高性能数据库集群的第一种方式是“读写分离”,其本质是将访问压力分散到集群中的多个节点,但是没有分散存储压力;
第二种方式是“分库分表”,既可以分散访问压力,又可以分散存储压力。
一、高性能数据库集群:读写分离
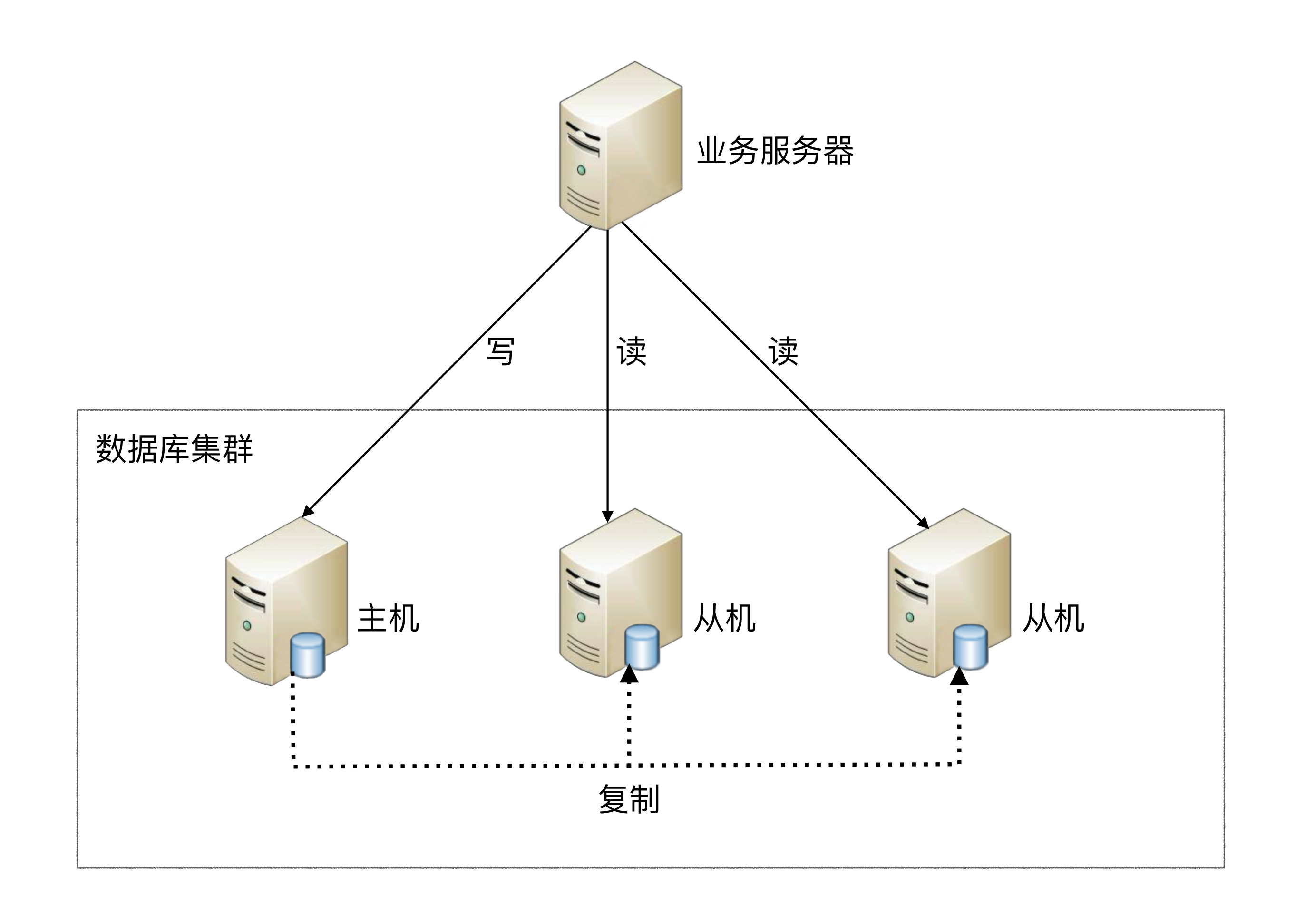
读写分离的基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
两个设计复杂度: 主从复制延迟和分配机制。
解决主从复制延迟有几种常见的方法:
1. 写操作后的读操作指定发给数据库主服务器
2. 读从机失败后再读一次主机
3. 关键业务读写操作全部指向主机,非关键业务采用读写分离
分配机制
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
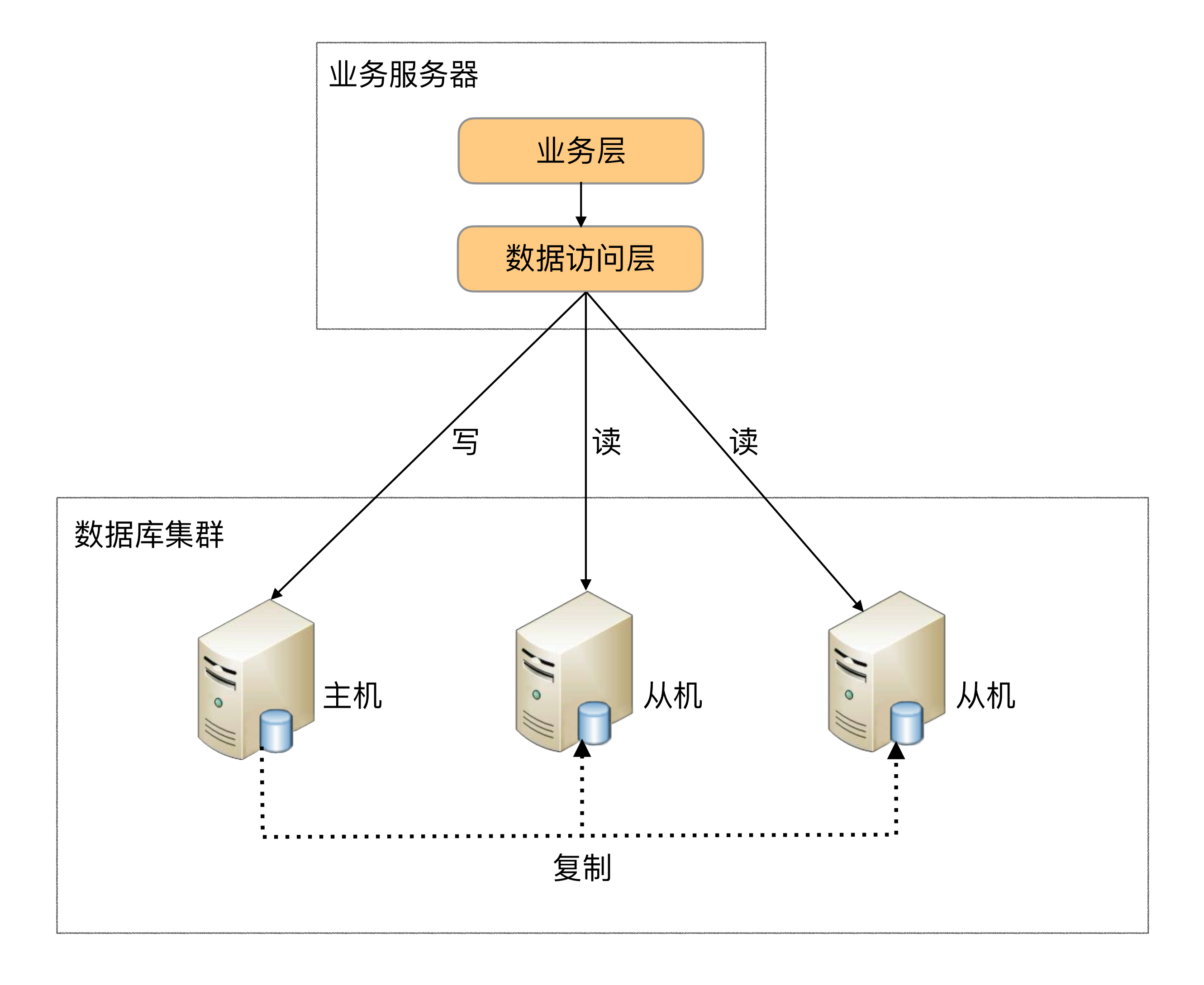
程序代码封装。示意图:
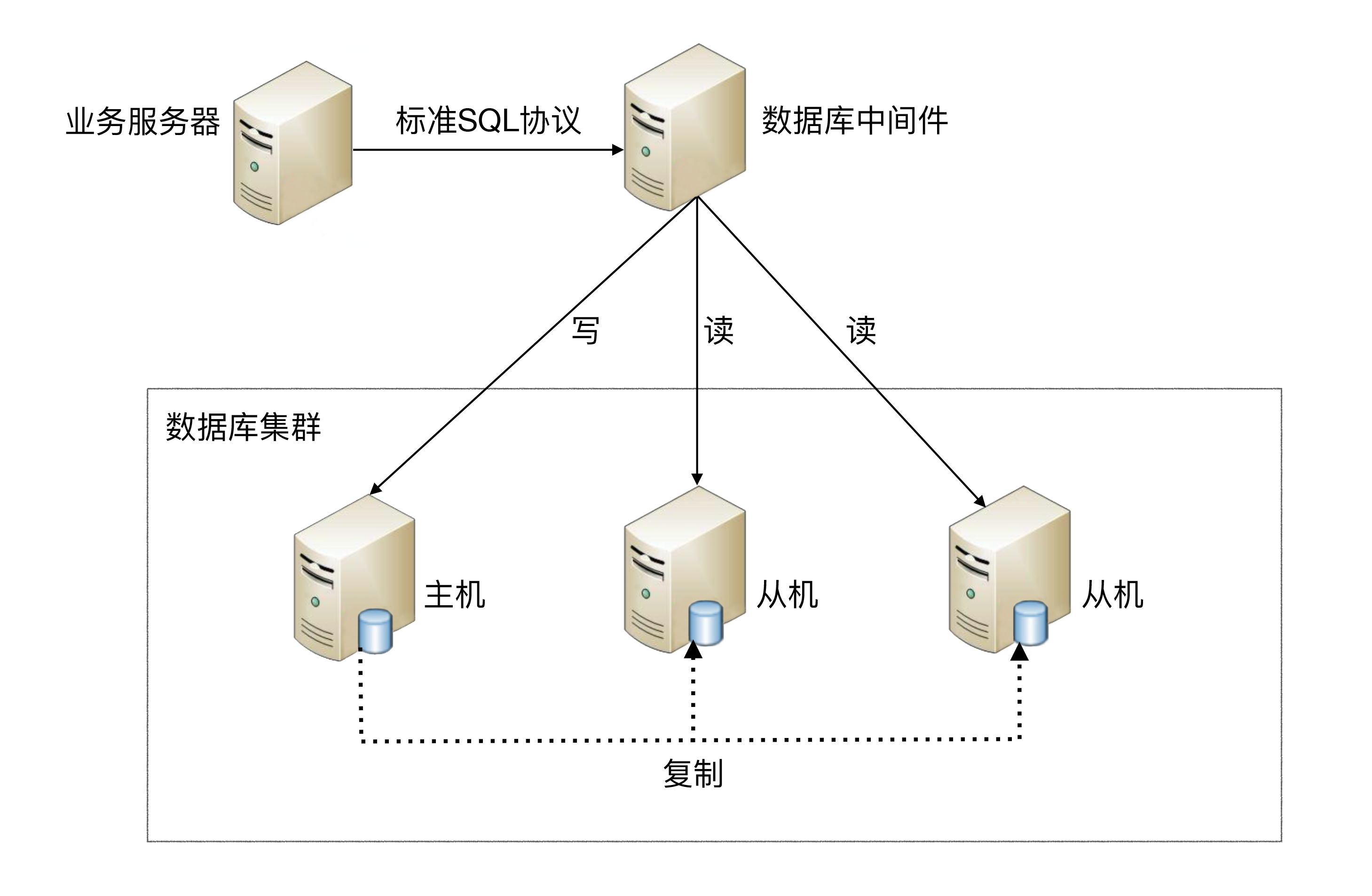
中间件封装:
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。其基本架构是:
二、高性能数据库集群:分库分表
分散存储的方法“分库分表”,其中包括“分库”和“分表”两大类。
1、分库:
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。 通过分库,将业务分别存储在不同的数据库中,从而降低数据库存储压力。
分库后,SQL的join和事务无法使用,不建议初创公司使用。
单台数据库服务器的性能:一般来说,单台数据库服务器能够支撑 10 万用户量量级的业务。
2、分表:
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。此时就需要对单表数据进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表。
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。水平分表适合表行数特别大的表。
水平分表相比垂直分表,会引入更多的复杂性,主要表现在下面几个方面:
水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算。
常见的路由算法有:
- 范围路由
- 一般建议分段大小在 100 万至 2000 万之间。
- 优点是可以随着数据的增加平滑地扩充新的表。缺点是分布不均匀。
- Hash 路由
- 选取某个列(或者某几个列组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中。
- Hash 路由的优缺点和范围路由基本相反,Hash 路由的优点是表分布比较均匀,缺点是扩充新的表很麻烦,所有数据都要重分布。
- 配置路由
三、NoSQL
NoSQL 是 SQL 的一个有力补充,NoSQL != No SQL,而是 NoSQL = Not Only SQL。
NoSQL 方案带来的优势,本质上是牺牲 ACID 中的某个或者某几个特性。
常见的 NoSQL 方案分为 4 类。
K-V 存储:解决关系数据库无法存储数据结构的问题,以 Redis 为代表。
文档数据库:解决关系数据库强 schema 约束的问题,以 MongoDB 为代表。
