相信各位小伙伴在日常的工作中,经常会遇到需要将数据定时推送到别的服务器,甚至是要实时同步的情况。
下面笔者将会介绍几种可行的方式。
一.scp+ssh-key+crontab
这种是最原始的办法,但也是最基本,最不受限制的,基本只要能ssh到对端,这种方法就是可行的。笔者曾经在项目中遇到过两端的服务器之间存在多重网络限制。折腾来折腾去,最后还是选用这种方法。
首先,如果要做到脚本推送,这中方法最大的问题就是在scp的过程中需要输入密码,这样就做不到自动化执行脚本了。技术厉害的同学用expect来实现用户交互,如果是还在打基础阶段的同学,可以选用ssh密钥的方式去规避这个问题。
假设:
有两台server,server1和server2
我们需要定期从server1推从数据到server2。
server1:
ssh-keygen (一路回车到最后)
cd ~/.ssh/ (这个是存放ssh私密文件的路径)
文件夹会出现下图的两个文件

其中id_rsa是私钥,是要放在本地的。
而id_rsa.pub是公钥,里面有跟私钥相互匹配的信息。
vim id_rsa.pub 把里面的信息复制出来

server2:
cd ~/,ssh/ (如果没有,自行创建)
vim authorized_keys 这个是认证文件
将刚才的公钥粘贴进去,保存。
这个时候回到server1,ssh到server2就不用使用密码啦。
接下来就是自由发挥的时间了,可以针对想要传输、备份的数据,进行匹配、打包,最后scp到对端相应的目录。
例如:

#!/bin/bash
find /home/gzdssapp-service/peizhi/decision/jcrd -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/jcrd ; find /home/gzdssapp-service/peizhi/decision/mrtqbg -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/mrtqbg ; find /home/gzdssapp-service/peizhi/decision/qhyc -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/qhyc/ ; find /home/gzdssapp-service/peizhi/decision/qtyb -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/qtyb ; find /home/gzdssapp-service/peizhi/decision/ssxx -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/ssxx ; find /home/gzdssapp-service/peizhi/decision/tqybqs -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/tqybqs ; find /home/gzdssapp-service/peizhi/decision/ywzy -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/ywzy ; find /home/gzdssapp-service/peizhi/decision/zdqxkb -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zdqxkb ; find /home/gzdssapp-service/peizhi/decision/zdqxzb -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zdqxzb ; find /home/gzdssapp-service/peizhi/decision/zdtqgc -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zdtqgc ; find /home/gzdssapp-service/peizhi/decision/zjtx -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zjtx ; find /home/gzdssapp-service/peizhi/decision/zx -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zx ; find /home/gzdssapp-service/peizhi/decision/zxxx -type f -mmin -10 -exec scp {} 10.12.13.30:/home/gzdssapp/peizhi/decision/zxxx ;
上面的脚本是在指定的目录下搜索最新十分钟内更新的文件,并推送到对端。
