一. 简单总结Linux系统模型的一些先验知识
1. Linux进程调度
1.1 进程控制块
Linux中进程/线程作为可被运行调度的实体都用task_struct来表示,所拥有的所有资源和信息都被记录在该结构体内,包括pid、运行状态、内核栈、内存资源、打开文件资源、接收到的信号等。mm_struct和file_struct等这类结构都包含有引用计数,可被多个进程共享;如fork时指定CLONE_VM标志,拷贝mm_struct指针并将usr引用计数+1,可让父子进程指向同一个mm_struct结构体,从而实现共享内存地址空间;指定CLONE_FILES可让两个进程共享同一个打开文件表,fd_table内的所有file对象引用计数+1。
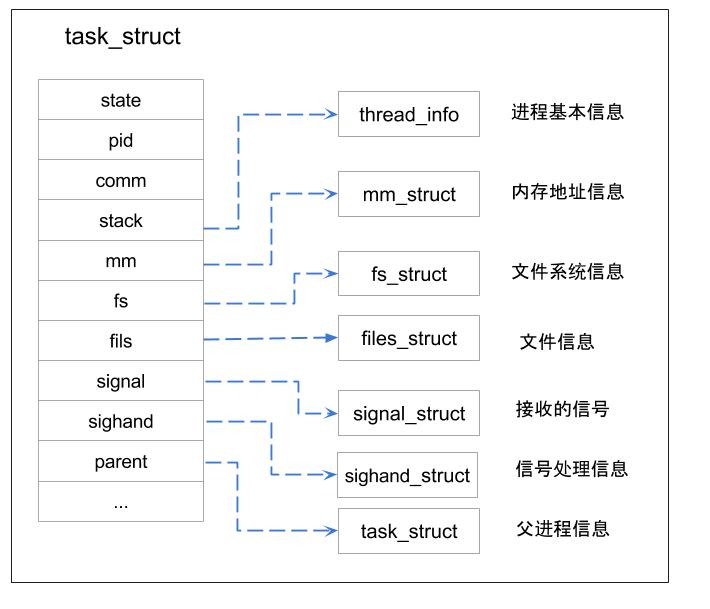
1.2 进程状态迁移
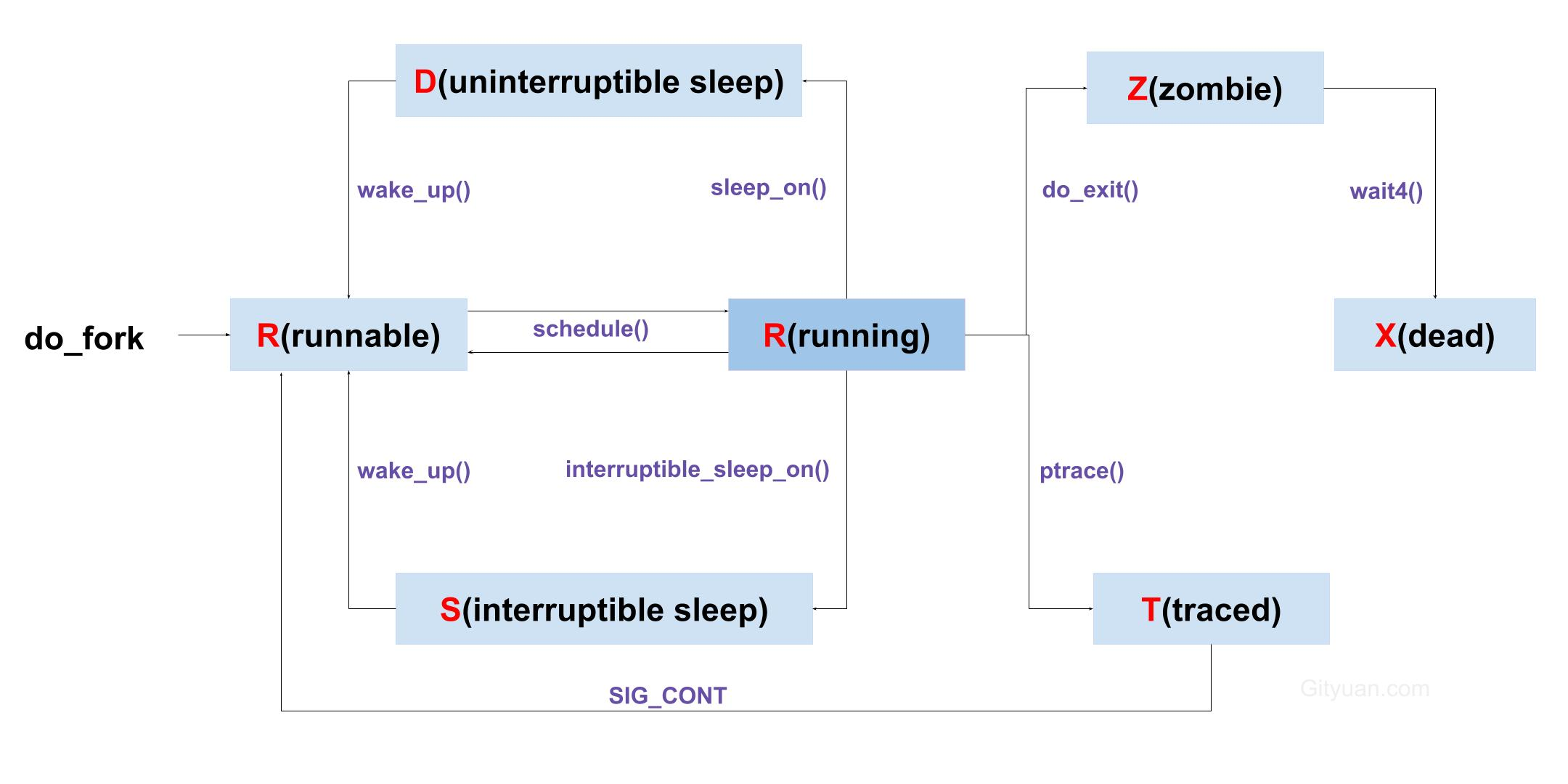
(1)TASK_RUNNING
一般来说除了0号进程task_struct是硬编码的以外,除此之外其他进程都由do_fork产生。do_fork执行完后进程即被设置好优先级和权重,处于TASK_RUNNING状态并被加入到运行队列中。
Linux通常会先选择一个进程,然后触发调度。触发调度主要有两种方式,一种是进程主动让出CPU;另一种是通过周期性的时钟中断触发,此时scheduler_tick()被调用,设置进程need_resched标志,当进程从内核态返回用户态时如果need_reshced被设置则会触发schedule()进行调度。
那么选择哪个进程进行调度呢?Linux实现了多种调度器类,用于完全公平调度和实时进程调度。调度算法包括课上讲的2.6.23版本前的使用140个不同优先级的运行队列的方式,也有之后版本使用CFS的方式。在此不具体展开。
schedule()函数主要就做两件事,一是swtich_mm,即将next进程的pgd装载到cr3寄存器,同时会自动刷新TLB表项;另一个是使用switch_to()切换内核态堆栈,完成进程上下文所需的指令寄存器状态切换,之后next进程从上一次switch_to()下一行代码继续执行。具体细节前面的博客写过了。
