颈,首要工作就是分析目前系统的行为特点。任何系统的应用通常分为如下两类:
- IO范畴:IO范畴的应用需要高负荷地使用内存和下层的存储系统。因为IO范畴的程序在内存中处理大量数据,它并不太依赖CPU和网络(除非是网络存储系统)。IO范畴的程序使用CPU资源来产生IO请求,接着CPU通常进入睡眠状态。数据库应用通常属于IO范畴。
- CPU范畴:CPU范畴的应用需要高负荷地使用CPU。CPU范畴的应用需要CPU批量处理请求和数学计算。大量web服务器,邮件服务器,以及其它渲染计算服务器通常属于CPU范畴。
确定统计基线
系统使用率离不开系统管理员期望的效果和系统的规格。了解系统性能是否有问题的唯一方式是明确系统能达到的效果。应该有怎样的表现,参考值应该是什么?唯一方法就是建立一个基线。数据必须在系统性能可以接受的情况下统计,这样才能和性能不可接受的情况下进行对比。
在下面的例子中,基线的系统性能截图和高负荷的系统性能截图进行对比。
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
1 0 138592 17932 126272 214244 0 0 1 18 109 19 2 1 1 96
0 0 138592 17932 126272 214244 0 0 0 0 105 46 0 1 0 99
0 0 138592 17932 126272 214244 0 0 0 0 198 62 40 14 0 45
0 0 138592 17932 126272 214244 0 0 0 0 117 49 0 0 0 100
0 0 138592 17924 126272 214244 0 0 0 176 220 938 3 4 13 80
0 0 138592 17924 126272 214244 0 0 0 0 358 1522 8 17 0 75
1 0 138592 17924 126272 214244 0 0 0 0 368 1447 4 24 0 72
0 0 138592 17924 126272 214244 0 0 0 0 352 1277 9 12 0 79
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
2 0 145940 17752 118600 215592 0 1 1 18 109 19 2 1 1 96
2 0 145940 15856 118604 215652 0 0 0 468 789 108 86 14 0 0
3 0 146208 13884 118600 214640 0 360 0 360 498 71 91 9 0 0
2 0 146388 13764 118600 213788 0 340 0 340 672 41 87 13 0 0
2 0 147092 13788 118600 212452 0 740 0 1324 620 61 92 8 0 0
2 0 147360 13848 118600 211580 0 720 0 720 690 41 96 4 0 0
2 0 147912 13744 118192 210592 0 720 0 720 605 44 95 5 0 0
2 0 148452 13900 118192 209260 0 372 0 372 639 45 81 19 0 0
2 0 149132 13692 117824 208412 0 372 0 372 457 47 90 10 0 0
仅仅看最后一列(id),它代表空闲时间,我们可以看到再基线的状况下,CPU在79% - 100%的时间是空闲的。在第二个输出里,CPU有100%的使用率而且没有空闲。我们需要确定是否对系统的CPU使用率进行优化。
安装监控工具
绝大多数类Unix系统都有一系列标准的监控命令。它们从最开始就是类Unix系统的一部分。这些监控工具在Linux的基本安装包或额外安装包里就提供了。基本上所有的发行版都有这些工具。尽管有很多开源或第三方工具,但这篇文章的主要介绍使用发行版中自带的工具。
表格1:性能监控工具

CPU介绍
CPU的使用率很大程度上取决于它尝试访问什么资源。内核通过调度器来调度两种类型的资源:线程(单个或多个)和中断。调度器对不同资源给予不同的优先级。下面按从高到低的顺序列出了优先级。
-
- 中断 - 设备告诉内核处理完毕。例如,网卡分发一个包或硬件发起IO请求。
- 内核(系统)进程 - 所有的内核处理运行在这个优先级上。
- 用户进程 - 这块经常被称为“userland”,所有的软件应用运行在这块空间。在内核的调度策略上,这块是最低的优先级。
为了理解内核怎样管理不同的资源,需要介绍一些关键概念。下面章节介绍了上下文切换,运行队列和使用率。
上下文切换
大多数现代处理器在同一时间只能运行一个进程(单线程)或线程。多路超线程处理器可以在同一时间运行多条线程。但Linux内核仍然把双核处理器每个核心当作独立的处理器。例如,一个拥有双核处理器的系统,Linux内核显示为有两个独立的处理器。
一个标准的Linux内核可以同时运行50到50,000个处理线程。在一个CPU上,内核需要调度各个处理线程的平衡。每个线程拥有处理 器分配给它的时间片额度,一旦某个线程的时间片用完或者被某个更高优先级(例如硬中断)取代,这个线程就被重新放回队列中,更高优先级的线程将占据处理 器。这种线程间的切换关系就被称为上下文切换。
内核每次处理上下文切换,就有资源开销用来把线程从CPU寄存器中移除并放置到队列中。系统中上下文切换越频繁,内核就需要在管理调度处理器上做更多的工作。
运行队列
每个CPU维护着线程的运行队列。理想情况下,调度器应该不断运行并执行线程。处理线程要么是在睡眠状态(阻塞并且等待IO),要么是在可运行状 态。如果CPU子系统高负荷,很有可能内核调度器不能及时响应系统请求。结果造成可运行的进程开始阻塞队列。队列越大,处理线程需要等待的时间越长。
一个非常流行的术语称为“load”,它通常用来描诉运行队列的状态。系统的负载值是由当前正在执行的线程数和CPU队列中的线程数相加得 到。比如2个线程正在双核处理器系统中运行,同时有4个线程在等待队列里,那么它的负载就是6。top这类工具报告了负载在1,5和15分钟内的负载平均值。
CPU使用率
CPU使用率定义了CPU使用情况的百分比。CPU的使用率是用来评估系统的一个重要度量值。绝大多数性能监控工具把CPU使用率归到以下几类。
-
- 用户时间 - CPU用来在用户空间执行线程所花费的时间百分比。
- 内核时间 - CPU用来执行内核线程和处理中断所花费的时间百分比。
- IO等待 - CPU空闲,所有线程阻塞用来等待IO请求完成所花费的时间百分比。
- 空闲 - CPU完全空闲所占时间的百分比。
CPU性能监控
了解CPU到底表现如何,重在理解运行队列,使用率和上下文切换的性能。像之前提到的,性能是相对于基线数据的。但是在任何系统中都有一些基本的性能预期。这些预期包括:
-
- 运行队列 - 每个处理器的运行队列不应该超过1-3个。例如,一个双核处理器系统不应该超过6个线程在运行队列里。
- CPU使用率 - 如果一个CPU被完全利用,应该达到下面的平衡。
- 65% - 70%用户时间
- 30% - 35%系统时间
- 0% - 5%空闲时间
- 上下文切换 - 上下文切换的数量直接和CPU使用率相关。如果CPU使用率能保持在前面提到的平衡里,那么大量的上下文切换也是可以接受的。
Linux下有很多工具可以度量这些统计数据,首先介绍的两个就是vmstat和top。
使用vmstat工具
vmstat工具提供了一个优秀且低开销的系统性能展示。正由于vmstat是如此一个低开销的工具,让它在控制台持续运行非常实用,即使你需要在 一台负载很高的服务器上监控健康状况。vmstat有两种工作模式,平均模式和简单模式。简单模式将在指定的间隔里统计数据,这个模式用来在有持续的负载 时了解性能参数最有用。下面例子示范了vmstat运行在1秒间隔里。
# vmstat 1
procs -----------memory------- -swap-- -io-- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 104300 16800 95328 72200 0 0 5 26 7 14 4 1 95 0
0 0 104300 16800 95328 72200 0 0 0 24 1021 64 1 1 98 0
0 0 104300 16800 95328 72200 0 0 0 0 1009 59 1 1 98 0
输出里每个字段的解释如下:
表格2:性能监控工具

案例学习:持续的CPU使用率
在下个例子中,系统属于充分利用状态。
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
3 0 206564 15092 80336 176080 0 0 0 0 718 26 81 19 0 0
2 0 206564 14772 80336 176120 0 0 0 0 758 23 96 4 0 0
1 0 206564 14208 80336 176136 0 0 0 0 820 20 96 4 0 0
1 0 206956 13884 79180 175964 0 412 0 2680 1008 80 93 7 0 0
2 0 207348 14448 78800 175576 0 412 0 412 763 70 84 16 0 0
2 0 207348 15756 78800 175424 0 0 0 0 874 25 89 11 0 0
1 0 207348 16368 78800 175596 0 0 0 0 940 24 86 14 0 0
1 0 207348 16600 78800 175604 0 0 0 0 929 27 95 3 0 2
3 0 207348 16976 78548 175876 0 0 0 2508 969 35 93 7 0 0
4 0 207348 16216 78548 175704 0 0 0 0 874 36 93 6 0 1
4 0 207348 16424 78548 175776 0 0 0 0 850 26 77 23 0 0
2 0 207348 17496 78556 175840 0 0 0 0 736 23 83 17 0 0
0 0 207348 17680 78556 175868 0 0 0 0 861 21 91 8 0 1
通过观察输出,我们可以得出以下结论:
-
- 有大量的中断(in)和少量的上下文切换(cs)。可以看出单个进程正在产生请求到硬件。
- 用户态(us)时间持续在85%或更多,这可以进一步证明是单个应用。同时较少的上下文切换,标明处理器一直在处理这个进程。
- 运行队列差不多在可接受的范围内。在两个时刻,运行队列超过了可接受的范围。
案例学习:负荷过高的调度器
