在入正题之前我们再回顾下它的架构图:

本文章主要分析AMP各索引的作用,与及结合1.7环境上已接入的服务数据对比后,对索引中的主要字段进行解析。文章分为四个小章节。
1、索引类型
apm索引分为四种类型:
系统指标索引(System status metrics),索引名称格式:apm-version-metric-yyyy.dd.mm,主要储存进程资源指标,如:内存信息、cpu信息、gc信息等。
具体异常索引(Error-specific data),索引名称格式:apm-version-error-yyyy.dd.mm,主要存储进程error级别的经过json格式化后的异常信息栈。
跨度(或链路)索引(Span-specific data),索引名称格式:apm-version-span-yyyy.dd.mm,主要存储跨本进程调用链的信息,如:代码执行链、跟踪id,跨度id,跨度类型、跨度用时等。特别指出的是这个索引的数据是形成整个事务、链路的一部分。
事务索引(Transaction-specific),索引名称格式:apm-version-transaction-yyyy.dd.mm,主要存储事务的持续时间,单位微妙(PS:这里的事务跟TPS同一个概念:指一个客户机向服务器发送请求到服务器做出相应的过程,这里除了客户机请求之外,还包括内部的执行任务,如:定时任务),如:进程id,TPS值,事务类型,发生时间,请求接口。
ps:以下标红字段是个人认为比较有价值的字段。
2、索引字段说明
这些索引中,有很多字段都是公共的,所以我在其中某个索引中提及到了,在其它索引就不再单独做说明项了。
2.1、系统指标索引
jvm.memory.non_heap.committed
java进程非堆的内存空间可用大小,单位是bytes。针对jdk8以上就是元空间大小。
