七、赋值与运算符
定义两个变量,分别是a和b,a的值是10,b的值是20。
算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加,两个对象相加 | a+b=30 |
| - | 减,两个对象相减,可能会得到负数 | a-b=-10 |
| * | 乘,两数相称或是返回一个被重复若干次的字符串 | a*b=200 |
| / | 除,两个对象相除 | b/a=2 |
| % | 取膜,返回除法的余数 | b%a=0 |
| ** | 幂,返回x的y次幂 | a**b=100000000000000000000L |
| // | 整除余,返回商的整数部分 | a//b=0 |
比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于,比较两个对象是否相等 | a==b返回False |
| != | 不等于,比较两个对象是否不相等 | a!=b返回True |
| <> | 不等于,比较两个对象是否不相等 | a<>b返回True |
| > | 大于,比较x是否大于y, | a>b返回False |
| < | 小于,比较x是否小于y | a<b返回True |
| >= | 大于等于,比较x是否大于等于y | a>=b返回False |
| <= | 小于等于,比较x是否小于等于y | a<=b返回True |
赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | c=a+b,将a+b的运算结果赋值给c |
| += | 加法复制运算符 | c += a等效于c = c + a |
| -= | 减法复制运算符 | c -= a等效于c = c - a |
| *= | 乘法复制运算符 | c *= a等效于c = c * a |
| /= | 除法复制运算符 | c /= a等效于c = c / a |
| %= | 取模赋值运算符 | c %= a等效于c = c % a |
| **= | 幂赋值运算符 | c **= a等效于c = c ** a |
| //= | 取整除赋值运算符 | c //= a等效于c = c // a |
逻辑运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | “与” | a and b返回true |
| or | “或” | a or b返回true |
| not | “非” | no(a and b)返回false |
成员运算符
| 运算符 | 描述 |
|---|---|
| in | 如果在指定的序列中找到值返回True,否则返回False |
| not in | 如果在指定的序列中没有找到值返回True,否则返回false |
赋值语句的语法
| 运算 | 解释 |
|---|---|
| spam=’Spam’ | 基本形式 |
| spam, ham=’yum’, ‘YUM’ | 元组赋值运算 |
| [spam, han]=[‘yum’, ‘YUM’] | 列表赋值运算 |
| a,b,c,d=’spam’ | 序列赋值运算,通用性 |
| a, *b=’spam’ | 扩展的序列解包 |
| spam = ham = ‘hello’ | 多目标赋值运算 |
| spams += 42 | 增强赋值运算 |
实例
序列运算
>>> nudge = 1
>>> wink = 2
>>> A, B = nudge, wink
>>> A,B
(1, 2)
# 嵌套的方式
>>> ((a, b), c) = ('SP', 'AM')
>>> a, b, c
('S', 'P', 'AM')
扩展的序列解包
一个列表赋给了带星号的名称,该列表收集了序列中没有赋值给其他名称的所有项。
先定义一个seq序列用于测试:
>>> seq = [1, 2, 3, 4]
a匹配序列中的第一项,b匹配剩下的内容
>>> a, *b = seq
>>> a, b
(1, [2, 3, 4])
b匹配序列中的最后一项,a匹配序列中最后一项之前的所有内容
>>> *a, b = seq
>>> a,b
([1, 2, 3], 4)
第一项个最后一项分别赋值给了a和c,而b获取了二者之间的所有内容。
>>> *a, b, c = seq
>>> a,b,c
([1, 2], 3, 4)
带星号的名称可能只匹配单个的项,但是,总会向其复制一个列表,如果没有剩下的内容可以匹配那么会返回一个空列表:
>>> a,b,c,*d = seq
>>> print(a,b,c,d)
1 2 3 [4]
>>> a,b,c,d,*e = seq
>>> print(a,b,c,d,e)
1 2 3 4 []
多目标赋值语句就是直接把所有提供的变量名都赋值给右侧的对象
>>> a = b = c = 'As'
>>> a,b,c
('As', 'As', 'As')
# 所引用的值也都是同一个
>>> id(a),id(b),id(c)
(4331109208, 4331109208, 4331109208)
八、流程控制
if
if就是一个条件判断的,当满足不同样的条件的时候执行不同的操作,如法如下:
if <条件一>:
<条件一代码块>
elif <条件二>:
<条件二代码块>
else:
<上面两个或者多个条件都不满足则只需这里的代码块>
来一个小栗子:
#!/use/bin/env python
# _*_ coding:utf-8 _*_
# 只需脚本是让用户输入一个数字,并把值赋值给变量n
n = int(input("Pless Numbers: "))
# 如果n大于10
if n > 10:
# 输出n > 10
print("n > 10")
# 如果n等于10
elif n == 10:
# 输出n == 10
print("n == 10")
# 否则
else:
# 输出n < 10
print("n < 10")
三元运算
如果条件成立,那么就把值1赋值给var,如果条件不成立,就把值2赋值给var
var = 值1 if 条件 else 值2
例子
>>> var = "True" if 1==1 else "False"
>>> var
'True'
for循环
for语句是python中的循环控制语句,可用来遍历某一对象,还具有一个附带的可选的else块,主要用于处理for语句中包含的break语句。
>>> li = ['ansheng','eirc']
>>> for n in range(len(li)):
... print(li[n])
...