在下面的案例中,内核调度器已经饱和了,它全部用来处理上下文切换。
# vmstat 1procs memory swap io system cpur b swpdfreebuff cache si so bi boincs us sy waid2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 270 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 00 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 70 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 102 0 207740 91300 88452 180984 0 0 1276 0 565 2182 7 6 83 43 1 207740 90124 89628 180984 0 0 1176 0 551 2219 2 7 91 04 2 207740 89240 90512 180984 0 0 880 520 443 907 22 10 67 05 3 207740 88056 91680 180984 0 0 1168 0 628 1248 12 11 77 04 2 207740 86852 92880 180984 0 0 1200 0 654 1505 6 7 87 06 1 207740 85736 93996 180984 0 0 1116 0 526 1512 5 10 85 00 1 207740 84844 94888 180984 0 0 892 0 438 1556 6 4 90 01
通过观察输出,我们可以得出以下结论:
-
- 上下文切换的数量大于中断的数量,这表明CPU使用了大量的时间在线程间的上下文切换上。
- 大量的上下文切换造成CPU使用率的不均衡,这点可以根据等待IO的百分比特别高,而用户态百分比很低这一事实看出来。
- 由于CPU阻塞在等待IO,运行队列开始阻塞,线程由于等待IO也开始阻塞。
使用mpstat工具
如果你的系统有多核处理器,可以使用mpstat来监控每个独立的核心。Linux内核把双核处理器当做两个CPU,同样,四核处理器也被认为是4个CPU可用。mpstat像vmstat一样提供CPU的使用率,但mpstat单独统计出每个核心的基础数据。
# mpstat –P ALL 1Linux 2.4.21-20.ELsmp (localhost.localdomain) 05/23/200605:17:31 PM CPU %user %nice%system %idle intr/s05:17:32 PM all 0.00 0.00 3.19 96.53 13.2705:17:32 PM 0 0.00 0.00 0.00 100.00 0.0005:17:32 PM 1 1.12 0.00 12.73 86.15 13.2705:17:32 PM 2 0.00 0.00 0.00 100.00 0.0005:17:32 PM 3 0.00 0.00 0.00 100.00 0.00案例学习:未充分使用的处理器负载
在下面的案例学习中,有4个CPU核心可用,其中两个CPU在处理进程,使用率被完全占满(CPU0和CPU1)。第三个核心在处理所有的内核和系统调用(CPU3)。第四个核心是空闲状态。 top命令显示有3个进程正完全占满CPU使用率。
# top -d 1top- 23:08:53 up 8:34, 3users, load average: 0.91, 0.37, 0.13Tasks: 190 total, 4 running, 186 sleeping, 0 stopped, 0 zombieCpu(s): 75.2% us, 0.2% sy, 0.0% ni, 24.5%id, 0.0% wa, 0.0% hi, 0.0%siMem: 2074736k total, 448684k used, 1626052kfree, 73756k buffersSwap: 4192956k total, 0k used, 4192956kfree, 259044k cachedPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND15957 nobody 25 0 2776 280 224 R 100 20.5 0:25.48 php15959 mysql 25 0 2256 280 224 R 100 38.2 0:17.78 mysqld15960 apache 25 0 2416 280 224 R 100 15.7 0:11.20 httpd15901 root 16 0 2780 1092 800 R 1 0.1 0:01.59top1 root 16 0 1780 660 572 S 0 0.0 0:00.64 init -
# mpstat –P ALL 1Linux 2.4.21-20.ELsmp (localhost.localdomain) 05/23/200605:17:31 PM CPU %user %nice%system %idle intr/s05:17:32 PM all 81.52 0.00 18.48 21.17 130.5805:17:32 PM 0 83.67 0.00 17.35 0.00 115.3105:17:32 PM 1 80.61 0.00 19.39 0.00 13.2705:17:32 PM 2 0.00 0.00 16.33 84.66 2.0105:17:32 PM 3 79.59 0.00 21.43 0.00 0.0005:17:32 PM CPU %user %nice%system %idle intr/s05:17:33 PM all 85.86 0.00 14.14 25.00 116.4905:17:33 PM 0 88.66 0.00 12.37 0.00 116.4905:17:33 PM 1 80.41 0.00 19.59 0.00 0.0005:17:33 PM 2 0.00 0.00 0.00 100.00 0.0005:17:33 PM 3 83.51 0.00 16.49 0.00 0.0005:17:33 PM CPU %user %nice%system %idle intr/s05:17:34 PM all 82.74 0.00 17.26 25.00 115.3105:17:34 PM 0 85.71 0.00 13.27 0.00 115.3105:17:34 PM 1 78.57 0.00 21.43 0.00 0.0005:17:34 PM 2 0.00 0.00 0.00 100.00 0.0005:17:34 PM 3 92.86 0.00 9.18 0.00 0.0005:17:34 PM CPU %user %nice%system %idle intr/s05:17:35 PM all 87.50 0.00 12.50 25.00 115.3105:17:35 PM 0 91.84 0.00 8.16 0.00 114.2905:17:35 PM 1 90.82 0.00 10.20 0.00 1.0205:17:35 PM 2 0.00 0.00 0.00 100.00 0.0005:17:35 PM 3 81.63 0.00 15.31 0.00 0.00 -
你能通过运行ps命令来确定进程正在占用哪个CPU,通过PSR这一列可以看出(译:PSR这一列表明目前第几个CPU正在处理这个进程)。# while :; do ps -eo pid,ni,pri,pcpu,psr,comm | grep 'mysqld'; sleep 1;donePID NI PRI %CPU PSR COMMAND15775 0 15 86.0 3 mysqldPID NI PRI %CPU PSR COMMAND15775 0 14 94.0 3 mysqldPID NI PRI %CPU PSR COMMAND15775 0 14 96.6 3 mysqldPID NI PRI %CPU PSR COMMAND15775 0 14 98.0 3 mysqldPID NI PRI %CPU PSR COMMAND15775 0 14 98.8 3 mysqldPID NI PRI %CPU PSR COMMAND15775 0 14 99.3 3 mysqld总结
监控CPU性能由以下几部分组成。
- 检查运行队列保证每处理器不超过3个可执行的线程。
- 确定CPU使用率中,用户态和内核态的比率为70/30。
- 当CPU花费更多时间在系统模式中,很有可能是因为负载过高,在重新调度优先级。
- 当I/O处理增加时,CPU范畴的应用经常会受到不利的影响。
-
-
虚拟内存介绍
虚拟内存把磁盘当作内存的扩展,可以有效地提高可用内存的容量。内核将当前不使用的内存块写入磁盘,空出来的内存空间便可以做其它用途。当需要之前 的内存数据时,内核就将它们读回到内存。这一切对用户而言都是透明的。在Linux下运行的程序只能看到大量的可用内存,并不能注意到它们偶尔是驻留在磁 盘上的。当然,和使用内存相比,读写磁盘会更慢一些(大约慢几千倍),因此程序没法快速执行。磁盘上当作虚拟内存使用的部分称为交换空间。
虚拟内存分页
虚拟内存被分割成页,页是内存管理的基本单位。在X86架构下,每个虚拟内存页是4KB。当内核写内存到磁盘或从磁盘读回内存,也是以页来管理。内核写内存页时,既写到磁盘交换设备里,又写到文件系统中。
内核的内存分页调度
内核分页调度是一个普通的活动,不要把它和内存与虚拟内存之间的交换弄混淆了。内存分页调度是进程在通常的间隔时间里同步内存里的数据到磁盘里。随着时间的推移,应用程序会消耗所有的内存。某些情况下,内核必须扫描内存然后回收未使用的页,这样才能为其它的应用程序分配内存。
页框回收算法
页框回收算法用来释放内存。它根据页的类型来选择是否释放内存。类型如下:
-
- 不可回收页 - 锁定页,内核动态分配页,保留页
- 可交换页 - 用户态地址空间的匿名页
- 可同步页 - 磁盘高速缓存的页
- 可丢弃页 - 内存高速缓存中未使用的页,目录项高速缓存的未使用页
除了“不可回首页”以外,其它的可能被页框回收算法回收。
页框回收算法主要有两个功能,它们是kswapd线程和“LMR算法”函数。
kswapd
kswapd守护进程负责保证内存空余空间。它监控内核中的pages_high和pages_low阀值。如果可用内存的大小低于pages_low,kswapd进程开始扫描并尝试一次回收32页。它不断重复直到内存大小超过pages_high阀值。
kswapd线程完成下列工作:
-
- 如果页未更改,把页放到空闲列表里。
- 如果页已更改并被分到文件系统,那么把页的内容写入磁盘。