jvm.memory.non_heap.max
java进程非堆的内存空间最大值,单位是bytes。针对jdk8以上就是元空间最大值。由系统参数:MaxMetaspaceSize设置
jvm.memory.heap.max
java进程堆内存最大值,由系统参数-Xmx设置
jvm.memory.heap.used
java进程堆内存使用量,单位字节
jvm.memory.heap.committed
java进程堆可用内存大小,它的值一般为大于或等于已使用大小,小于等于最大内存空间,小于是因为Xms与Xmx设置不一样,为了系统内存不波动,建议设置初始值和最大值一样。
jvm.memory.non_heap.used
java进程非堆已使用大小
jvm.thread.count
JVM中当前活动线程的数量
jvm.gc.alloc
代码中是计算java进程所有线程使用的内存总量(包括已死去的线程),但是字面理解是堆内存中分配的内存总量相当于heap.max,个人认为性能调优上没什么参考价值
process.pid
对应的终端进程id
代表事件类型:metric
processor.event
代表事件类型:metric
process.title
jdk安装目录
对应的终端服务名称,就是elastic.apm.service_name参数指定的值
运行环境,如是java进程该值就是java
service.runtime.version
jdk版本
host.ip
终端进程所有服务器ip
jvm.gc.count
jvm垃圾收集次数
jvm.gc.time
每次GC使用时间,单位是毫秒
GC方式:如G1 Young Generation或G1 Old Generation
@timestamp
收集时间
system.process.memory.size
进程占用的虚拟内存
