1、分析url
《空港双流》数字报刊,访问地址为:http://epaper.slnews.net.cn,现在为了抓取每篇新闻的网页内容。
在浏览器访问该链接后,发现链接出现了变化,看样子是后端服务器进行了重定向:
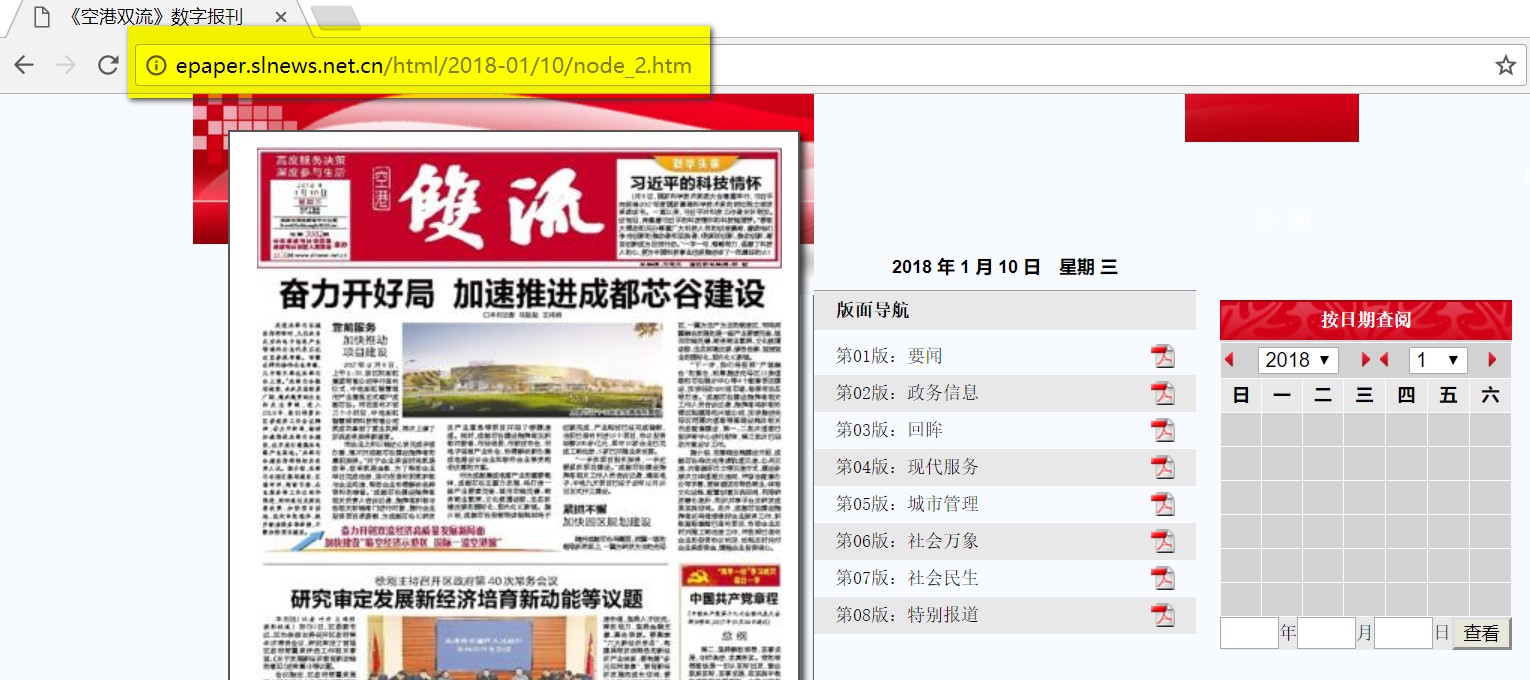
观察该链接,发现定向链接规则显然是包含日期规则,2018-01/10,表示2018年01月10日的报刊,也就是定位为当天的日期,试着修改为前一天,即2018-01/09,页面果然发生了跳转,没问题。跳转到第二天,即还没有到来的11号,页面显示未找到。
从页面结构可以看到,报刊分为按版面分区,每个版面下包含不同的文章:
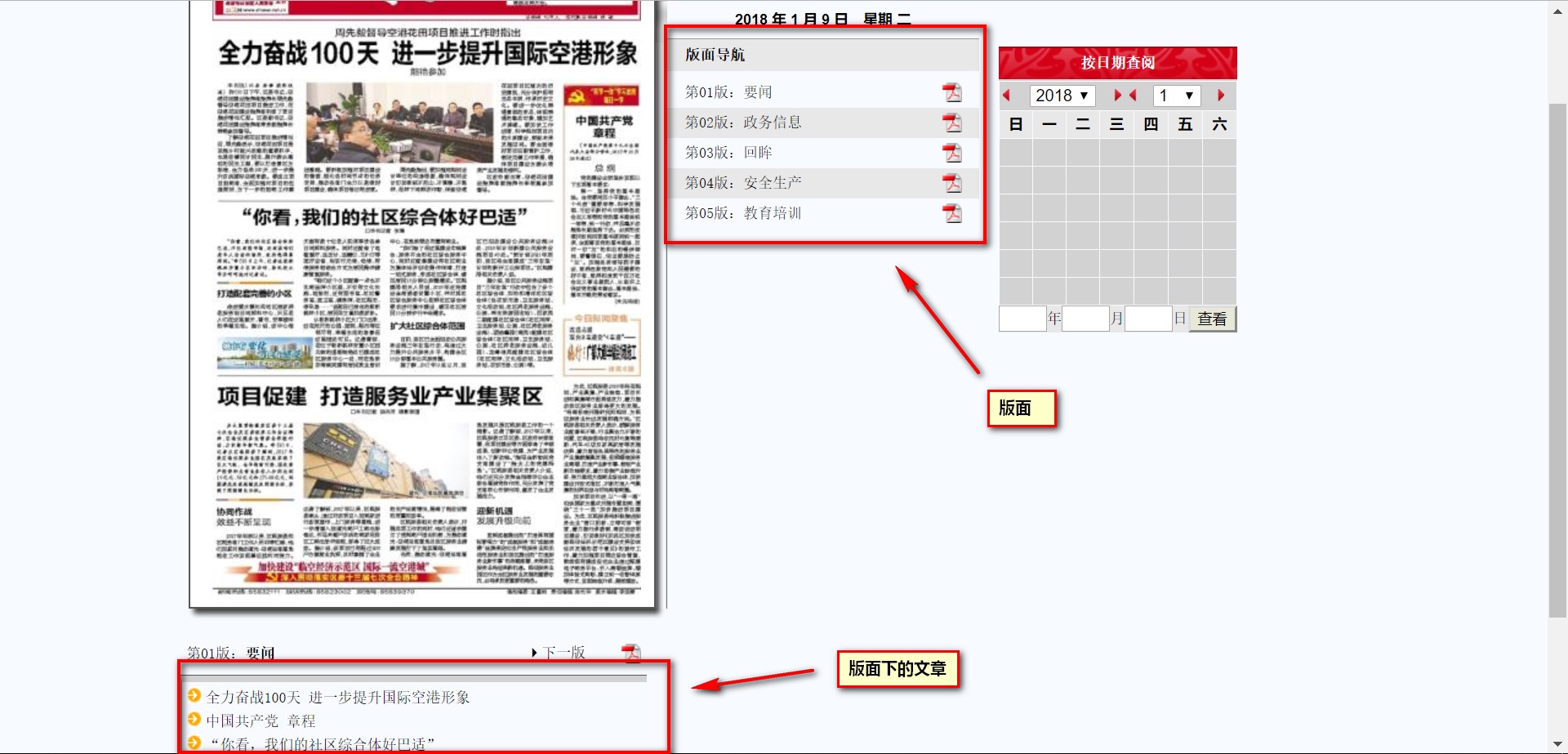
用浏览器调试查看一下网页源码,可以看到版面部分的链接结构为node_?.htm,而文章部分的链接结构是content_?.htm形式(?指代数字):
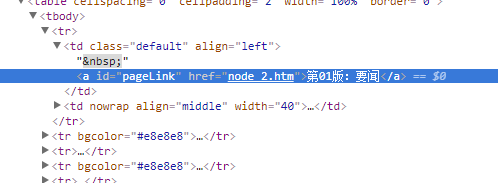

那么显然思路就有了:
- 先得到所有版面的url
- 访问版面网页并抓取其中的所有文章的url
- 最后访问文章url就可以得到新闻网页内容了
2、代码部分
根据爬虫的基本原理,先写一个返回指定url的网页内容的方法:
public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}57
1
public class CrawlerUtil { 2
3
/**4
* 获取主网页的内容5
*6
* @param url 网页url7
* @param requestMethod 请求方式8
* @param refer post内容9
* @return 网页内容10
*/11
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {12
refer = refer == null || "".equals(refer) ? null : refer;13
StringBuffer buffer = new StringBuffer();14
try {15
//建立连接16
URL requestUrl = new URL(url);17
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();18
connection.setRequestMethod(requestMethod.getValue());19
switch (requestMethod) {20
case GET:21
connection.connect();22
break;23
case POST:24
if (refer != null) {25
OutputStream out = connection.getOutputStream();26
out.write((refer.getBytes("UTF-8")));27
out.close();28
}29
break;30
default:31
break;32
}33
//获取网页内容34
InputStream in = connection.getInputStream();35
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");36
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);37
String str = null;38
while ((str = bufferedReader.readLine()) != null) {39
buffer.append(str);40
}41
//关闭资源42
bufferedReader.close();43