- 如果页已更改,且并没有被文件系统备份(匿名),那么就将页的内容写到swap设备里。
[sk@SK:~]$ps-ef |grepkswapdroot 25 2 0 09:33 ? 00:00:02 [kswapd0]sk 11245 3752 0 17:21 pts/000:00:00grep--color=auto kswapd<font color="#000000"> </font> -
过pdflush调度内核分页
pdflush守护进程负责将关系到文件系统的页同步到磁盘。换句话说,当一个文件在内存中被使用,pdflush守护进程把它写回磁盘。
[roger@xxx:~]$ ps -ef | grep pdflush
root 1624 35 0 Aug24 ? 00:00:34 [pdflush]
roger 5110 4935 0 17:26 pts/198 00:00:00 grep pdflush
root 23547 35 0 Aug23 ? 00:00:27 [pdflush]
<font style="font-size: 9.8pt">当内存中有10%的脏页时,pdflush守护进程开始同步脏页到文件系统。这个数值可以通过内核参数vm.dirty_background_ratio来调整。</font>
[root@SK sk]# sysctl -n vm.dirty_background_ratio
10
pdflush守护进程在大多数情况下与PFRA是独立工作的。当内核调用LMR算法时,除了其它的常规页释放以外,LMR特别强制pdflush写脏页。
在2.4的内核里,如果内存负载压力很大。系统可能造成swap失效。这在PFRA准备偷一个活动进程正准备要使用的页时发生。结果,进程 不得不回收这个页,而它会被再次偷取。这在2.6的内核中通过“Swap Token”修复,它禁止PFRA不断地从一个进程偷取同一个页。(译注:swapout protection token(swap token)防止页面“抖动”)
案例学习:大的入站I/O
vmstat工具除了显示CPU使用率,也显示虚拟内存的使用情况。接下来介绍vmstat输出与虚拟内存有关的部分。
表格2:虚拟内存的统计信息

下面vmstat输出表明在IO应用程序的峰值情况下,虚拟内存有很高的使用率。
<font style="font-size: 9.8pt"><font color="#000000" size="2"># vmstat 3
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
3 2 809192 261556 79760 886880 416 0 8244 751 426 863 17 3 6 75
0 3 809188 194916 79820 952900 307 0 21745 1005 1189 2590 34 6 12 48
0 3 809188 162212 79840 988920 95 0 12107 0 1801 2633 2 2 3 94
1 3 809268 88756 79924 1061424 260 28 18377 113 1142 1694 3 5 3 88
1 2 826284 17608 71240 1144180 100 6140 25839 16380 1528 1179 19 9 12 61
2 1 854780 17688 34140 1208980 1 9535 25557 30967 1764 2238 43 13 16 28
0 8 867528 17588 32332 1226392 31 4384 16524 27808 1490 1634 41 10 7 43
4 2 877372 17596 32372 1227532 213 3281 10912 3337 678 932 33 7 3 57
1 2 885980 17800 32408 1239160 204 2892 12347 12681 1033 982 40 12 2 46
5 2 900472 17980 32440 1253884 24 4851 17521 4856 934 1730 48 12 13 26
1 1 904404 17620 32492 1258928 15 1316 7647 15804 919 978 49 9 17 25
4 1 911192 17944 32540 1266724 37 2263 12907 3547 834 1421 47 14 20 20
1 1 919292 17876 31824 1275832 1 2745 16327 2747 617 1421 52 11 23 14
5 0 925216 17812 25008 1289320 12 1975 12760 3181 772 1254 50 10 21 19
0 5 932860 17736 21760 1300280 8 2556 15469 3873 825 1258 49 13 24 15</font></font>
我们能从上面输出观察到以下几点:
-
- 大量的磁盘块从文件系统写入(bi)到内存。这可以从cache缓存的数据占用的进程地址空间(cache)持续增长得出。
- 在这段时间里,可用内存稳定(free)稳定保持在17MB,即使磁盘里的数据需要写入到可用的内存。
- 为了维护可用的内存列表,kswapd从read/write的缓存(buffer)里偷取内存,并把它交给可用内存列表。这可以从buff缓存大小(buff)的持续下降得到。
- kswapd进程写脏页到swap设备(so)这可以由虚拟内存使用量持续上升得出(swpd)。
总结
虚拟内存性能监控包括下面这些部分:
-
- 系统中主缺页错误(major page faults)越少,响应时间越快。
- 可用内存量很少是一个好信号,它表示缓存(caches)被有效使用,除非持续地在写swap设备和磁盘。
- 如果系统报告持续使用swap设备,这意味着物理内存不足。因为相比于磁盘缓存,内存缓存会快很多,这是一个杠杆效应。
I/O监控介绍
磁盘I/O子系统在任何Linux系统里都是最慢的。这主要是因为磁盘离CPU距离较远和磁盘物理上的工作方式(轮转和寻道)决定的。如果将访问磁 盘和访问内存的时间转换成分钟和秒进行对比,那就是7天和7分钟的区别。因此,Linux内核将在磁盘上产生的I/O最小化就是非常有必要的。下面的小节 描述了内核处理内存和磁盘之间数据I/O的相互交换的不同方式。
读和写 - 内存分页
Linux内核将磁盘I/O分割成页。在绝大多数Linux系统上,默认的页大小是4K。它以4K为页大小读写磁盘块到内存或出内存。你可以通过time命令来查看页大小,在详尽(verbose)模式中搜索页大小。
<font color="#000000">[sk@SK:~]$ /usr/bin/time -v date
<snip>
Page size (bytes): 4096
<snip></font>
主和辅页错误
Linux,类似于其它Unix系统,使用虚拟内存层映射到物理地址空间。当一个进程启动的时候,这个映射是“被要求”产生的,内核只映射那些需要 的部分。在进程开始的时候,内核搜索CPU缓存和物理内存。如果数据都不存在,内核抛出主页错误的异常(MPF)。MPF是一个请求到磁盘子系统来检索磁 盘找回页并缓存到RAM里。
一旦内存页映射成缓存,内核尝试在小页错误(MnPF)里使用这些页。MnPF节约内核时间,通过重新使用内存里的一个页而不是把它放到磁盘里。
在下面的例子中,time命令用来显示当一个应用启动的时候,有多少MPF和MnPF产生了。应用程序第一次启动的时候,会有很多MPF。
<font color="#000000">[sk@SK:~]$ /usr/bin/time -v audacious
<snip>
Major (requiring I/O) page faults: 93
Minor (reclaiming a frame) page faults: 3844
<snip></font>
第二次启动的时候,内核没有抛出任何MPF,因为应用程序已经在内存里了。
<font color="#000000">[sk@SK:~]$ /usr/bin/time -v audacious
<snip>
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 3913
<snip>
</font>
文件缓冲区缓存
文件缓冲区缓存是内核用来最小化MPF并且最大化MnPF的。随着系统产生I/O请求,缓存将持续增大,系统将在内存中保存这些页,直到内存容量很 低并且内核需要释放一些页保留作其它用途。最后导致一些系统管理员看见可用内存很少并开始担心什么时候出现这个问题,其实系统仅仅是充分利用内存,将它们 缓存起来了。
下面的输出是从/proc/meminfo中取出的:
<font color="#000000">[sk@SK:~]$ cat /proc/meminfo
MemTotal: 2015244 kB
MemFree: 191648 kB
Buffers: 16284 kB
Cached: 590536 kB
<snip></font>
系统一共有2GB(MemTotal)物理内存。当前还剩191MB(MemFree)空余内存。16MB分配给磁盘进行写操作(Buffers),590MB的页从磁盘读到内存里(Caches)。
内核使用内存是通过MnPF机制,以此来避免从磁盘中拿出所有的页。由于我们只有这部分统计数据,因此无法得知系统是否在重负荷状况下。
内存分页类型
Linux内核有三种类型的的内存页,下面我们会逐个讨论:
-
- 只读页(代码页),那些通过主缺页中断从硬盘读取的页面,包括不能修改的静态文件、可执行文件、库文件等。当内核需要它们的时候把它们读到内存中,当内存不足的时候,内核就释放它们到空闲列表,当程序再次需要它们的时候需要通过缺页中断再次读到内存。
- 脏页,指那些在内存中被修改过的数据页,比如文本文件等。这些文件由pdflush负责同步到硬盘,内存不足的时候由kswapd和pdflush把数据写回硬盘并释放内存。
- 匿名页,那些属于某个进程但是又和任何文件都没有关联,不能被同步到硬盘上,内存不足的时候由kswapd负责将它们写到交换分区并释放内存。
数据页写回磁盘
应用程序可能自己选择使用fsync()或sync()系统调用立刻写脏页到磁盘。这些系统调用向I/O调度器发送一个直接请求。如果应用程序并不请求系统调用,pdflush内核守护进程会每隔一段时间周期性地运行把页写回磁盘。
<font color="#000000">[roger@xxx:~]$ ps -ef | grep pdflush
root 1624 35 0 Aug24 ? 00:00:44 [pdflush]
roger 16085 14515 0 22:31 pts/51 00:00:00 grep pdflush
