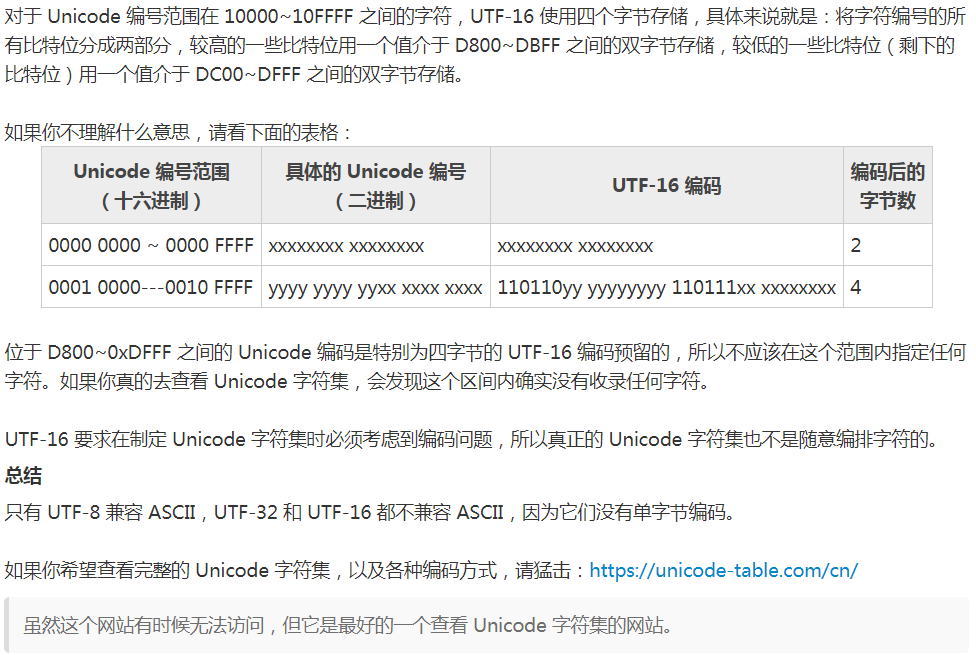
首先需要知道 Unicode 编码范围 [U+00, U+10FFFF], 其中 [U+00, U+FFFF] 称为基础平面(BMP), 这其中的字符最为常用.
当然, 这 65536 个字符是远远不够的.
0x010000 - 0x10FFFF 为辅助平面, 共可存放16 * 65536个字符,划分为16个不同的平面
http://www.oschina.net/code/snippet_179574_15065
按照如下的编码方式,对UTF8和UTF16之间进行转换
从UCS-2到UTF-8的编码方式如下(没有处理扩展面):
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
typedef unsigned long UTF32; /* at least 32 bits */
typedef unsigned short UTF16; /* at least 16 bits */
typedef unsigned char UTF8; /* typically 8 bits */
typedef unsigned int INT;
/*
UCS-2编码 UTF-8 字节流(二进制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*/
#define UTF8_ONE_START (0xOOO1)
#define UTF8_ONE_END (0x007F)
#define UTF8_TWO_START (0x0080)
#define UTF8_TWO_END (0x07FF)
#define UTF8_THREE_START (0x0800)
#define UTF8_THREE_END (0xFFFF)
void UTF16ToUTF8(UTF16* pUTF16Start, UTF16* pUTF16End, UTF8* pUTF8Start, UTF8* pUTF8End)
{
UTF16* pTempUTF16 = pUTF16Start;
UTF8* pTempUTF8 = pUTF8Start;
while (pTempUTF16 < pUTF16End)
{
if (*pTempUTF16 <= UTF8_ONE_END
&& pTempUTF8 + 1 < pUTF8End)
{
//0000 - 007F 0xxxxxxx
*pTempUTF8++ = (UTF8)*pTempUTF16;
}
else if(*pTempUTF16 >= UTF8_TWO_START && *pTempUTF16 <= UTF8_TWO_END
&& pTempUTF8 + 2 < pUTF8End)
{
//0080 - 07FF 110xxxxx 10xxxxxx
*pTempUTF8++ = (*pTempUTF16 >> 6) | 0xC0;
*pTempUTF8++ = (*pTempUTF16 & 0x3F) | 0x80;
}
else if(*pTempUTF16 >= UTF8_THREE_START && *pTempUTF16 <= UTF8_THREE_END
&& pTempUTF8 + 3 < pUTF8End)
{
//0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*pTempUTF8++ = (*pTempUTF16 >> 12) | 0xE0;
*pTempUTF8++ = ((*pTempUTF16 >> 6) & 0x3F) | 0x80;
*pTempUTF8++ = (*pTempUTF16 & 0x3F) | 0x80;
}
else
{
break;
}
pTempUTF16++;
}
*pTempUTF8 = 0;
}
void UTF8ToUTF16(UTF8* pUTF8Start, UTF8* pUTF8End, UTF16* pUTF16Start, UTF16* pUTF16End)
{
UTF16* pTempUTF16 = pUTF16Start;
UTF8* pTempUTF8 = pUTF8Start;
while (pTempUTF8 < pUTF8End && pTempUTF16+1 < pUTF16End)
{
if (*pTempUTF8 >= 0xE0 && *pTempUTF8 <= 0xEF)//是3个字节的格式
{
//0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*pTempUTF16 |= ((*pTempUTF8++ & 0xEF) << 12);
*pTempUTF16 |= ((*pTempUTF8++ & 0x3F) << 6);
*pTempUTF16 |= (*pTempUTF8++ & 0x3F);
}
else if (*pTempUTF8 >= 0xC0 && *pTempUTF8 <= 0xDF)//是2个字节的格式
{
//0080 - 07FF 110xxxxx 10xxxxxx
*pTempUTF16 |= ((*pTempUTF8++ & 0x1F) << 6);
*pTempUTF16 |= (*pTempUTF8++ & 0x3F);
}
else if(*pTempUTF8 >= 0 && *pTempUTF8 <= 0x7F)//是1个字节的格式
{
//0000 - 007F 0xxxxxxx
*pTempUTF16 = *pTempUTF8++;
}
else
{
break;
}
pTempUTF16++;
}
*pTempUTF16 = 0;
}
int main()
{
UTF16 utf16[256] = {L"你a好b吗234中国~!"};