inputStreamReader.close();44
in.close();45
in = null;46
connection.disconnect();47
48
} catch (MalformedURLException e) {49
e.printStackTrace();50
} catch (IOException e) {51
e.printStackTrace();52
}53
54
return buffer.toString();55
}56
57
}观察链接,发现其变动的实际上就两个部分,日期和最后部分node或content,那么写一个获取链接的方法:
/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}21
1
/**2
* 双流新闻网地址3
*/4
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";5
6
/**7
* 获取特定日期的新闻网的版面地址url8
* <p>9
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_210
* </p>11
*12
* @param date 日期13
* @param factor 板面,形式为node_?14
* 文章,形式为content_?15
* @return 新闻网地址url16
*/17
public static String takePageUrl(Date date, String factor) {18
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");19
factor = factor == null ? "node_2" : factor;20
return String.format(NEWS_URL, format.format(date), factor);21
}获取到的网页内容中,根据网页代码结构,使用正则来匹配获取我们想要的内容,先写一个通用的匹配方法:
/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}21
1
/**2
* 获取内容匹配的元素集合3
*4
* @param content 网页内容5
* @param reg 匹配正则6
* @return 元素集合7
*/8
private static List<String> takeElementList(String content, String reg) {9
log.debug("start take elements from content by Reg");10
List<String> list = new ArrayList<String>();11
//定义正则规则12
Pattern pattern = Pattern.compile(reg);13
Matcher matcher = pattern.matcher(content);14
while (matcher.find()) {15
String element = matcher.group(1);16
list.add(element);17
log.debug(element);18
}19
log.debug("take elements end");20
return list;21
}那么主要的就很简单了,获取node版面的集合,获取content文章的集合,这里主要需要注意的是正则的书写:
/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\d+?)\.htm>.*?<\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\d+?)\.htm>";