ansheng
eirc
enumrate
enumerate函数用于遍历序列中的元素以及它们的下标
例如定义一个列表,内容有电脑,笔记本,手机,组装机,执行脚本的时候让用户选择商品,并且给商品加上序列:
>>> li = ["电脑","笔记本","手机","组装机"]
>>> for key,value in enumerate(li):
... print(key,value)
...
0 电脑
1 笔记本
2 手机
3 组装机
为了给用户良好的体验,需要要从1开始,然后用户如果输出相对应的序列那么就打印出序列对应的值:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# 定义一个列表
li = ["电脑","笔记本","手机","组装机"]
# enumerate默认从0开始自增,我们可以改为从1开始自增
for key,value in enumerate(li,1):
print(key,value)
# 让用户选择商品的序列
li_num = input("请选择商品:")
# print输出的时候让序列减1
print(li[int(li_num)-1])
执行结果如下
1 电脑
2 笔记本
3 手机
4 组装机
请选择商品:1
电脑
range和xrange
range()函数返回在特定区间的数字序列,range()函数的用法类似切片:range(start,stop,setup),start的默认值为0,即从0开始,stop的参数是必须输入的,输出的最后一个数值是stop的前一个,step的默认值是1,setup是步长
>>> for n in range(5):
... print(n)
...
0
1
2
3
4
反向输出
>>> for n in range(5,-1,-1):
... print(n)
...
5
4
3
2
1
0
range在Python2.7与3.5的差别
python 2.7.11
>>> range(0,100)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
range在Python2.7中,会把所有的序列都输出出来,没一个序列都在内存中占用一点空间
xrange
xrang不会一次性把序列全部都存放在内存中,而是用到for循环进行迭代的时候才会一个一个的存到内存中,相当于Python3.5中的range。
>>> for i in xrange(1,10):
... print(i)
...
1
2
3
4
5
6
7
8
9
python 3.5.1
>>> range(1,100)
range(1, 100)
range在python3.5中就不会一次性的占用那么多空间,他会我需要用到这个序列的时候然后再内存中开辟一块空间给这个序列,不是一次性分完,相当于Python2.7.11中的xrange.
while循环
while循环不同于for循环,while循环是只要条件满足,那么就会一直运行代码块,否则就运行else代码块,语法如下:
while <条件>:
<代码块>
else:
<如果条件不成立执行这里的代码块>
小栗子
#!/use/bin/env python
# _*_ coding:utf-8 _*_
flag = True
while flag:
print(flag)
flag = False
else:
print('else', flag)
练习题
元素分类
有如下值集合 [11,22,33,44,55,66,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。 即: {‘k1’: 大于66的所有值, ‘k2’: 小于66的所有值}
图解流程:
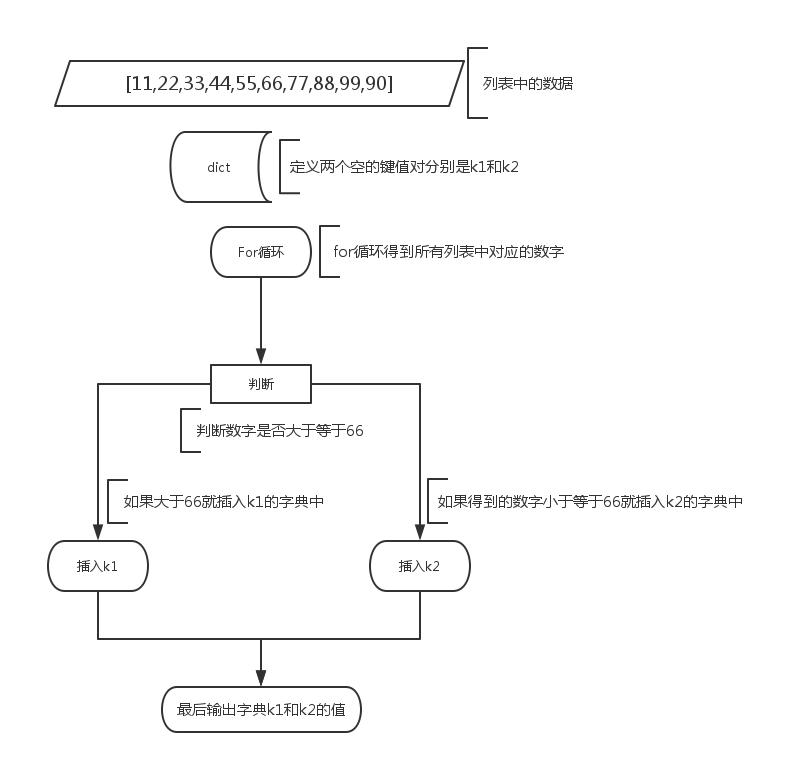
解答:
#_*_coding:utf-8_*_
num = [11,22,33,44,55,66,77,88,99,90]
dict = {
'k1':[],
'k2':[]
}
for n in range(len(num)):
if num[n] <= 66:
dict['k1'].append(num[n])
else:
dict['k2'].append(num[n])
print(dict.get("k1"))
print(dict.get("k2"))
- 输出结果
[11, 22, 33, 44, 55, 66]
[77, 88, 99, 90]
查找
查找列表中元素,移动空格,并查找以 a或A开头 并且以c结尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
- 列表的方式
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
li = ["alec", " aric", "Alex", "Tony", "rain"]
for n in range(len(li)):
# 去掉左右两边的空格然后输出内容并且把首字母换成大写
# string = str(li[n]).strip().capitalize()
# 把字符串中的空格替换掉,然后首字母转换成大写
string = str(li[n]).replace(" ","").capitalize()
# 判断如果字符串的开头是大写字母"A"并且小写字母是"c"就print输出
if string.find("A") == 0 and string.rfind("c") == len(string) - 1:
print(li[n],"--->",string)
输出的结果:
alec ---> Alec
aric ---> Aric
- 元组的方式
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
tu = ("alec", " aric", "Alex", "Tony", "rain")
for n in range(len(tu)):
# 去掉左右两边的空格然后输出内容并且把首字母换成大写
# string = str(li[n]).strip().capitalize()
# 把字符串中的空格替换掉,然后首字母转换成大写
string = str(tu[n]).replace(" ","").capitalize()
# 判断如果字符串的开头是大写字母"A"并且小写字母是"c"就print输出
if string.find("A") == 0 and string.rfind("c") == len(string) - 1:
print(tu[n],"--->",string)
输出的结果
alec ---> Alec
aric ---> Aric
- 字典的方式
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
dic = {
'k1': "alex",
'k2': ' aric',
"k3": "Alex",
"k4": "Tony"
}
for key,val in dic.items():
string = str(val).replace(" ","").capitalize()
if string.find("A") == 0 and string.rfind("c") == len(string) - 1:
print(key,val,"---",string)
输出的结果
k2 aric --- Aric