UTF8 utf8[256];
UTF16ToUTF8(utf16, utf16+wcslen(utf16), utf8, utf8+256);
memset(utf16, 0, sizeof(utf16));
UTF8ToUTF16(utf8, utf8 + strlen(utf8), utf16, utf16+256);
return 0;
}
UTF-16 并不比 UTF-8 更受待见, 只是 Windows 默认使用 UTF-16 而已, 所以不得不在它们之间做转换(如果你还在使用非 Unicode 编码, 那你已经是受到微软的毒害了)
当然, 万恶的微软还是给出了更简单的方法的, 那就是下面的两个函数:
WideCharToMultiByte
将UTF-16(宽字符)字符串映射到新的字符串。新的字符串不一定来自多字节字符集。(那你取这个名字是闹哪样? 多字节字符集是什么鬼??? 你怎么不去屎)
https://msdn.microsoft.com/en-us/library/windows/desktop/dd374130(v=vs.85).aspx
MultiByteToWideChar
将字符串映射到UTF-16(宽字符)字符串。字符串不一定来自多字节字符集。
https://msdn.microsoft.com/en-us/library/windows/desktop/dd319072(v=vs.85).aspx
程序: 将 UTF-16 编码的字符串转换为 UTF-8 编码, 并在控制台输出
#include <Windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void use(const char *utf8str) {
system("Pause");
system("chcp 65001");
if (utf8str == NULL) {
printf("NULL
");
return;
}
printf("%s
", utf8str);
}
char *utf16to8(const wchar_t *str) {
if (str == NULL) {
return NULL;
}
int cBuf = 0; // 缓冲区大小
// 计算缓冲区需要的大小, 如果函数成功, 则返回值至少是 1 (UTF-8以0x00结尾)
if (cBuf = WideCharToMultiByte(
CP_UTF8,
0,
str,
-1,
NULL,
0,
NULL,
NULL), !cBuf ){
// 计算失败
fprintf(stderr, "计算内存失败!");
return NULL;
}
printf("缓冲区大小 %d .
", cBuf);
char *buf = NULL; // 指向缓冲区
buf = (char *)malloc(cBuf); // 分配缓冲区
if (!WideCharToMultiByte(
CP_UTF8,
0,
str,
-1,
buf,
1024,
NULL,
NULL) ){
fprintf(stderr, "转换失败!
");
return NULL;
}
// 返回缓冲区地址
return buf;
}
void run() {
const wchar_t *str = L"Hello你好我的朋友!";
char *utf8str = utf16to8(str);
use(utf8str);
free(utf8str);
}
int main(int argc, char* argv[]) {
run();
system("Pause");
return EXIT_SUCCESS;
}
Output如下------>
缓冲区大小 25 .
请按任意键继续. . .
Active code page: 65001
Hello你好我的朋友!
Press any key to continue . . .
上面这个函数调用了两次 WideCharToMultiByte(), 第一次是计算转换所需的空间, 第二次开始转换(It's stupid!)
那么依葫芦画瓢, 你现在可以将 UTF-8 -> UTF16了吗?
补两张图

最终版本:
wchar_t *
utf8to16(const char *str) {
if (str == NULL) return L"(null)";
// 计算缓冲区需要的大小, 如果函数成功, 则返回 UTF-8 字符数量, 所以无法确定具体字节数
int cBuf = MultiByteToWideChar(CP_UTF8, 0, str, -1, NULL, 0);
if (cBuf == 0) return L"(null)";
wchar_t *buf = malloc(cBuf * 4);
if (cBuf != MultiByteToWideChar(CP_UTF8, 0, str, -1, buf, cBuf)) return L"(null)";
return buf;
}
char *
utf16to8(const wchar_t *str) {
if (str == NULL) return "(null)";
// 计算缓冲区需要的大小, 如果函数成功, 则返回具体字节数, 所以 cBuf 至少是 1 (UTF-8以0x00结尾)
int cBuf = WideCharToMultiByte(CP_UTF8, 0, str, -1, NULL, 0, NULL, NULL);
if (cBuf < 1) return "(null)";
char *buf = malloc(cBuf); // 分配缓冲区
if (cBuf != WideCharToMultiByte(CP_UTF8, 0, str, -1, buf, 1024, NULL, NULL)) return "(null)";
return buf;
}