system.process.cpu.total.norm.pct
自上次上报以来该进程占用CPU的百分比。需要乘以100%。
system.cpu.total.norm.pct
自上次上报以来终端所在的机器当前cpu的使用率,需要乘以100%
system.memory.actual.free
操作系统当前可用内存(字节),由空闲内存加缓存和缓冲区组成
system.memory.total
操作系统总内存
字段使用分析:
从以上索引字段解析可以让我们实时了解该进程所在机器的ip、当前cpu的使用率、内存使用率、被监控进程的堆、非堆内存分配情况、内存使用率、cpu使用率、GC次数、GC使用时间、GC类型。比如:生产上内存分配一般是4GB,如果分配低于1GB我们可以当成一项告警指标,知道了配置的总内存和使用内存,又可以算出内存使用率,那么当内存使用率达到90%即可做出告警事件,GC使用时间、频率。GC的用时和频率没有什么标准来衡量,根据服务实际情况来优化,能满足当前需求和体验感能接受即可,但以我们目前服务部署的情况来分析,高发很少突破100以上的情况下,每个服务内存都不超过4GB的,比较合理的YGC一分钟内不能超过10次,每次不能超过20毫秒,FGC应该0次出现。可以以这个目标来优化靠拢。(下次我会写一篇关于G1里为什么能让我们指定时间内完成GC——启发式算法)
2.2、异常索引
指向父节点的id,意思是上个服务请求的标识id,用于服务之间异常调用链路跟踪
事务id,这里的事务不是数据事务,代表一个完整的请求流程或一个内部任务。用于异常事件链路跟踪,结合数据看与parent.id值相同,说明代表服务id并不是固定死
error
异常栈
error.exception.message