(2)TASK_INTERRUPTIBLE & TASK_UNINTERRUPTIBLE
当进程和慢速设备打交道或者等待某条件满足时,由于等待时间不可预估,这个时候内核会将其从CPU运行队列移除转到睡眠状态,即TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE。
两者区别在前者在等待条件满足或收到未屏蔽的信号时会回到TASK_RUNNING状态,而对于TASK_UNINTERRUPTIBLE只有等待条件满足才有可能返回运行状态,任何信号都无法打断它。
前面TASK_RUNNING的进程都被内核组织起来了,同样内核也用不同等待队列的方式将等待不同事件的进程组织起来。如sleep_on()函数将进程状态设置为TASK_INTERRUPTIBLE并插入到特定等待队列,然后调用schedule()重新选择另一个程序的执行。当睡眠唤醒时从等待队列中删除。
(3)TASK_ZOMBIE & TASK_DEAD
进程调用do_exit()后终止,内核删除对终止进程的大部分引用,包括与分页、文件系统、打开文件表和信号处理相关的一系列数据结构,相关引用计数-1,将task_struct的exit_code字段设置为终止代号。父进程调用wait()回收后进入TASK_DEAD状态,意味着在很短的时间内进程就将被释放。
2. Linux的内存管理
2.1 概述
Linux每个进程task_struct都拥有一个mm_struct结构,用于描述进程的虚拟内存。mm_struct中有以下几个重要的成员:
1.mmap,持有一系列vm_area结构,将进程线性地址空间所有可访问的虚拟地址区域串成一个链表,同时带有vm_flags标记读写执行权限。当进程访问vm_area指向区域时可能还没有分配相应的物理页面并建立好虚拟内存映射,这时会产生缺页异常,内核为新的虚拟内存区分配实际的物理内存。
vm_area有以下种类:
- 和文件相关的 VMA: 代码/库, 数据文件, 共享内存, 设备; 这些 VMA 的内容都是来至于文件的.
