手写数字digits分类,这可是深度学习算法的入门练习。而且还有专门的手写数字MINIST库。opencv提供了一张手写数字图片给我们,先来看看

这是一张密密麻麻的手写数字图:图片大小为1000*2000,有0-9的10个数字,每5行为一个数字,总共50行,共有5000个手写数字。在opencv3.0版本中,图片存放位置为
/opencv/sources/samples/data/digits.png
我们首先要做的,就是把这5000个手写数字,一个个截取出来,每个数字块大小为20*20。直接将每个小图块进行序列化,因此最终得到一个5000*400的特征矩阵。样本数为5000,维度为400维。取其中前3000个样本进行训练。
注意:截取的时候,是按列截取。不然取前3000个样本进行训练就会出现后几个数字训练不到。
具体代码:
#include "stdafx.h" #include "opencv2opencv.hpp" #include <iostream> using namespace std; using namespace cv; using namespace cv::ml; int main() { Mat img = imread("E:/opencv/opencv/sources/samples/data/digits.png"); Mat gray; cvtColor(img, gray, CV_BGR2GRAY); int b = 20; int m = gray.rows / b; //原图为1000*2000 int n = gray.cols / b; //裁剪为5000个20*20的小图块 Mat data,labels; //特征矩阵 for (int i = 0; i < n; i++) { int offsetCol = i*b; //列上的偏移量 for (int j = 0; j < m; j++) { int offsetRow = j*b; //行上的偏移量 //截取20*20的小块 Mat tmp; gray(Range(offsetRow, offsetRow + b), Range(offsetCol, offsetCol + b)).copyTo(tmp); data.push_back(tmp.reshape(0,1)); //序列化后放入特征矩阵 labels.push_back((int)j / 5); //对应的标注 } } data.convertTo(data, CV_32F); //uchar型转换为cv_32f int samplesNum = data.rows; int trainNum = 3000; Mat trainData, trainLabels; trainData = data(Range(0, trainNum), Range::all()); //前3000个样本为训练数据 trainLabels = labels(Range(0, trainNum), Range::all()); //使用KNN算法 int K = 5; Ptr<TrainData> tData = TrainData::create(trainData, ROW_SAMPLE, trainLabels); Ptr<KNearest> model = KNearest::create(); model->setDefaultK(K); model->setIsClassifier(true); model->train(tData); //预测分类 double train_hr = 0, test_hr = 0; Mat response; // compute prediction error on train and test data for (int i = 0; i < samplesNum; i++) { Mat sample = data.row(i); float r = model->predict(sample); //对所有行进行预测 //预测结果与原结果相比,相等为1,不等为0 r = std::abs(r - labels.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f; if (i < trainNum) train_hr += r; //累积正确数 else test_hr += r; } test_hr /= samplesNum - trainNum; train_hr = trainNum > 0 ? train_hr / trainNum : 1.; printf("accuracy: train = %.1f%%, test = %.1f%% ", train_hr*100., test_hr*100.); waitKey(0); return 0; }
根据经验,利用最近邻算法对手写数字进行分类,会有很高的精度,因此在本文中我们采用的是knn算法。
最终结果:
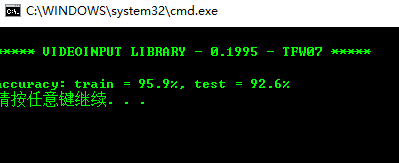
训练精度为95.9%, 测试精度为92.6%。如果对手写数字识别准确率达不到90%以上,就没有什么实际作用了。如果调整训练样本数,这个精度应该会有所改变。