前言:前面介绍了Java、JVM相关方面的题目,该篇介绍数据库方面相关的题目,这里数据库为MySql,因为笔者或朋友在面试过程中都是涉及MySql的相关知识点。
数据库篇
在数据库题目中,由于现在大部分公司都是使用MySql作为数据库,因此笔者及其朋友所遇到的问题也都是MySql相关的知识点。
1)MySql中索引的基本定义,优劣势,以及索引优化。
索引是帮助Mysql高效获取数据的数据结构,因此,索引的本质就是数据结构,索引的目的在于提高查询效率,可类比字典。
索引:排好序的快速查找的数据结构。
用途:排序 + 快速查找。注意,是两种功能。
数据库除了存储数据本身之外,还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
MySql索引通常是指B+树索引。
索引优势:
类似书籍的目录,提高数据检索的效率,降低数据库的 IO 成本(因为数据最终是存储在磁盘上的)。
通过索引列对数据进行排序,降低数据排序的成本,降低了 CPU 的消耗(因为排好序,查询速度增加)。
索引劣势:
索引也是一张表,保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用磁盘空间的。
虽然提高了查询速度,但是会降低更新速度(因为数据更新后,需要重新对索引排序),如 INSERT、UPDATE、DELETE 操作。
哪些情况适合建索引:
①主键自动建立唯一索引。
②频繁作为查询条件的字段应该创建索引。
③查询中与其它表关联的字段,外键关系建立索引。
④查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
⑤查询中统计或者分组字段。
哪些情况不适合建索引:
①频繁更新的字段。
②Where 条件中用不到的字段。
③表记录太少。
④经常增删改的表。
⑤散列太小的字段,如性别、国籍。
索引优化就是为了尽可能的利用索引来提高查询的效率,所以保证索引不失效,并且创建正确的索引与高效的sql语句,就是对索引的优化,因此关于优化直接看下个题目:索引的失效。
2)哪些情况下索引失效。
索引优化和索引失效是相对应的,我们优化索引的目的就是为了让索引不失效,发生下列情况索引会失效:
①对于使用NOT NULL修饰的字段,使用IS NULL和 IS NOT NULL,会导致索引失效,进行全表扫描。
②键值较少的列。因为键值较少,如果加上索引,还需要对索引进行维护,本来记录就少,所以直接查询效率更高。
③LIKE以%开头会导致索引失效。如果右边加上%,索引不会失效,但是在实际生产环境中,如果只在右边加%,对于模糊查询不够用。解决方式:使用索引覆盖:查询字段和条件字段都在索引列上时,索引才会生效。
④使用范围后(如字段>1)会使索引失效(存储引擎不能使用索引中范围条件右边的列)。所以如果存在范围查询的字段,就不要建立索引。
⑤对于两张表,如果基于主键的查询,是可以用索引的,因为主键本身就有索引,对于左右连接来说,左连接,左表肯定是All,本来就要查询出左表的结果,所以右表建立索引,而右连接相反,左表建立索引。
⑥不要在索引列上做任何操作(计算、函数和类型转换),会导致索引失效,另外在字符串查询不加单引号,也会导致索引失效。
⑦最左前缀法则:查询从索引列的最左开始(头部),如果没有头部,则会使用全表扫描,并且中间不能间断,如只有头部和尾部,则只使用头部索引。火车头不能少,中间车厢不能断。
⑧使用不等于的时候会使索引失效,导致全表扫描。
⑨尽量使用覆盖索引:索引列和查询列一致。
⑩OR连接会使索引失效,导致全表扫描。
⑪Order By 要尽量使用 Index 排序,避免 Filesort 排序。
3)MySql调优项目经历或者相关策略。
是否需要添加索引,在哪些字段上添加索引,在sql语句中,索引列是否用上,主要使用Explain对sql语句进行分析。
这里对Explain进行简单介绍:
使用 Explain 关键字可以模拟优化器执行 Sql 查询语句,从而知道 Mysql 是如何处理 Sql 的。
执行Explain会产生一个信息表,表中有如下关键字:

①id:select查询的序列号,表示查询中执行select子句或操作表的顺序。值越大越先执行,值相同,从上到下依次执行。
②select_type:有6种取值SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT,其值具体解释,参考:https://yq.aliyun.com/articles/61934
③table:显示当前行sql是对哪张表进行操作的。
④type:指访问类型,非常重要,根据type可推断sql语句的优劣。其取值从最好到最差依次是:system > const > eq_ref > ref > range > index > all,通常需保证到range级别,最好能达到ref级别。
#1.const:表示通过索引一次就找到了,用于比较主键索引或者唯一性索引。如将主键置于 Where 条件中,Mysql 就能将该查询转换为一个常量。
#2.system:表示只有一行数据,是const的特例,生产中基本不会出现,可忽略。
#3.eq_ref:唯一性索引扫描。对于每个索引表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
#4.ref:非唯一性索引扫描,返回匹配某个单独值的所有行。对于 eq_ref & ref 的总结:都会使用索引,但使用索引进行检索后的结果不同,前者的结果是唯一的,而后者的结果不唯一。所以,前者通常用于主键或唯一性索引扫描,而后者通常用于非唯一性索引扫描(有多行记录)。
#5.range:只检索给定范围的行,使用一个索引来选择行;Key 列显示使用了哪个索引;一般就是在 Where 条件中出现了 between, <, >, in 等查询;它比全索引扫描要好,因为它开始于索引的某一点、且结束于另一点,而不用全索引扫描.