- 匿名 VMA: Stack, Heap, CoW pages; 这些 VMA 的内容都是用户程序管理的.
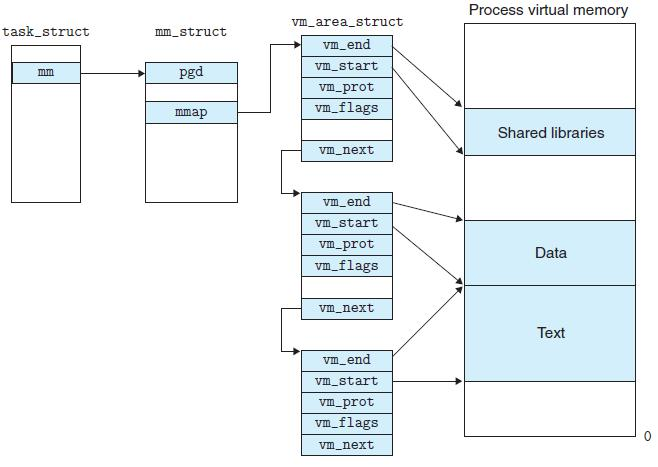
2.PGD(Page Global Directory),存放本进程第一级页表(页全局目录)的基地址。
Linux内核使用四级页表PGD->PUD -> PMD->PTE来管理虚拟地址到物理地址的映射,一般来说,虚拟地址到物理地址的转化由MMU自动完成。36位虚拟页号VPN被划分为四个9位的片,每个片被用作一个页表的偏移量。CR3寄存器包含一级页表的物理地址。VPN1提供一级页表的偏移量,VP2提供VPN1指向的二级页表偏移量,以此类推。

3.mmlist. 所有进程的内存描述符存放在mmlist字段组成的双向链表中,链表的第一个元素 init_mm是0号进程的mm_struct结构。
2.2 Linux缺页处理
假设MMU在试图翻译某个虚拟地址时发现没有对应的物理页框,会触发一个缺页。这个异常导致控制转移到内核的缺页处理程序,缺页处理程序随即进行判断:
根据vm_area链表或红黑树判断该虚拟地址是否在线性区间内,或是否为用户态堆栈,如果不是则产生段错误
根据访问权限判断对该内存的访问是否合法,如果不合法也产生段错误,如果合法则请求分页并更新页表,当缺页处理程序返回时CPU重新执行引起缺页的指令,该指令引用的地址再次被送到MMU,此时能够正常翻译了。
3. Linux文件系统
Linux为上层用户提供了一个统一的、抽象的界面来访问文件系统,ext4等实际的文件系统想要被Linux系统支持就必须实现符合VFS标准的接口,才能与VFS协同工作。每次open一个文件都会创建一个file对象,如果使用dup()或fork()则一个或多个进程file_sturct的fd_array条目可以指向同一个file对象;file对象中的f_op被设置成指向某个具体文件系统所系统的一组操作函数;file对象中还保存了文件的读写位置,并保存了指向该文件的inode指针,将inode串成双向链表构成系统inode表。所以整体上是每个进程的文件描述符fd数组中的条目指向系统存储file对象的表,file对象指向inode表中的条目。

二. 提炼精简的Linux系统概念模型
Linux系统启动时以代码中写死的0号进程为模板,通过do_fork()创建1号init/systemd进程,以及2号进程kthreadd内核线程。我们所有的例如shell、桌面环境等都由1号进程fork和execve创建。fork会为新进程分配pid,复制出一个task_struct结构,execve为堆栈、text段、数据段等分配新的线性区,插入到进程地址空间,与磁盘上的可执行文件相应区域建立映射关系。基本的执行上下文被构建出来后最终会跳转到用户程序入口点运行。
假设我们的用户程序执行了read()函数来读磁盘上的一个文件,则简要过程如下:
由于read会调用sys_read系统调用(假设使用INT 80H),因此会发生中断上下文切换,包括:
从idtr寄存器找到IDT,根据传入的128号向量找到中断描述符表项;该表项在内核初始化期间调用函数trap_init()将门描述符填充进了该表项,该门描述符段选择符为KERNEL_CS,offset为指向system_call系统调用处理程序的指针,DPL为3即允许用户态进程调用该异常处理程序。