抛出的异常信息,如:xxx属性为空、500 Server Error、The user specified as a definer ('test_seq'@'%') does not exist
error.exception.type
异常类型,如:java.lang.RuntimeException、com.segi.uhomecp.ifs.activiti.exception.WorkFlowException、java.sql.SQLException
error.culprit
异常发生的根源,就是哪个类里的哪个方法哪行代码发生的异常。如:com.segi.uhomecp.redis.RedisUtil$18.execute(RedisUtil.java:444)
此次异常事件的标识id
error.grouping_key
异常分组id,按error.exception.type分组
processor.name、processor.event
事件类型和名称是同个东西,就是代表span、error、还有metris
observer.hostname
apm服务的主机名
observer.type
默认都是apm-server
observer.version
apm服务版本号
observer.version_major
apm服务主版本号
跟踪id
host.hostname
被监控的终端服务主机名
transaction.type
此事代码被执行的方式,意思是被http请求还是内部执行的定时任务。如:request、scheduled
transaction.sampled
监控数据事件是否包含跨度、上下文等全部相关信息,默认是true
事件发生时间,微妙
url.path
接口uri,如:/lease-stat/admin/businessSummary/list
url.scheme
url类型,如果是http.其值就是:http,非http为空
url.port
接口对应的端口
url.domain
接口对应的ip或域名
url.full
接口完整url
http.request.method
请求方式,get或post,非http为空
http.response.status_code
http相应状态码,如:500
还有些一些用户http请求的信息字段,如:浏览器,用户终端类型,http版本等。
数据结构图:

字段使用分析:
好了,经过我们分析了这个索引的核心相关字段后。就可以知道这个索引能给我们解决什么问题了,首先最有价值的是error异常栈,我们码农级别最喜欢看的东西都这error doc里,从异常栈我们可以分析出错的原因,error.culpri触发异常的地方,除了这些信息我们从中还可以知道:异常接口、异常的服务进程、异常服务ip、http异常状态码、关连的异常链路。
2.3、跨度索引
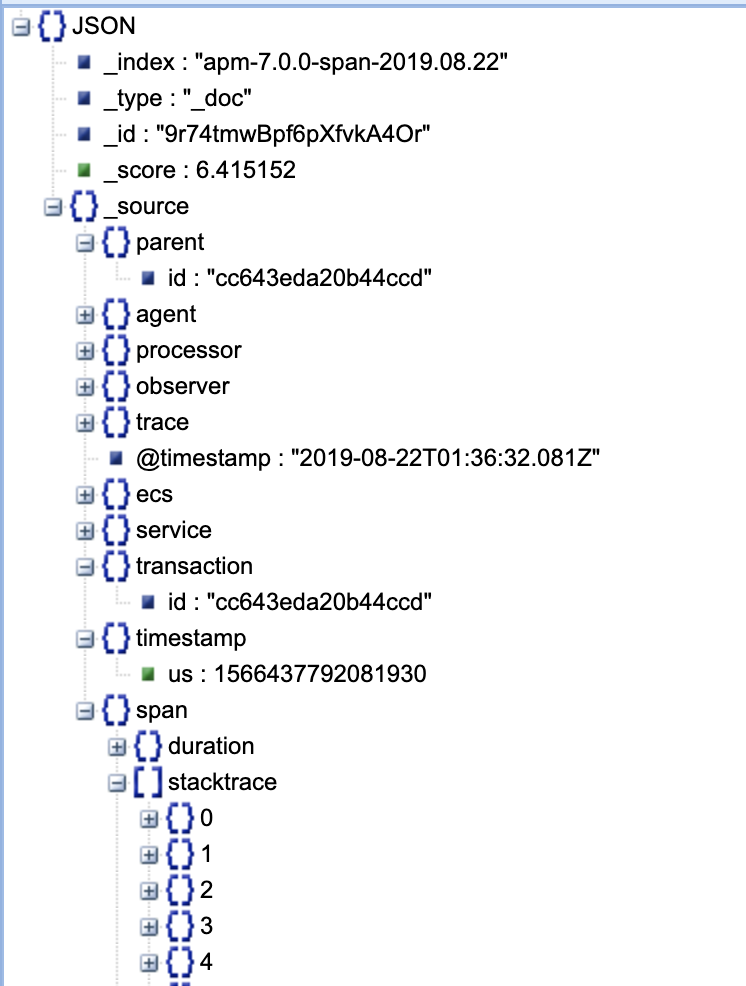
跨度标识
span.stacktrace
这个是跨度调用链,记录了调用的文件名,调用行,调用方式等信息
跨度耗时,单位微妙,这个时间是记录span.stacktrace内调用栈的用时。跨度是什么意思呢? 是指除了本进程内调用之外都算是跨度调用,比如:数据库操作、调ice等
span.type
跨度类型,数据库就是db,http就是external,相对subtye,它细粒度大些。
span.subtype
跨度调用子类型,有http、mysql、tcp(占不支持)等
给这个跨度调用取的简单名称。如:SELECT FROM ACT_RU_EXECUTION、SELECT、POST 192.168.1.7
span.action
跨度事件类型,像数据库查询,类型就是query
字段使用分析:
这个索引最有价值的调用链了:span.stacktrace和执行过程中所花的时间。
2.4、事务索引

整个流程的处理时间,单位微妙,这个时间包含了跨度时间在内
整个事务的名称,用接口名、方法入口名来命
span_count
记录跨度数
字段使用分析:
transaction.duration.us是整个请求过程所使用的时间,可以根据这个时间推断出指定该接口所在的服务,所属的进程的性能,还有schemes类型,根据这个可以判断是不是http请求,这个索引的数据主要是结合跨度索引一起使用。
3、实践应用
经过了一翻上报索引数据的分析后,我们来实践一下。
- 首先为每个接入服务名称定义规范
apm监控是以进程为目标。如果要接入多个服务的情况下,要分辩某个或哪些服务是做什么的,比较难辨别出来了。所以需要为每个接入监控服务的名称统一定义一个命名规范。
所以我们统一规定服务监控名称格式为(服务名称必须符合此正则表达式:^[a-zA-Z0-9 _-]+$. 用较少的regexy术语:您的服务名称只能包含ASCII字母,数字,短划线,下划线和空格中的字符):segi-环境-业务组名称-服务名称-服务所在的机器ip,如:segi-saas-lease-uhomecp-lease-220。
现成的界面指标分析
- 默认主界面(services):
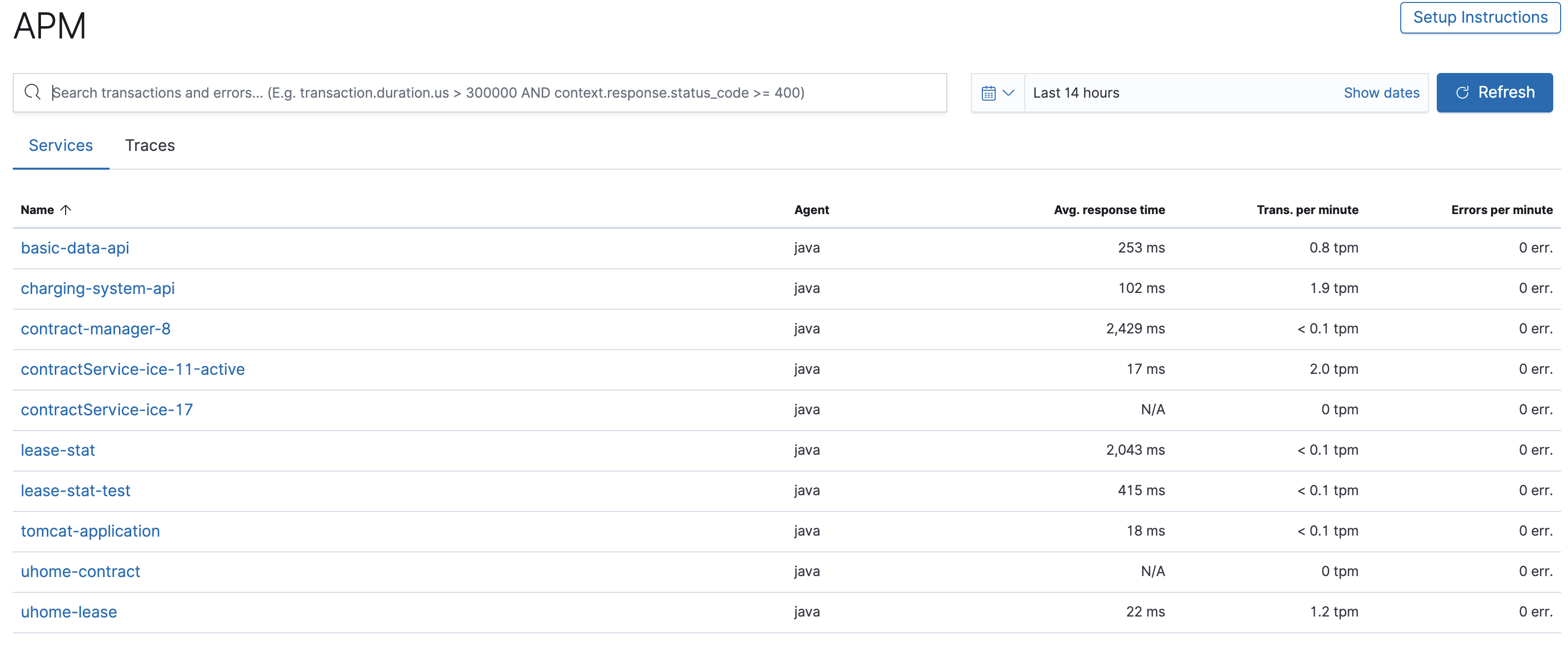
-
说明:第一列是被监控的服务名称,就是对应上面我们给他命的名称 ;第二列被代监控的环境;第三列是每个监控服务平均响应时间(对所有请求作出响应所需要的时间平均值,其接近于所有TPM总和的平均);每三列是每分钟事务处理数;第四列是每分钟发生异常数。
在这顺便科普下几个衡量一个服务的性能指标:TPS、并发数、响应时间
TPS:每秒传输的事物处理个数,即服务器每秒处理的事务数。包括一条消息入和一条消息出。