输出商品列表
用户输入序号,显示用户选中的商品
商品
li = ["手机", "电脑", '鼠标垫', '游艇']
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
li = ["手机", "电脑", '鼠标垫', '游艇']
for key,value in enumerate(li,1):
print(key,".",value)
li_num = input("请选择商品:")
print(li[int(li_num)-1])
执行结果
1 . 手机
2 . 电脑
3 . 鼠标垫
4 . 游艇
请选择商品:1
手机
购物车
功能要求: 要求用户输入总资产,例如:2000 显示商品列表,让用户根据序号选择商品,加入购物车 购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。 附加:可充值、某商品移除购物车
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
- 逻辑图
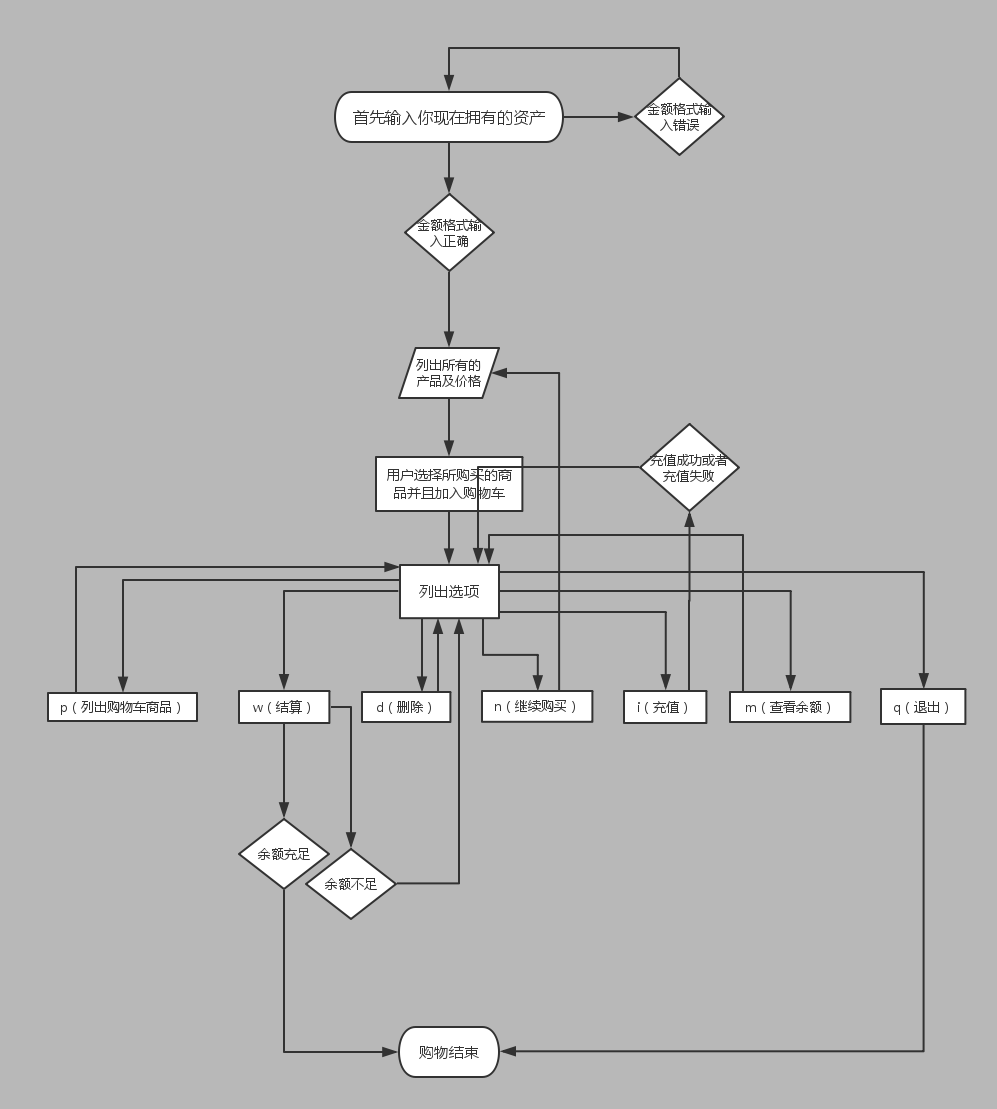
- 代码部分
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# 拥有的商品及价格
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
# 控制while循环开关
switch = "on"
# 购物车存放的商品及单价
gouwuche = {
# 商品列表
"wuping":[],
# 单价列表
"jiage":[]
}
# 用户输入会员卡内余额
while True:
try:
# 让用户输入会员卡内拥有的余额
money = int(input("请输入你会员卡内的余额:"))
# 异常判断,如果类型不是整型则执行except内的代码
except ValueError:
# 提示用户输入的格式错误,让其重新输入
print("error,余额格式输入错误,请重新输入!
例如:5000")
# 终端当前循环让循环重新执行
continue
break
# 进入购买商品的流程
while switch == "on":
# 打印出所有的商品
print("
","序列","商品","单价")
# 以序列的方式输出现拥有的商品及商品单价
for num,val in enumerate(goods,1):
for n in range(len(goods)):
if num-1 == n:
print(" ",num,goods[n]["name"],goods[n]["price"])
# 判断用户输入的序列是否规范
while True:
try:
# 输入产品序列,类型转换为整型
x = int(input("请选择商品序列:"))
# 如果用户输入的非整型,提示用户重新输入
except ValueError:
print("error,请选择商品的序列")
continue
# 如果用户输入的序列不再产品序列当中让用户重新输入
if x > num:
print("error,请选择商品的序列")
continue
break
# 输出购买物品的信息
print("你已经把商品",goods[x-1]["name"],"加入购物车","物品单价是:",goods[x-1]["price"],"
")
# 把物品名称放入gouwuche的wuping列表中
gouwuche["wuping"].append(goods[x-1]["name"])
# 把物品单价放入gouwuche的jiage列表中
gouwuche["jiage"].