拿到门描述符后获取其中保存的段选择符,根据gdtr寄存器找到GDT,用段选择符查到表中相应段描述符。
CPU使用CS寄存器中的CPL特权级与门描述符中的DPL特权级比较,CPL>=DPL时通过检查,否则产生保护异常。
检查通过,特权级发生变化 ,CPU会自动帮忙切换不同特权使用的寄存器。
从tr寄存器获取该CPU上的tss段,从中取出当前进程的内核态堆栈指针和ss寄存器并将它们装载到ss和esp寄存器。
保存当前进程用户态ss寄存器和eip寄存器值,再保存用户态eflags、cs和eip的值。
从刚才中断向量表的门描述符中取出offset并装载到eip,进入system_call函数。
system_call()首先将系统调用号和这个异常处理程序需要用到的所有寄存器保存到相应的栈中。
随后检查系统调用号,并根据eax中的系统调用号在sys_call_table中查找对应的系统调用服务例程,这里调用了sys_read()
根据fd查找task_struct->file_strutc中的file对象,调用其f_op(初始化inode时已经赋值),即vfs的read,如果是ext文件系统会调用do_sync_read()。
如果未指定O_DIRECT则根据文件当前读写指针位置查找Page Cache,若page已是最新则将请求数据拷贝到用户空间。否则调用readpage()向磁盘发出添页请求。
由于磁盘是慢速设备,磁盘驱动器会为读磁盘块的请求设置一个等待队列,将我们的进程加入该队列,状态设置为TASK_INTERUPTIBLE;内核调用schedule()重新选择其他进程运行。
其他进程执行期间磁盘会发生中断请求,CPU暂停当前进程执行并在当前进程中断上下文中进行磁盘中断处理,磁盘驱动器中的数据被送入内存。
VFS调用wake_up()唤醒前述等待队列上我们的进程,进程状态重新变为TASK_RUNNING。
此时我们的进程处于TASK_RUNNING状态,被置于可运行队列中,等待被Linux调度器调度算法选中。若很幸运地被选中运行,会加载它的页表项,重新切换到它的内核堆栈,恢复内核栈中压的寄存器上下文,继续运行schedule()后的代码。
之后函数sys_read()可以返回了,最终read系统调用也返回,重新执行我们的用户态代码。
三. 课程学习体会
记得三月份找实习时面试官曾经问过我:“进程和线程有什么区别”? 那时我的回答无非就是人云亦云的“线程间共享虚拟地址空间,线程上下文切换开销小...”之流。而学习完孟老师和李老师的Linux课,读过源码了解原理后,我能从更深层次的角度回答:"线程间共享虚拟地址空间是因为linux中线程也是用do_fork创建,调用时指定了CLONE_VM参数,do_fork中的copy_process()将主线程的mm_struct结构体指针赋值给子线程,同时引用计数+1,因此两个线程有共同的pgd和vm_area线性地址区,从而共享虚拟地址空间。"以及“线程上下文切换开销小主要由于schedule()函数执行switch_mm()时,函数体中判断prev->mm和next->mm一致,因此不会重新装载页表到cr3,也就不会刷新TLB...”。虽然那时也找到了满意的实习,但现在,以及未来校招,我觉得我能和面试官更加愉快地吹逼了。虽然疫情在家早上上课有时候起不来,但还是差不多补完了也顺便学习了下《深入理解Linux内核》这本书相应章节。我作为一个经常在Linux下做C++开发的程序员,我觉得这是我入学以来选过的最有用的课之一。