并发数: 系统同时处理的request(或事务)数
响应时间: 对请求作出响应所需要的时间,一般取平均响应时间(响应时间:网络传输时间:N1+N2,应用服务器处理时间:A1+A3,数据库服务器处理时间:A2,响应时间=N1+N2+N4+A1+A3+A2)
这三者之间的关系:并发数 = TPS*平均响应时间有用指标:平均响应时间:从这个直接看出服务的性能等级:毫秒级别的响应属于非常有吸引力的用户体验;2秒之内给用户是不错的体验;3秒之内可以接受;5秒之内遭用户叹气;10秒之内60%用户不使用;大于10秒90%以上用户选择离开。
EPM:直接反映服务使用稳定性,出现error直接影响服务的使用。
- traces界面
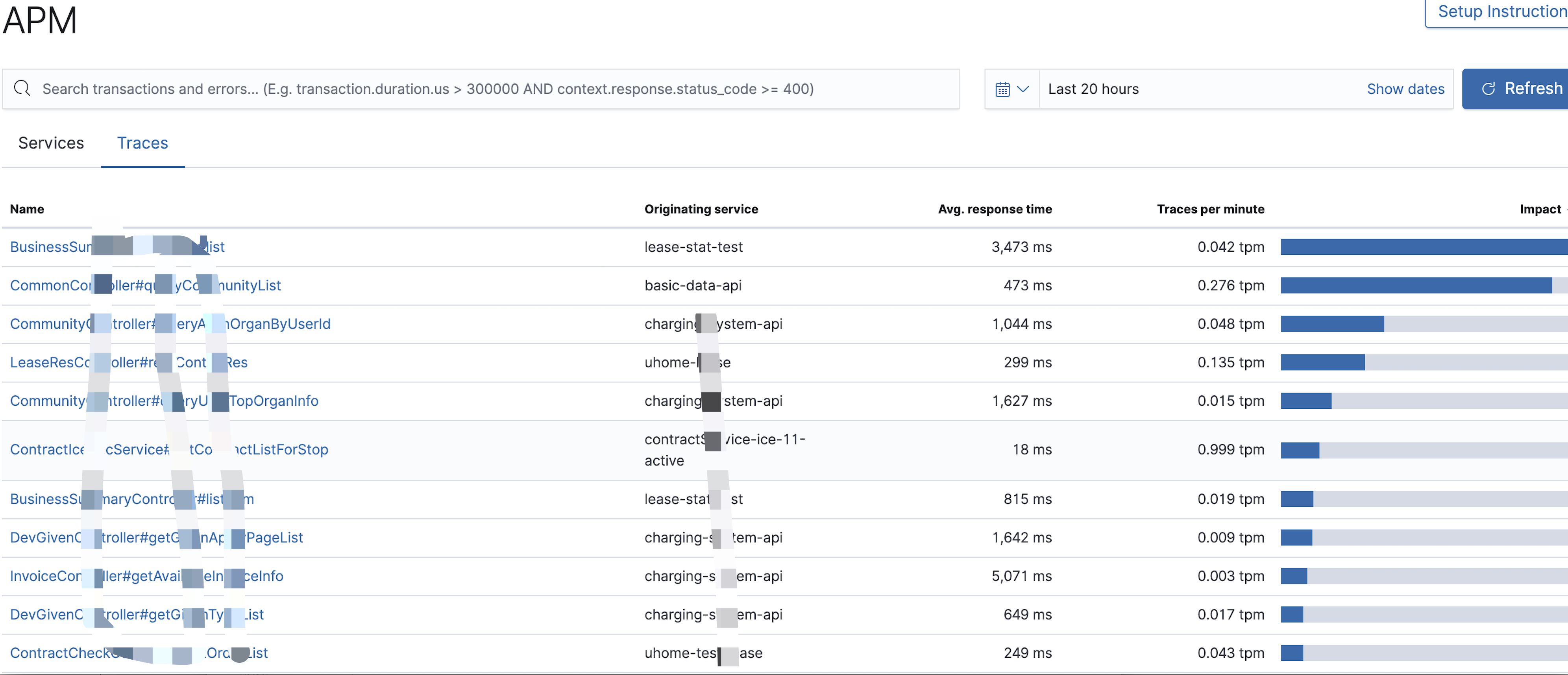
说明:这个链路界面跟服务界面指标差不多。展示的是所有服务的所有http接口的响应时间、TPM、接口访问频率
有用指标:平均响应时间 - 服务界面
图一: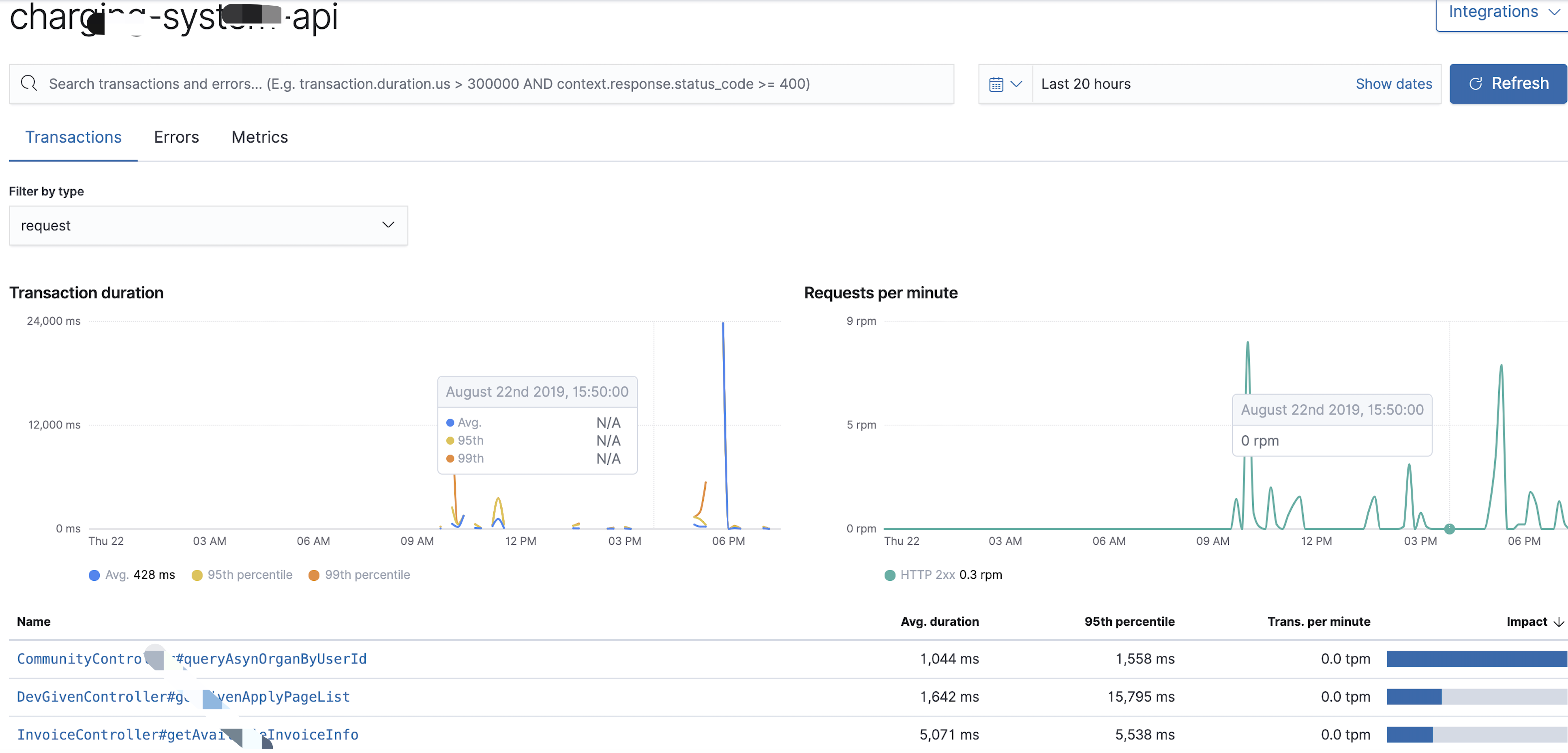
图二: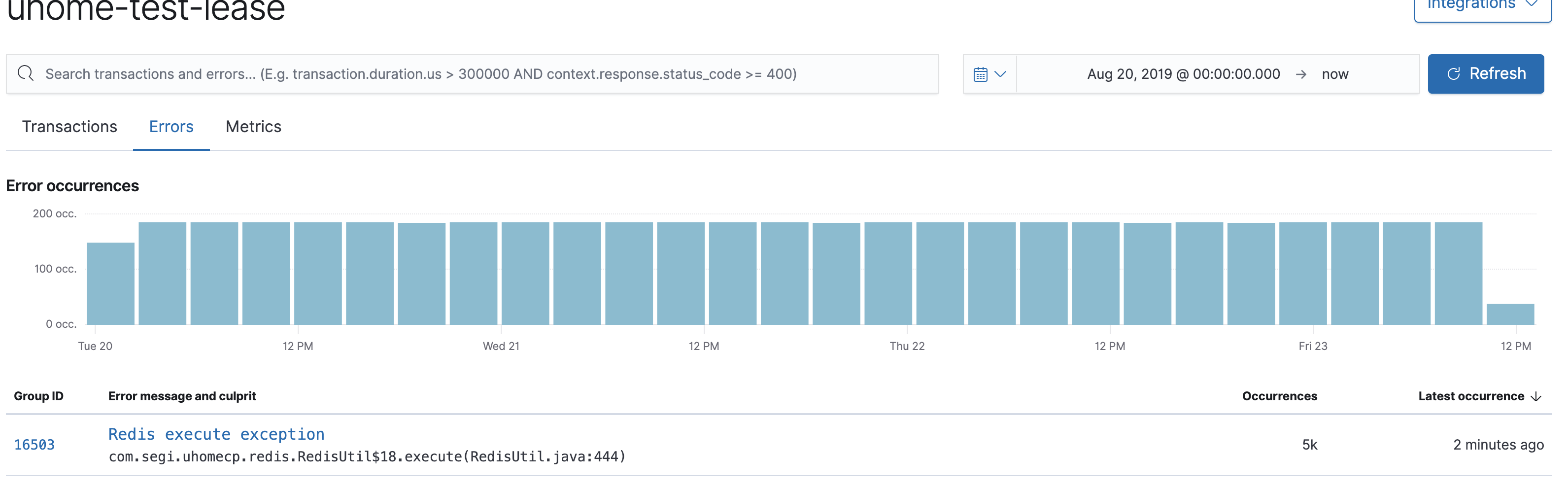
图三: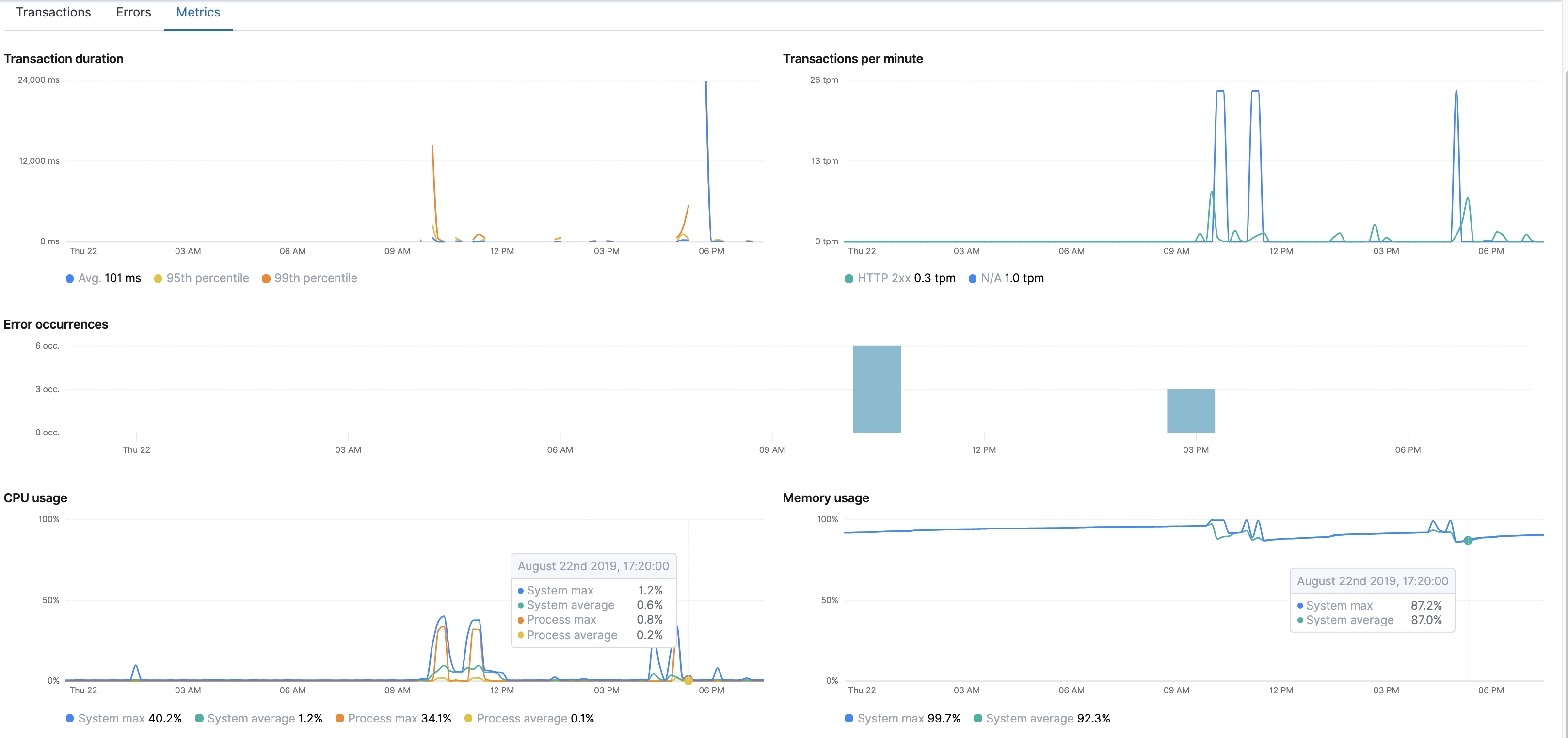
说明:图一,服务的事务监控,可以看出这个服务下的每个接口的事务处理平均时间、第95百分位,每分钟处理事务数、访问频率、每分钟的访问量。有用指标:第95个百分位(是统计学的一个术语,可以理解为有5%的请求超过多少时间),通过这个值我们可以直接看出这个接口的性能,比如:95百分位数是1,560ms的,那么意味着有5%的请求接口事务处理时间超过这个值,这个指标的意义是:反映服务(上面的波浪线图就是整个服务的95th)或接口的稳定性,如果在不同的时间段内95百分位数的值波动不大说明接口没有问题,如果不同时间段内波动越明显,就越能够放大问题,主要用于性能分析,而接口平均处理时间就可以直接反映该接口的性能,我们可以按上面的响应时间做为标准来优化