root 23547 35 0 Aug23 ? 00:00:35 [pdflush]</font>
I/O监控
某些情况下也会产生I/O的瓶颈。这些情况能通过一系列的标准的系统监控工具看出来。这些工具包括top, vmstat, iostat和sar。这些命令的输出有些会比较类似,但大部分情况是:每种工具都提供了某些性能指标的唯一输出。下面这些子章节描述了产生I/O瓶颈的 情况。
计算每秒的I/O
每一个到磁盘的I/O请求都会需要一定的时间。这主要是因为磁盘必须旋转而且磁头必须寻道。磁盘的旋转经常会提到“旋转延迟(rotational delay)”(RD)和移动磁头“磁头寻道(disk seek)”(DS)。每一个I/O请求所花的时间是由DS和RD计算得来。一个磁盘的RD基于每分钟磁盘的转速(RPM)。通常我们认为RD是磁盘旋转 一圈的时间的一半。下面我们来计算一个万转(10K RPM)磁盘的RD:
- 用10000 RPM除以60秒。(10000/60 = 166 RPS)
- 将1/166转换成小数。(1/166 = 0.0006秒每转)
- 将每转秒数乘以1000毫秒。(6毫秒每转)
- 取6毫秒的一半(6/2 = 3毫秒)这就是RD。
- 加上平均3毫秒的寻道时间(3毫秒 + 3毫秒 = 6毫秒)。
- 加上2毫秒的延迟(内部传输)(6毫秒 + 2毫秒 = 8毫秒)
- 用1000毫秒除以8毫秒就是每秒I/O(1000/8 = 125 IOPS)
每当应用程序请求一次I/O,如果是万转磁盘(10k RPM)平均花费8毫秒在I/O上。虽然这是一个定值,但对磁盘读写所花费的时间来说,它是重要的性能指标。I/O请求量经常通过每秒I/O(IOPS) 来测量。10K RPM 磁盘有能力达到120至150(突发)IOPS。为了测量IOPS的有效性,将IOPS分成读/写两种IOPS。
随机vs顺序I/O
每个I/O所产生的效果依赖于系统的工作负载。系统里有两种工作负载,顺序I/O和随机I/O。
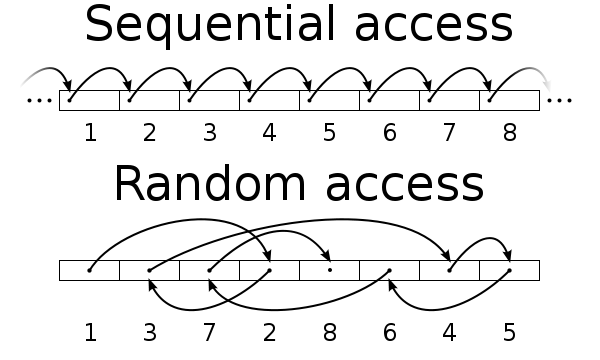
- 顺寻I/0
iostat命令提供了IOPS的信息和每个I/O在被处理的数据量。使用 -x 来显示扩展信息。顺序的工作负载需要一次性地顺序读取大量的数据。这些应用类似企业级的数据库执行大量的查询和流媒体服务正在采集数据。在顺序工作负载 里,每个I/O包含的KB数会很高。顺序的工作负载的性能依赖于尽可能快地搬运大量数据的能力。如果每个I/O花费时间,尽可能多地在每个I/O里取出数 据就非常重要。
<font style="font-size: 9.8pt"><font color="#000000" size="2"># iostat -x 1
avg-cpu: %user %nice %sys %idle
0.00 0.00 57.1 4 42.86
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 12891.43 0.00 105.71 0.00 106080.00 0.00 53040.00 1003.46 1099.43 3442.43 26.49 280.00
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 12857.14 0.00 5.71 0.00 105782.86 0.00 52891.43 18512.00 559.14 780.00 490.00 280.00
/dev/sda3 0.00 34.29 0.00 100.00 0.00 297.14 0.00 148.57 2.97 540.29 3594.57 24.00 240.00
avg-cpu: %user %nice %sys %idle
0.00 0.00 23.53 76.47
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 17320.59 0.00 102.94 0.00 142305.88 0.00 71152.94 1382.40 6975.29 952.29 28.57 294.12
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 16844.12 0.00 102.94 0.00 138352.94 0.00 69176.47 1344.00 6809.71 952.29 28.57 294.12
/dev/sda3 0.00 476.47 0.00 0.00 0.00 952.94 0.00 1976.47 0.00 165.59 0.00 0.00 276.47</font></font>
计算IOPS的效率的方式是用读的KB数(rkB/s)和写的KB数(wkB/s)除以每秒读的次数(r/s)和写的次数(w/s)。在上面的输出中,/dev/sda的每个I/O写的数据量逐渐递增:
-
- 53040/105 = 505KB per I/O
- 71152/102 = 697KB per I/O
- 随机I/O
随机访问工作负载对数据的大小依赖并不多。它们主要依赖于磁盘能达到的IOPS数。Web服务器和电子邮件服务器是随机访问工作负载的例子。每个I/O请求都非常小。随机访问工作负载依赖于一次能处理多少请求。因此,磁盘能达到的IOPS数就是关键因素。
<font color="#000000">avg-cpu: %user %nice %sys %idle
2.04 0.00 97.96 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 633.67 3.06 102.31 24.49 5281.63 12.24 2640.82 288.89 73.67 113.89 27.22 50.00
/dev/sda1 0.00 5.10 0.00 2.04 0.00 57.14 0.00 28.57 28.00 1.12 55.00 55.00 11.22
/dev/sda2 0.00 628.5 7 3.06 100.27 24.49 5224.49 12.24 2612.24 321.50 72.55 121.25 30.63 50.00
/dev/sda3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %sys %idle
2.15 0.00 97.85 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 41.94 6.45 130.98 51.61 352.69 25.81 3176.34 19.79 2.90 286.32 7.37 15.05
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 41.94 4.30 130.98 34.41 352.69 17.20 3176.34 21.18 2.90 320.00 8.24 15.05
/dev/sda3 0.00 0.00 2.15 0.00 17.20 0.00 8.60 0.00 8.00 0.00 0.00 0.00 0.00</font>
前面的输出显示了写的IOPS数量和之前的顺序写的输出差不多。不同之处是每个I/O实际写的大小。
-
- 2640/102 = 23KB per I/O
- 3176/130 = 24KB per I/O
当虚拟内存杀掉I/O
如果系统没有足够的内存来容纳所有的请求,就必须开始使用swap设备。就像磁盘I/O一样,写到swap设备需要些开销。如果系统完全没有了内 存,就可能产生换页风暴到swap磁盘上。如果swap设备和系统正尝试访问的数据在同一个文件系统上,系统将进入I/O路径的竞争。这会造成系统性能的 完全崩溃。如果页不能读或写到磁盘,会在内存中呆更久。如果呆更久,内核就需要释放内存。问题是I/O通道如此阻塞,什么都做不了。最终不可避免地造成 kernel panic和系统崩溃。
下面的vmstat输出展示了系统在缺乏内存的情况。它把数据写到swap设备里。
<font color="#000000">procs -------memory---------- -swap-- ---io--- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
17 0 1250 3248 45820 1488472 30 132 992 0 2437 7657 23 50 0 23
11 0 1376 3256 45820 1488888 57 245 416 0 2391 7173 10 90 0 0
12 0 1582 1688 45828 1490228 63 131 1348 76 2432 7315 10 90 0 10
12 2 3981 1848 45468 1489824 185 56 2300 68 2478 9149 15 12 0 73
14 2 10385 2400 44484 1489732 0 87 1112 20 2515 11620 0 12 0 88
14 2 12671 2280 43644 1488816 76 51 1812 204 2546 11407 20 45 0 35</font>
前面的输出显示了大量的到内存的读请求(bi)。由于请求太多,系统内存不足(free)。这造成系统把块写入swap设备(so)因此swap的大小不停增长(swpd)。同时注意到大量的IO等待时间百分比(wa)。这证明CPU由于I/O请求变慢。
查看由于使用swap给磁盘造成的影响,用iostat命令查看swap所在的设备。
<font color="#000000"># iostat -x 1
avg-cpu: %user %nice %sys %idle
0.00 0.00 100.00 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 1766.67 4866.67 1700.00 38933.33 31200.00 19466.67 15600.00 10.68 6526.67 100.56 5.08 3333.33
/dev/sda1 0.00 933.33 0.00 0.00 0.00 7733.33 0.00 3866.67 0.00 20.00 2145.07 7.37 200.00
/dev/sda2 0.00 0.00 4833.33 0.00 38666.67 533.33 19333.33 266.67 8.11 373.33 8.07 6.90 87.00
/dev/sda3 0.00 833.33 33.33 1700.00 266.67 22933.33 133.33 11466.67 13.38 6133.33 358.46 11.35 1966.67</font>