return takeElementList(content, reg);
}x
1
/**2
* 获取特定日期新闻网的版面链接元素3
*4
* @param date 日期5
* @return 版面链接的元素集合6
*/7
public static List<String> takeNodeUrlEleList(Date date) {8
String url = takePageUrl(date, null);9
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);10
String reg = "<a id=pageLink href=.*?(node_\d+?)\.htm>.*?<\/a>";11
return takeElementList(content, reg);12
}13
14
/**15
* 获取指定日期指定版面的所有文章链接元素集合16
*17
* @param date 日期18
* @param node 版面元素,格式为node_?19
* @return 文章链接的元素集合20
*/21
public static List<String> takeNewsUrlEleList(Date date, String node) {22
String url = takePageUrl(date, node);23
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);24
String reg = "<a href=.*?(content_\d+?)\.htm>";25
return takeElementList(content, reg);26
}那么获取新闻文章网页内容的方法也就无非是上面两个的嵌套循环:
/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}1
/**2
* 抓取指定日期新闻页面内容集合3
*4
* @param date 日期5
* @return 新闻页面内容6
*/7
public static List<String> takeNewsPageList(Date date) {8
log.info("start crawl news page content. date:" + date);9
List<String> newsList = new ArrayList<String>();10
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);11
for (String nodeEle : nodeEleList) {12
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);13
for (String newsEle : newsEleList) {14
String url = NewsCrawler.takePageUrl(date, newsEle);15
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);16
newsList.add(content);17
}18
}19
log.info("crawl news page content end. page amount:" + newsList.size());20
return newsList;21
}接下来,可以再根据需要对内容进行进一步的加工,因为获取的新闻文章网页内容也包含了太多我们完全不需要的内容和html代码,比如我们只需要网页内容的新闻部分,那么就再通过查看该html代码结构,使用正则表达式继续提取即可。
大概就是这个样子,大功告成,一个简单的示例。