列式数据库:解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表。
全文搜索引擎:解决关系数据库的全文搜索性能问题,以 Elasticsearch 为代表。
四、高性能缓存架构
- 需要经过复杂运算后得出的数据,存储系统无能为力
- 读多写少的数据,存储系统有心无力
缓存就是为了弥补存储系统在这些复杂业务场景下的不足,其基本原理是
将可能重复使用的数据放到内存中,一次生成、多次使用,避免每次使用都去访问存储系统。
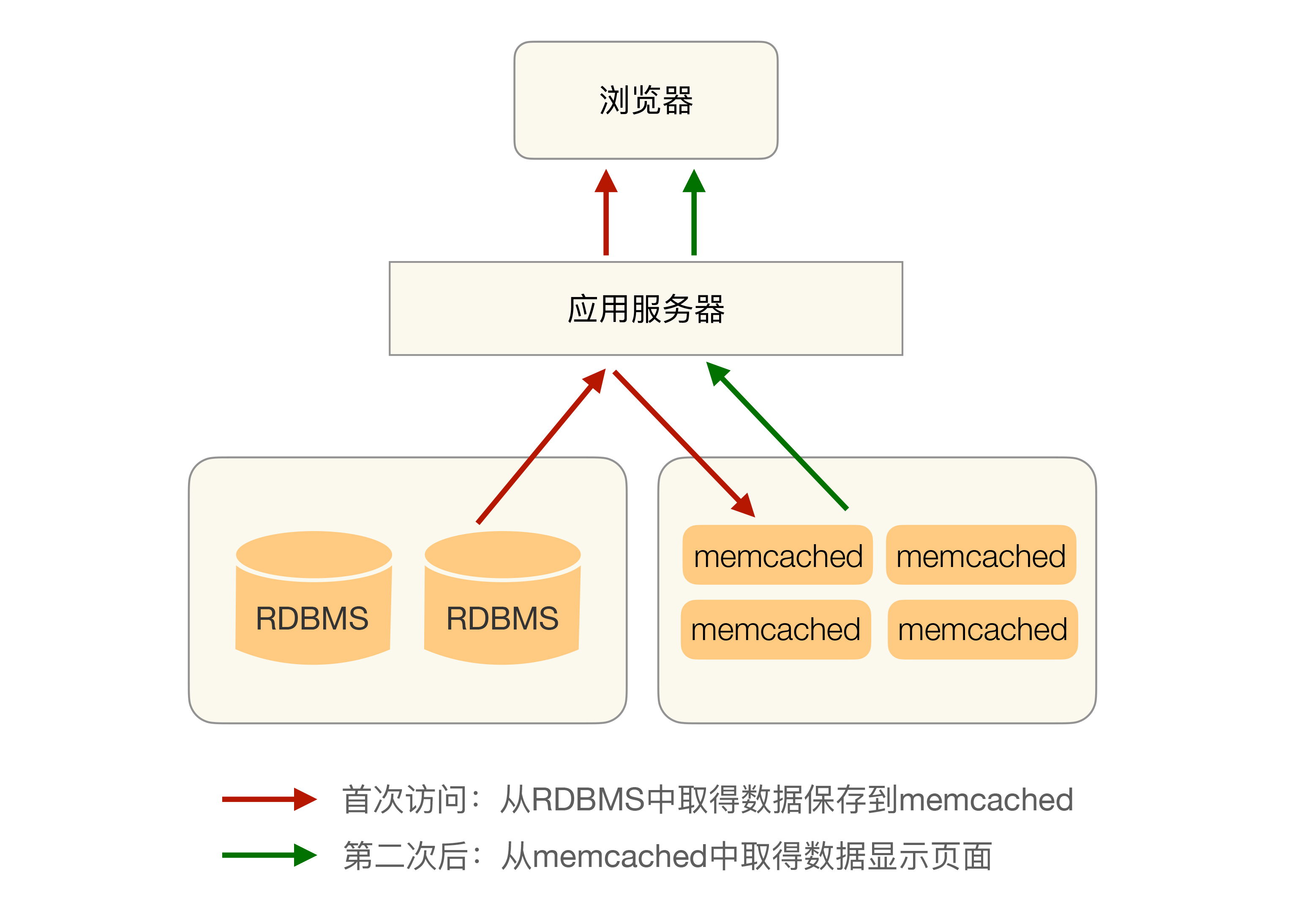
缓存能够带来性能的大幅提升,以 Memcache 为例,单台 Memcache 服务器简单的 key-value 查询能够达到 TPS 50000 以上,其基本的架构是:
缓存穿透是指缓存没有发挥作用,业务系统虽然去缓存查询数据,但缓存中没有数据,业务系统需要再次去存储系统查询数据。
缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。
缓存热点的解决方案就是复制多份缓存副本,将请求分散到多个缓存服务器上,减轻缓存热点导致的单台缓存服务器压力。