最后把这个脚本加进定时任务
crontab -uroot -e
*/5 * * * * /bin/bash /scripts/decision.sh > /dev/null 2&>1
这样就实现了实时推送了。
二.ftp
这种方法就建立在对端有ftp的情况下可以实现,笔者在项目中经常用到这种方法来对数据做出实时备份。
#!/bin/bash date=`date "+%Y%m%d"` full_date=`date "+%Y-%m-%d %H:%m:%S"` tar -cvzf /scripts/test.$date.tar.gz /scripts/test/ cd /scripts/ ftp -in << EOF open 172.16.1.199 user backup1 tqw961110 put test.$date.tar.gz bye EOF rm -f /scripts/test.$date.tar.gz echo "$full_date test.$date.tar.gz has been put!!!" >> /scripts/backup.logs
上述的脚本主要是针对需要备份的目录进行打包,并且通过ftp的方式将数据推送到对端。这里的精髓是
ftp -in << EOF open 172.16.1.199 user backup1 tqw961110 put test.$date.tar.gz bye EOF
这里的ftp -i -n 经常在脚本中会用到,其意思是不要自动登陆并取消用户交互模式,这样就不会出现系统向你询问用户名和密码的情况了。
后续就是ftp里面的一些操作了,手动操作是怎样的,脚本里面就是怎样写的,最后通过bye来登出ftp即可。
同样,这个脚本添加进定时任务里面,就可以实现定时备份拉。
--------------------------------------------------华丽的分割线------------------------------------------------------
上述两种方法都是定时推送数据,其两端的数据会存在一定的延时。
接下来为大家介绍另外两种方法,可以做到数据的实时同步。
一.inotify+rsync
inotify这款软件主要是实时监测系统中的某个目录,当目录下某个文件发生增删改的操作的时候,就会把文件的全路径打印出来,后续配合我们的脚本中的while read file
就可以对这些被打印出来的文件做出下一步的处理了。而rsync则是一个数据传输工具,其有三种工作方式,在这里笔者就不一一介绍了,感兴趣的同学可以自动搜索,接下来将会
着重介绍他的daemon模式。
同样假设有两台server,server1需要把数据实时同步到server2
server1:
配置rsync
vim /etc/rsyncd.conf
##rsync.conf start
uid = rsync 进程用户
gid = rsync 进程用户组
use chroot = no 安全相关
max connections = 200 最大连接数
timeout = 300 超时时间
pid file = /var/run/rsyncd.pid 进程对应的进程号文件
lock file = /var/run/rsync.lock 锁文件
log file = /var/log/rsyncd.log 日志文件
[backup] 模块名称
path = /backup/ 服务器端提供访问的目录
ignore errors 忽略错误
read only = false 可写
list = false 不能列表
#hosts allow = 172.16.1.0/24 #这里默认的是全部都allow
#hosts deny = 0.0.0.0/32
auth users = rsync_backup
secrets file = /etc/rsyncd.password
##rsync.conf end
创建密码文件
vim /etc/rsyncd.password
rsync_backup:tqw961110
修改密码文件的权限(这里是一定要修改的,不然会报错。)
chmod 600 /etc/rsyncd.password
创建用户
useradd rsync -s /sbin/nologin -M (不能登陆,没有家目录)
创建推送文件夹
mkdir /backup/
更改属主
chown -R rsync:rsync /backup/
启动服务
rsync --daemon
开放端口
firewall-cmd --add-port=873/tcp --permanent
firewall-cmd --reload
server1
配置密码文件
vim /etc/rsyncd.password
tqw961110
chmod 600 /etc/rsyncd.password
尝试将文件推送到server2