在前面的例子中,swap设备(/dev/sda1)和文件系统设备(/dev/sda3)在竞争I/O。它们都有大量的每秒写请求(w/s)和高等待时间(await)低服务时间率(svctm)。这证明两个分区之间有竞争,造成共同的性能下降。
总结
I/O性能监控包含下面工作:
-
- 任何时间只要CPU在等待I/O,就表示磁盘负荷过大。
- 计算你的磁盘能够达到的IOPS
- 确定你的应用程序需要随机磁盘访问还是顺序磁盘访问。
- 监控慢的磁盘通过比较等待时间和服务时间。
- 监控swap和文件系统分区来确认虚拟内存没有和文件系统竞争I/O。
网络监控介绍
在所有的子系统监控里,网络是最难监控的。这主要是由于网络非常抽象。在开始监控性能的时候,会有很多因素在系统能控制的范围之上。这些因素包括延迟,冲突,拥塞和坏包,还有其它一些。
本章节关注怎样检查以太网,IP和TCP。
以太网配置
除非明确指定,所有以太网自适应速度。在历史上,这样做有大量的好处,尤其是网络上各种设备,各种速度和双工模式。
大多数企业的网络运行在100或1000BaseTX。使用ethtool来确定特指定的系统协商用的这个速度。
在下面的例子中,一个系统使用的100BaseTX网卡运行在自适应的10BaseT下。
<font color="#000000"># ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: Yes
Speed: 10Mb/s
Duplex: Half
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: yes</font>
下面的例子展示了怎样强制指定网卡运行在100BaseTX:
<font style="font-size: 9.8pt"><font color="#000000"># ethtool -s eth0 speed 100 duplex full autoneg off
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: No
Speed: 100Mb/s
Duplex: Full
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: off
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: yes</font></font>
监控网络吞吐量
一个网卡仅仅同步成功并不代表它没有带宽的问题。把交换机,网线和路由器摆放在两个主机系统之间测试,这是不现实的。检查网络吞吐量最好的方法是在两个系统之间传输数据,然后测量类似于延迟和速度这样的统计数据。
-
- 使用iptraf来监控本地吞吐量
iptraf工具(http://iptraf.seul.org) 提供每个网卡吞吐量的仪表盘。
<font color="#000000"># iptraf -d eth0</font>
前面的输出显示系统测试正在使用61mbps(7.65MB)的速率传输。这对一个100mps的网络来说,实在很慢。
-
- 使用netperf来监控端点的吞吐量
不像iptraf这种被动的网卡流量监控方式,netperf工具允许系统管理员进行网络吞吐量的控制调整测试。这对确定网络之间的吞吐量非常有效,例如从一个客户端工作站到一个高负载的服务器例如文件或web服务器。netperf运行在客户端-服务端模式。
<font color="#000000">server# netserver
Starting netserver at port 12865
Starting netserver at hostname 0.0.0.0 port 12865 and family AF_UNSPEC</font>
netperf能进行多种多样的测试。最基本测试是标准的吞吐量测试。下面的测试是从客户端发起一个在以太网上的30秒的TCP吞吐量测试。
输出显示网络的吞吐量在89mbps左右。服务器(192.168.1.215)是在同样的以太网。这对一个100mbps的网络来说,性能非常不错了。
<font color="#000000">client# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.230 (192.168.1.230) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
87380 16384 16384 30.02 89.46</font>
离开局域网,换成54G的无线网络,离路由器10英尺远。输出的吞吐量明显下降。理论速度是54MBits,笔记本只达到了14MBits的吞吐量。
<font style="font-size: 9.8pt"><font color="#000000">client# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
87380 16384 16384 30.10 14.09</font></font>
在50英尺远的地方,并且下了一个楼层,信号下降到5MBits。
<font style="font-size: 9.8pt"><font color="#000000"># netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
87380 16384 16384 30.64 5.05</font></font>
这次我们接到公共的互联网上,吞吐量掉到了1Mbit以下。
<font style="font-size: 9.8pt"><font color="#000000"># netperf -H litemail.org -p 1500 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
litemail.org (72.249.104.148) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
87380 16384 16384 31.58 0.93</font></font>
最后的测试是VPN连接,在所有网络里面它是最差的吞吐量。
<font style="font-size: 9.8pt"><font color="#000000"># netperf -H 10.0.1.129 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
10.0.1.129 (10.0.1.129) port 0 AF_INET
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
87380 16384 16384 31.99 0.51</font></font>
另一个很有用的测试是使用netperf监控每秒能处理的TCP的请求和应答的数量。这个测试通过建立一个TCP连接,并在这个连接上发送很多请求 /应答序列。(ack包回来后向外发送一个1字节大小的包)。这个行为很像关系型数据库系统执行大量的处理,邮件服务器在一个连接里传送很多条信息。
下面的例子模拟了在30秒内持续的TCP请求/应答。
<font color="#000000">client# netperf -t TCP_RR -H 192.168.1.230 -l 30
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET
to 192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 87380 1 1 30.00 4453.80
16384 87380</font>
在前面的输出里,网络的处理效率达到4453psh/ack每秒,但这是在1字节的包大小下测试的。这对现实中的请求来说,不是很真实,尤其是应答的包,它们应该比1字节要大的多。
在更真实的例子里,netperf使用默认2K大小的包作请求,32K大小的包作应答。
<font color="#000000">client# netperf -t TCP_RR -H 192.168.1.230 -l 30 -- -r 2048,32768
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 87380 2048 32768 30.00 222.37
16384 87380</font>
处理效率下降非常明显,现在每秒只能处理222次。
-
- 使用iperf来衡量网络效率
iperf也是在两个节点之间检查连接情况,这和netperf非常类似。iperf的不同之处是它在TCP/UDP效率方面的检测更加深入,例如滑动窗口机制和QoS设置。这个工具是为想优化TCP/IP协议栈并测试协议栈效率的系统管理员设计的。
iperf工具是单个二进制文件,能运行在服务器或客户端模式。默认运行在5001端口。
启动服务(192.168.1.215):
<font color="#000000">server# iperf -s -D
Running Iperf Server as a daemon
The Iperf daemon process ID : 3655
------------------------------------------------------------
Server listening on TCP port 5001
TCP window size: 85.3 KByte (default)
------------------------------------------------------------</font>
在下面的例子中,iperf运行在客户端模式,在一个无线网络上反复测试吞吐量。这个无线网络负载很高,包括多个主机正在下载ISO镜像文件。
客户端连接到服务端(192.168.1.215)并运行一个60秒的带宽测试,5秒报告一次结果。
<font color="#000000">client# iperf -c 192.168.1.215 -t 60 -i 5
------------------------------------------------------------
Client connecting to 192.168.1.215, TCP port 5001
TCP window size: 25.6 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.224.150 port 51978 connected with