图二,是反映异常信息,主要有异常简单信息、在选定的时间段内发生的异常次数(如上面的5K,就是5千次)、最后一次发生的时间,异常的指标都是有用的了。
图三,这个监控界面所展示的指标个人认为是最为主要的了,直接能反馈这个服务的使用性问题,服务所在机器的资源问题、服务本身的资源问题。由于上面的一些指标已经说明过,这时就只解释CPU使用和内存使用,以及它的意义。
cpu使用图分别有这些指标:服务所在的主机cpu的最大使用率、平均使用率、服务本身占主机的最大使用率、平均使用率,这些指标都是有用指标,比如我选在一天内,这个机器的cpu使用波动很大,那么这个机器就有问题,同理服务本身的cpu使用也是一样;内存使用图指标:服务所在机器内存使用最大值,和平均值。这里我们还可以自己加入服务进程本身的jvm内存最大值、使用率指标,还有GC图展示:GC次数、用时、GC类型。 - 链路界面
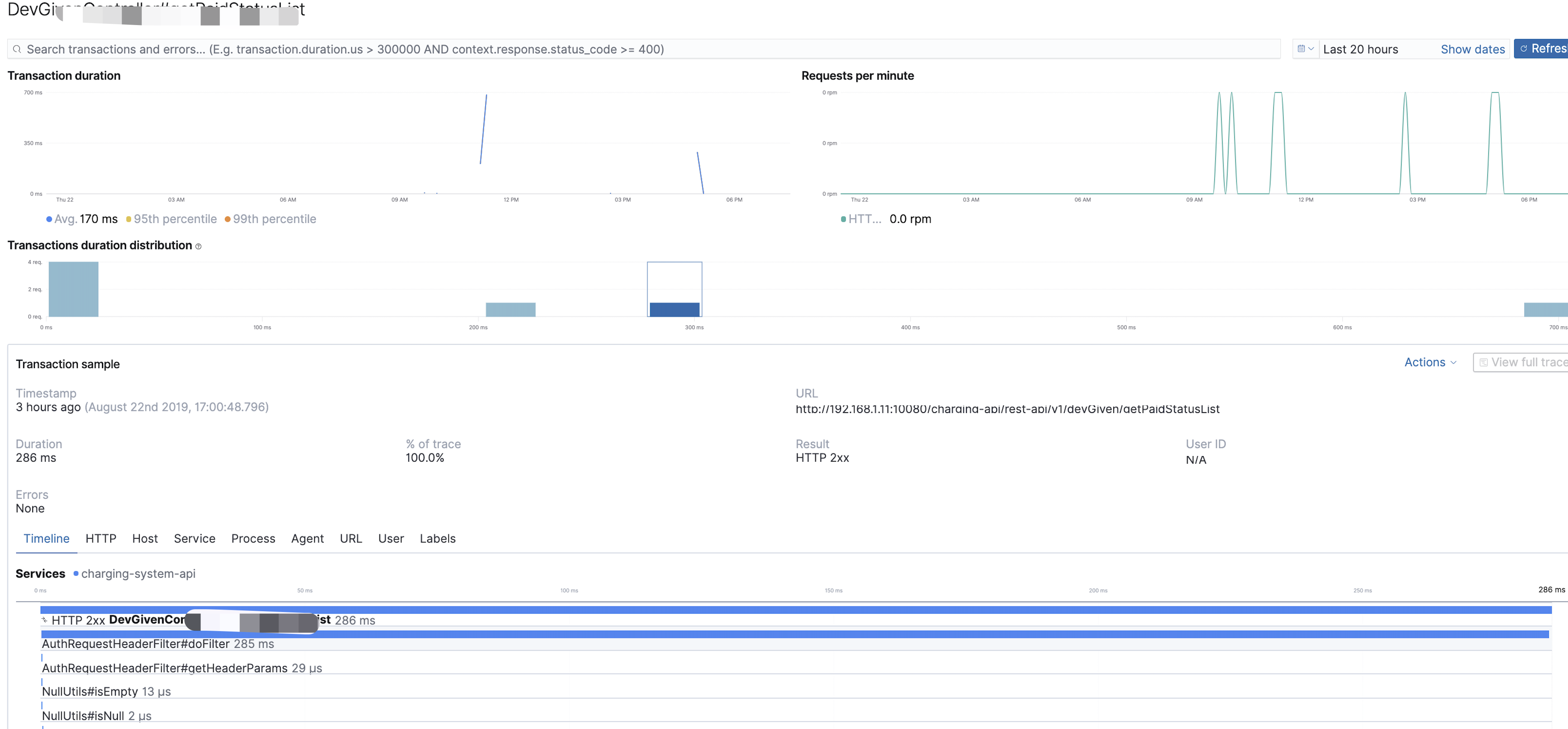
说明:这个界面主要是反映我们监控的接口内部服务调用链(包含跨度), 接口处理总时间、和每个调用的耗时,主要作用:为开发人员调性能接口提供帮助。
4、高级应用
制作我们的仪表板:
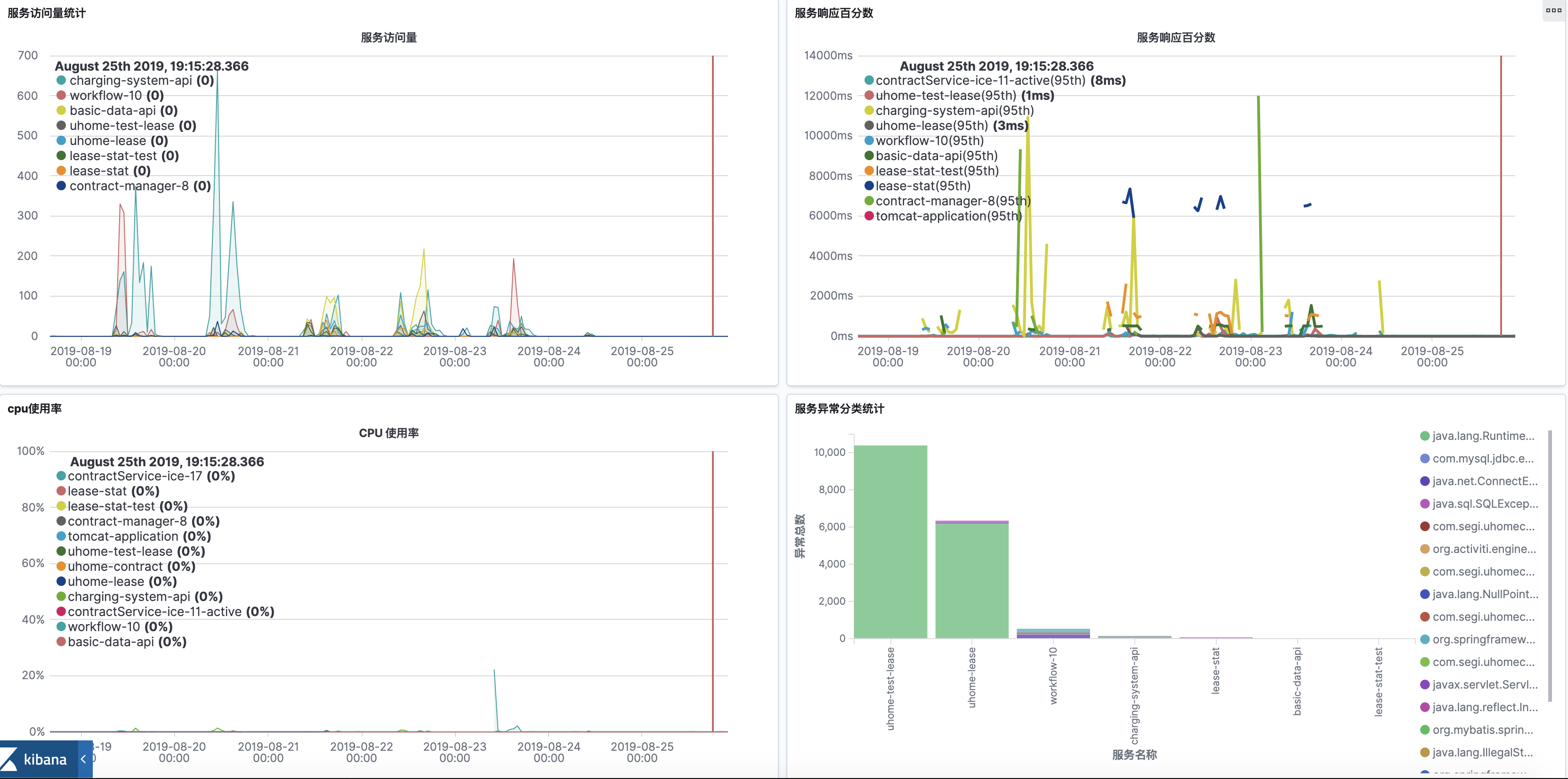
通知告警:
【版权声明】
本文版权归作者(深圳伊人网网络有限公司)和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文链接,否则保留追究法律责任的权利。如您有任何商业合作或者授权方面的协商,请给我留言:siqing0822@163.com