rsync ./1 rsync_backup@172.16.1.199::backup/ --password-file=/etc/rsyncd.password
成功则证明rsync搭建成功
配置inotify
server1:
yum -y install inotify-tools
编写监控脚本
#!/bin/bash
Path=/scripts/test/
IP=172.16.1.199
inotifywait -mrq --format '%w%f' -e create,close_write,delete $Path | while read file
do
cd $Path
rsync $file rsync_backup@172.16.1.199::backup/ --password-file=/etc/rsyncd.password
done
上述脚本监控/scripts/test/这个目录,当目录下有文件创建或者内容更新,则执行下面的rsync命令。
将脚本放到后台运行
nohup /scripts/test.sh &
测试
cd /scripts/test/
touch test1 看看文件有没有同步到server2上
echo “test123” > test1 看看内容有没有同步到server2上
有,则证明同步成功。
二.sersync
在上面的方法中,可以做到文件实时同步到对端,但是这个是单层目录的同步,也就是说,当目录下有子目录下面的文件更新,上述方法是监控不到的。而且上面的方法也不知道删除文件。因此,接下来为大家介绍笔者经常使用的方法。
rsync的配置步骤跟上面方法一样。不一样的是,我们不需要用到inotify,而是用到sersync这个工具。
配置sersync
这款软件直接解压就可以使用了,无需编译安装。
将软件包解压到对应的目录后,进入目录,会看到两个文件。

编辑配置文件
vim confxml.xml
<sersync>
<localpath watch="/scripts/test/"> #指定监控本地的哪个目录
<remote ip="172.16.1.199" name="backup"/> #指定对端ip和rsync模块名
<!--<remote ip="192.168.8.39" name="tongbu"/>-->
<!--<remote ip="192.168.8.40" name="tongbu"/>-->
</localpath>
<rsync>
<commonParams params="-avz"/> #配置rsync命令参数选项
<auth start="true" users="rsync_backup" passwordfile="/etc/rsyncd.password"/> #配置rsync模块用户名和密码文件
<userDefinedPort start="false" port="874"/><!-- port=874 --> #这里可以修改rsync的传输端口,当对端rsync不是启动在873端口上,这里就需要配置。
<timeout start="false" time="100"/><!-- timeout=100 -->
<ssh start="false"/>
</rsync>
<failLog path="/scripts/sersync.log" timeToExecute="60"/><!--default every 60mins execute once--> #指定错误日志的路径
<crontab start="false" schedule="600"><!--600mins-->
<crontabfilter start="false">
<exclude expression="*.php"></exclude>
<exclude expression="info/*"></exclude>
</crontabfilter>
</crontab>
<plugin start="false" name="command"/>
</sersync>
执行命令
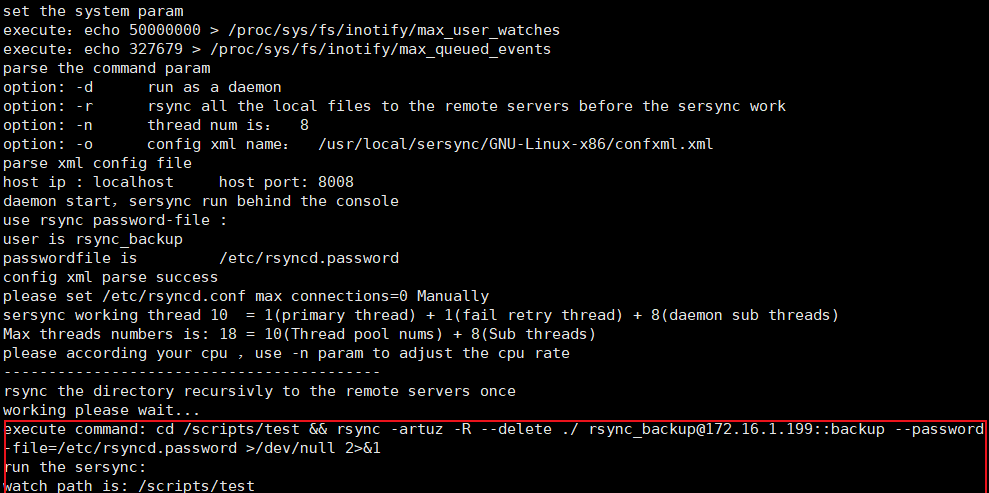
/usr/local/sersync/GNU-Linux-x86/sersync2 -d -r -n 8 -o /usr/local/sersync/GNU-Linux-x86/confxml.xml
一般来说,出现下面信息,则证明运行成功。可以到监控的目录进程文件增删改的操作,看看server2对应的目录是否有同步到。
sersync的参数详解
参数-d:启用守护进程模式
参数-r:在监控前,将监控目录与远程主机用rsync命令推送一遍
c参数-n: 指定开启守护线程的数量,默认为10个
参数-o:指定配置文件,默认使用confxml.xml文件
参数-m:单独启用其他模块,使用 -m refreshCDN 开启刷新CDN模块
参数-m:单独启用其他模块,使用 -m socket 开启socket模块
参数-m:单独启用其他模块,使用 -m http 开启http模块
不加-m参数,则默认执行同步程序