192.168.1.215 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 5.0 sec 6.22 MBytes 10.4 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 5.0-10.0 sec 6.05 MBytes 10.1 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 10.0-15.0 sec 5.55 MBytes 9.32 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 15.0-20.0 sec 5.19 MBytes 8.70 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 20.0-25.0 sec 4.95 MBytes 8.30 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 25.0-30.0 sec 5.21 MBytes 8.74 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 30.0-35.0 sec 2.55 MBytes 4.29 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 35.0-40.0 sec 5.87 MBytes 9.84 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 40.0-45.0 sec 5.69 MBytes 9.54 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 45.0-50.0 sec 5.64 MBytes 9.46 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 50.0-55.0 sec 4.55 MBytes 7.64 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 55.0-60.0 sec 4.47 MBytes 7.50 Mbits/sec
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-60.0 sec 61.9 MBytes 8.66 Mbits/sec</font>
在这60秒的重复测试中,吞吐量始终在4-10Mbits之间波动,看起来其它主机的流量并没有对这台机器的带宽产生太大影响。
除了TCP测试以外,iperf在UDP方面也能测试丢包和抖动。下面的iperf测试运行在同样负载的无线54Mbits G网下。就像前面例子里展示的,网络吞吐量只有最高54Mbits的里的9Mbits。
<font color="#000000"># iperf -c 192.168.1.215 -b 10M
WARNING: option -b implies udp testing
------------------------------------------------------------
Client connecting to 192.168.1.215, UDP port 5001
Sending 1470 byte datagrams
UDP buffer size: 107 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.224.150 port 33589 connected with 192.168.1.215 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 11.8 MBytes 9.90 Mbits/sec
[ 3] Sent 8420 datagrams
[ 3] Server Report:
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 3] 0.0-10.0 sec 6.50 MBytes 5.45 Mbits/sec 0.480 ms 3784/ 8419 (45%)
[ 3] 0.0-10.0 sec 1 datagrams received out-of-order</font>
这个例子里,有10M数据尝试传输,但是在对端实际上只收到了5.45M,包的丢失率达到了45%。
用tcptrace监控单独的连接
tcptrace工具提供了对指定连接的基于TCP的详细信息。工具基于libpcap文件来运行和分析指定的TCP会话。它提供的信息有时候是TCP流里很难捕捉到的。这些信息包括
-
- TCP重传 - 包需要被重传的数目和总的数据大小
- TCP窗口大小 - 通过小的窗口大小辨认慢连接
- 连接总的吞吐量
- 连接的持续时间
- 案例学习 - 使用tcptrace
tcptrace也许在一些Linux发行版的软件包仓库中已经附带了。这篇文章使用预编译的包,网址是:(http://dag.wieers.com/rpm/packages/tcptrace )。tcptrace命令从基于libpcap的文件输入。不使用任何参数的话,它列出捕捉文件里的所有唯一的连接。
下面的例子使用一个叫做bigstuff的libpcap文件。
<font color="#000000"># tcptrace bigstuff
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:01.634065, 89413 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
1: 192.168.1.60:pcanywherestat - 192.168.1.102:2571 (a2b) 404> 450<
2: 192.168.1.60:3356 - ftp.strongmail.net:21 (c2d) 35> 21<
3: 192.168.1.60:3825 - ftp.strongmail.net:65023 (e2f) 5> 4<
(complete)
4: 192.168.1.102:1339 - 205.188.8.194:5190 (g2h) 6> 6<
5: 192.168.1.102:1490 - cs127.msg.mud.yahoo.com:5050 (i2j) 5> 5<
6: py-in-f111.google.com:993 - 192.168.1.102:3785 (k2l) 13> 14<
<snip></font>
1
<font color="#000000"></font>
在前面的输出里,每个连接都有关联的编号,还有源主机和目的主机。tcptrace最常用的选项是 -l 和 -o ,它们提供指定连接的详细统计数据。
下面的例子列出了在bigstuff中的#1连接的所有统计数据。
<font color="#000000"># tcptrace -l -o1 bigstuff
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:00.529361, 276008 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
32 TCP connections traced:
TCP connection 1:
host a: 192.168.1.60:pcanywherestat
host b: 192.168.1.102:2571
complete conn: no (SYNs: 0) (FINs: 0)
first packet: Sun Jul 20 15:58:05.472983 2008
last packet: Sun Jul 20 16:00:04.564716 2008
elapsed time: 0:01:59.091733
total packets: 854
filename: bigstuff
a->b: b->a:
total packets: 404 total packets: 450
ack pkts sent: 404 ack pkts sent: 450
pure acks sent: 13 pure acks sent: 320
sack pkts sent: 0 sack pkts sent: 0
dsack pkts sent: 0 dsack pkts sent: 0
max sack blks/ack: 0 max sack blks/ack: 0
unique bytes sent: 52608 unique bytes sent: 10624
actual data pkts: 391 actual data pkts: 130
actual data bytes: 52608 actual data bytes: 10624
rexmt data pkts: 0 rexmt data pkts: 0
rexmt data bytes: 0 rexmt data bytes: 0
zwnd probe pkts: 0 zwnd probe pkts: 0
zwnd probe bytes: 0 zwnd probe bytes: 0
outoforder pkts: 0 outoforder pkts: 0
pushed data pkts: 391 pushed data pkts: 130
SYN/FIN pkts sent: 0/0 SYN/FIN pkts sent: 0/0
urgent data pkts: 0 pkts urgent data pkts: 0 pkts
urgent data bytes: 0 bytes urgent data bytes: 0 bytes
mss requested: 0 bytes mss requested: 0 bytes
max segm size: 560 bytes max segm size: 176 bytes
min segm size: 48 bytes min segm size: 80 bytes
avg segm size: 134 bytes avg segm size: 81 bytes
max win adv: 19584 bytes max win adv: 65535 bytes
min win adv: 19584 bytes min win adv: 64287 bytes
zero win adv: 0 times zero win adv: 0 times
avg win adv: 19584 bytes avg win adv: 64949 bytes
initial window: 160 bytes initial window: 0 bytes
initial window: 2 pkts initial window: 0 pkts
ttl stream length: NA ttl stream length: NA
missed data: NA missed data: NA
truncated data: 36186 bytes truncated data: 5164 bytes
truncated packets: 391 pkts truncated packets: 130 pkts
data xmit time: 119.092 secs data xmit time: 116.954 secs
idletime max: 441267.1 ms idletime max: 441506.3 ms
throughput: 442 Bps throughput: 89 Bps</font>
- 案例学习 - 计算重传的百分比
要辨别出哪个连接有足够严重的重传问题需要分析,通常这是不可能的。tcptrace工具有能力使用过滤器和判断表达式来定位有问题的连接。一个有很多人连接的饱和的网络,有可能所有的连接都在经历重传。定位哪一个连接重传最严重是关键。
在下面的例子中,tcptrace命令使用过滤器来定位重传超过100个片段的连接。
<font color="#000000"># tcptrace -f'rexmit_segs>100' bigstuff
Output filter: ((c_rexmit_segs>100)OR(s_rexmit_segs>100))
1 arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:00.687788, 212431 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
16: ftp.strongmail.net:65014 - 192.168.1.60:2158 (ae2af) 18695> 9817<</font>
在前面的输出中,#16连接正经受超过100的重传,从这里开始,tcptrace只提供那个连接的统计数据。
<font color="#000000"># tcptrace -l -o16 bigstuff
arg remaining, starting with 'bigstuff'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
146108 packets seen, 145992 TCP packets traced
elapsed wallclock time: 0:00:01.355964, 107752 pkts/sec analyzed
trace file elapsed time: 0:09:20.358860
TCP connection info:
32 TCP connections traced:
================================
TCP connection 16:
host ae: ftp.strongmail.net:65014
host af: 192.168.1.60:2158
complete conn: no (SYNs: 0) (FINs: 1)
first packet: Sun Jul 20 16:04:33.257606 2008
last packet: Sun Jul 20 16:07:22.317987 2008
elapsed time: 0:02:49.060381
total packets: 28512
filename: bigstuff
ae->af: af->ae:
<snip>
unique bytes sent: 25534744 unique bytes sent: 0
actual data pkts: 18695 actual data pkts: 0
actual data bytes: 25556632 actual data bytes: 0
rexmt data pkts: 1605 rexmt data pkts: 0
rexmt data bytes: 2188780 rexmt data bytes: 0</font>
计算重传率:
rexmt/actual * 100 = Retransmission rate
或者
1605/18695 * 100 = 8.5%
前面的连接有8.5%的重传率,这是造成连接缓慢的原因。
- 案例学习 - 根据时间来计算重传
tcptrace工具提供了一系列的模块来从不同维度展示数据,例如协议,端口,时间等等。这个slice模块允许你查看一段时间里的TCP性能。特别的,你能辨认出什么时候有重传发生,把它和别的性能数据结合到一起来定位瓶颈。
下面的例子展示了怎样使用tcptrace创建时间片输出。
# tcptrace -xslice bigfile
这条命令在当前目录创建了一个叫slice.dat的文件。这个特定的文件包含了间隔15秒的重传信息。
<font color="#000000"># ls -l slice.dat
-rw-r--r-- 1 root root 3430 Jul 10 22:50 slice.dat
# more slice.dat
date segs bytes rexsegs rexbytes new active
--------------- -------- -------- -------- -------- -------- --------
22:19:41.913288 46 5672 0 0 1 1
22:19:56.913288 131 25688 0 0 0 1
22:20:11.913288 0 0 0 0 0 0
22:20:26.913288 5975 4871128 0 0 0 1
22:20:41.913288 31049 25307256 0 0 0 1
22:20:56.913288 23077 19123956 40 59452 0 1
22:21:11.913288 26357 21624373 5 7500 0 1
22:21:26.913288 20975 17248491 3 4500 12 13
22:21:41.913288 24234 19849503 10 15000 3 5
22:21:56.913288 27090 22269230 36 53999 0 2
22:22:11.913288 22295 18315923 9 12856 0 2
22:22:26.913288 8858 7304603 3 4500 0 1</font>
总结
为了监控网络的性能,我们需要做以下工作。
-
- 确认每个以太网卡都运行在正确的速率上。
- 检查所有网卡的吞吐量的总和,确认它的网络速度是合理的。
- 监控网络流量类型来确定适当的流量在系统里有优先级。
附录:一步一步开始性能监控 - 案例学习
在下面的情景里,一个终端用户呼叫支持并抱怨,在web用户接口里的报告模块原本只需要15秒就能创建报告,现在却要20分钟。
系统配置
-
- Redhat Enterprise Linux 3 update 7
- Dell 1850 双核至强处理器, 2GB内存, 75GB 15K硬盘
- 自定的LAMP软件应用
性能分析的步骤
1.我们从vmstat的系统性能“仪表盘”开始。
<font color="#000000"># vmstat 1 10
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 249844 19144 18532 1221212 0 0 7 3 22 17 25 8 17 18
0 1 249844 17828 18528 1222696 0 0 40448 8 1384 1138 13 7 65 14
0 1 249844 18004 18528 1222756 0 0 13568 4 623 534 3 4 56 37
2 0 249844 17840 18528 1223200 0 0 35200 0 1285 1017 17 7 56 20
1 0 249844 22488 18528 1218608 0 0 38656 0 1294 1034 17 7 58 18
0 1 249844 21228 18544 1219908 0 0 13696 484 609 559 5 3 54 38
0 1 249844 17752 18544 1223376 0 0 36224 4 1469 1035 10 6 67 17
1 1 249844 17856 18544 1208520 0 0 28724 0 950 941 33 12 49 7
1 0 249844 17748 18544 1222468 0 0 40968 8 1266 1164 17 9 59 16
1 0 249844 17912 18544 1222572 0 0 41344 12 1237 1080 13 8 65 13</font>
关键数据点:
-
- 内存的短缺并没有造成问题,因为并没有持续的swap(si和so)交换。即使空闲内存在减少,但swpd并没有改变。
- CPU并没有什么严重问题。就算有一些运行队列,但CPU仍然有超过50%空闲。
- 有大量的上下文切换(cs)和块正在被读入(bi)。
- CPU有平均20%的时间停顿着在等待I/O(wa)。
- 结论:初步的分析结果是I/O瓶颈。
2.使用iostat来确定是哪里创建的读请求
<font style="font-size: 9.8pt"><font color="#000000"># iostat -x 1
Linux 2.4.21-40.ELsmp (mail.example.com) 03/26/2007
avg-cpu: %user %nice %sys %idle
30.00 0.00 9.33 60.67
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 7929.01 30.34 1180.91 14.23 7929.01 357.84 3964.50 178.92 6.93 0.39 0.03 0.06 6.69
/dev/sda1 2.67 5.46 0.40 1.76 24.62 57.77 12.31 28.88 38.11 0.06 2.78 1.77 0.38
/dev/sda2 0.00 0.30 0.07 0.02 0.57 2.57 0.29 1.28 32.86 0.00 3.81 2.64 0.03
/dev/sda3 7929.01 24.58 1180.44 12.45 7929.01 297.50 3964.50 148.75 6.90 0.32 0.03 0.06 6.68
avg-cpu: %user %nice %sys %idle
9.50 0.00 10.68 79.82
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 0.00 1195.24 0.00 0.00 0.00 0.00 0.00 0.00 43.69 3.60 0.99 117.86
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda3 0.00 0.00 1195.24 0.00 0.00 0.00 0.00 0.00 0.00 43.69 3.60 0.99 117.86
avg-cpu: %user %nice %sys %idle
9.23 0.00 10.55 79.22
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/sda 0.00 0.00 1200.37 0.00 0.00 0.00 0.00 0.00 0.00 41.65 2.12 0.99 112.51
/dev/sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
/dev/sda3 0.00 0.00 1200.37 0.00 0.00 0.00 0.00 0.00 0.00 41.65 2.12 0.99 112.51</font></font>
关键数据点:
-
- 活动的仅仅是/dev/sda3分区。其余的分区都是完全空闲的。
- 粗略来看,有1200的读IOPS(r/s),但磁盘实际上只支持200IOPS左右。
- 在这两秒里面,并没有东西真正从硬盘上读东西(rkB/s),这与mstat看到的很高的I/O等待有关系。
- 大量的读IOPS与mstat中大量的上下文切换有关。有大量的读系统调用产生。
- 结论:有个应用产生了太多的读请求淹没了系统,超过了I/O子系统的处理能力。
3.使用top,确定哪一个应用是系统中最活跃的。
<font color="#000000"># top -d 1
11:46:11 up 3 days, 19:13, 1 user, load average: 1.72, 1.87, 1.80
176 processes: 174 sleeping, 2 running, 0 zombie, 0 stopped
CPU states:cpu user nice system irq softirq iowait idle
total 12.8% 0.0% 4.6% 0.2% 0.2% 18.7% 63.2%
cpu00 23.3% 0.0% 7.7% 0.0% 0.0% 36.8% 32.0%
cpu01 28.4% 0.0% 10.7% 0.0% 0.0% 38.2% 22.5%
cpu02 0.0% 0.0% 0.0% 0.9% 0.9% 0.0% 98.0%
cpu03 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 100.0%
Mem: 2055244k av, 2032692k used,22552k free , 0k shrd,18256k buff
1216212k actv,513216k in_d,25520k in_c
Swap: 4192956k av, 249844k used,3943112k free,1218304k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14939 mysql 25 0 379M 224M 1117 R 38.2 25.7% 15:17.78 mysqld
4023 root 15 0 2120 972 784 R 2.0 0.3 0:00.06 top
1 root 15 0 2008 688 592 S 0.0 0.2 0:01.30 init
2 root 34 19 0 0 0 S 0.0 0.0 0:22.59 ksoftirqd/0
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
4 root 10 -5 0 0 0 S 0.0 0.0 0:00.05 events/0</font>
关键数据点:
-
- 看起来mysqld进程占用了大量的资源。系统其余部分完全是空闲的。
- top报告的I/O等待(wa)是与vmstat里的wio相关的。
- 结论:这表示只有mysql是唯一请求系统资源的进程,因此可能就是它创建的大量读请求。
4.现在我们确定是mysql创建了这些读请求,使用strace来确定具体是什么样的读请求。
<font style="font-size: 9.8pt"><font color="#000000"># strace -p 14939
Process 14939 attached - interrupt to quit
read(29, "3123713663371222%42�����012P/d", 20) = 20
read(29, "ata1/strongmail/log/strongmail-d"..., 399) = 399
_llseek(29, 2877621036, [2877621036], SEEK_SET) = 0
read(29, "112413663371223%42�����012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 400) = 400
_llseek(29, 2877621456, [2877621456], SEEK_SET) = 0
read(29, "112353663371224%42�����012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 396) = 396
_llseek(29, 2877621872, [2877621872], SEEK_SET) = 0
read(29, "112453663371225%42�����012P/da", 20) = 20
read(29, "ta1/strongmail/log/strongmail-de"..., 404) = 404
_llseek(29, 2877622296, [2877622296], SEEK_SET) = 0
read(29, "3123623663371226%42�����012P/d", 20) = 20</font></font>
关键数据点:
-
- 有大量搜索产生的读请求,这表明mysql应用正在产生随机I/O。
- 看起来是有个特定的查询正在请求读操作。
- 结论:mysql应用正在执行某种读查询,因此产生了这所有的读IOPS。
5.使用mysqladmin命令,查看是哪个查询请求正占系统资源最大而且运行时间最长。
<font style="font-size: 9.8pt"><font color="#000000"># ./mysqladmin -pstrongmail processlist
+----+------+-----------+------------+---------+------+----------+----------------------------
| Id | User | Host | db | Command | Time | State | Info
+----+------+-----------+------------+---------+------+----------+----------------------------
| 1 | root | localhost | strongmail | Sleep | 10 | |
| 2 | root | localhost | strongmail | Sleep | 8 | |
| 3 | root | localhost | root | Query | 94 | Updating | update `failures` set
`update_datasource`='Y' where database_id='32' and update_datasource='N' and |
| 14 | root | localhost | | Query | 0 | | show processlist</font></font>
关键数据点:
-
- Mysql数据库看起来正在对一个叫’failures‘的表持续地运行update查询。
- 为了运行这个更新请求,数据库必须索引全表。
- 结论:由于这个更新请求,Mysql正在尝试索引全表的数据,这个查询所产生的读请求正在拖垮系统的性能。
性能后续跟进
性能监控的数据提交给了应用程序开发者,开发分析了PHP代码,发现了代码里一个不好的实现。指定的查询假设failure数据库只伸展到10万条 记录,但实际查询的有问题的数据库却有400万条记录。结果查询不能伸展到数据库的大小。因此其它任何查询(例如创建报告)都会卡在update查询之 后。
参考文献
- Ezlot, Phillip – Optimizing Linux Performance, Prentice Hall,
Princeton NJ 2005 ISBN – 0131486829
- Johnson, Sandra K., Huizenga, Gerrit – Performance Tuning for
Linux Servers, IBM Press, Upper Saddle River NJ 2005 ISBN 013144753X
- Bovet, Daniel Cesati, Marco – Understanding the Linux Kernel,
O’Reilly Media, Sebastoppl CA 2006, ISBN 0596005652
- Blum, Richard – Network Performance Open Source Toolkit,
Wiley, Indianapolis IN 2003, ISBN 0-471-43301-2
- Understanding Virtual Memory in RedHat 4, Neil Horman, 12/05
http://people.redhat.com/nhorman/papers/rhel4_vm.pdf
- IBM, Inside the Linux Scheduler,
http://www.ibm.com/developerworks/linux/library/l-scheduler/
- Aas, Josh, Understanding the Linux 2.6.8.1 CPU Scheduler,
http://josh.trancesoftware.com/linux/linux_cpu_scheduler.pdf
- Wieers, Dag, Dstat: Versatile Resource Statistics Tool,