#6.index:全索引扫描,只遍历索引树,index和all 都是全表扫描,但是 index 是从索引中读取,而 All 是从磁盘中读取。
#7.All:全表扫描,磁盘扫描。
⑤possible_keys:显示理论上有可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被实际使用。
⑥key:实际使用的索引。如果为 Null,则未使用索引。查询中若使用了覆盖索引,则该索引只出现在 Key 列表中(即不会出现在 possible_keys 列中)。
⑦key_len:表示索引中使用的字节数,可通过该值计算查询中使用的索引长度。在不损失精确性的情况下,长度越短越好。显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的。
⑧ref:显示索引的哪一列被使用了,如果索引被使用则是一个常数。表示哪些列或常量被用于查找索引列上的值。
⑨rows:根据表统计信息及索引选用情况,大致估算出查询到结果时所需要读取的行数(要跑多少行)。值越小越好(值越小说明查询越精准)。
⑩Extra
会出现的值包括:
#1.Using filesort:说明 Mysql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行排序;Mysql 中无法利用索引完成的排序操作称为“文件排序”。因此出现该值,表示sql语句比较“烂”了,则需要进行sql语句的优化。
#2.Using Temporary:使用了临时表保存中间结果,Mysql 在查询结果排序时使用临时表,常见于 ORDER BY 和 GROUP BY。出现该值,则表明sql非常“烂”了,急需优化。
#3.Using Where:表明索引被用来执行索引键值的查找。
#4.Using Index:表示相应的 SELECT 操作中使用了覆盖索引,避免访问了表的数据行,效率可以。
总结:
type、key、ref、Extra,这四个字段比较重要,sql语句的“烂”的程度,通过这几个字段体现。
type:取值从最好到最差依次是:system > const > eq_ref > ref > range > index > all,查询时至少保证在range,最好达到ref。
key:实际使用的索引,如果为NULL,则表示未使用索引。
ref:显示那一列索引被使用了。
Extra:最好是Using Index、Using Where,一定不能是Using Temporary、Using filesort。
5)MySql的事务隔离级别,不可重复读、脏读、幻读。
MySql的事务隔离级别有4个,隔离等级从低到高依次为Read uncommitted (读取未提交内容)、Read committed(读取提交内容) 、Repeatable read(可重复读) 、Serializable (串行),这四个级别可以逐个解决脏读 、不可重复读 、幻读这几类问题,其中Repeatable read是MySql事务的默认隔离级别。
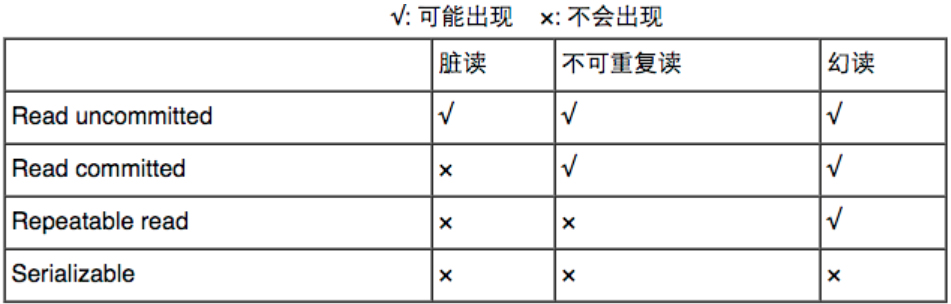
从表中可以看出Serializable隔离等级最高,可以避免一切并发问题,但是效率低。
脏读:A事务更新一份数据,但事务未提交,B事务在此时读取了同一份数据,由于某些原因,A事务发生了回滚操作,则B事务拿着失效的数据去做操作就会发生错误。脏读通俗来说就是读错了,读错了。
不可重复读:对于不可重复读的解释很多资料说得非常模糊,这里给出一个比较清晰的解释。A事务两次读取同一数据,在A事务还没有结束时,B事务也访问该同一数据,并进行了修改。那么在A事务中的两次读数据之间,由于B事务的修改,A事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即在重复对数据进行读取的时候,不能得到相同的数据内容,感觉这个不可重复读翻译很不好理解,个人的理解方式:不可重复读,那重复读会出现什么情况呢,重复读出现数据不一致的情况,所以还是不要重复读——>不可重复读)
例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改,则编辑第二次读取的文档与第一次就不一致了。
幻读:通俗来讲读取到的数据像产生幻觉一样。是指当事务不是独立执行时发生的一种现象。事务A在两次查询的过程中(比如查询结果8列),事务B对该表进行了插入、删除操作(增加或减少了2列),从而事务A第二次查询的结果发生了变化,两次查询的数据不一样,感觉产生了“幻觉”一样。
虚读:通俗来讲读取的数据不同。A事务在两次查询的过程中(查询结果一列),B事务对数据进行了修改,从而使A事务第二次查询的结果不一样。
脏读的事务未提交,虚读与幻读事务已经提交。
Read uncommitted(读未提交内容)
在该级别下,A事务对一行数据修改的过程中,不允许B事务对该行数据进行修改,但允许B事务对该行数据进行读操作。 因此本级别下,不会出现更新丢失(i++问题),但会出现脏读(A修改时,发生了回滚)、不可重复读(B两次读取时,A修改了数据),幻读(幻读是不可重复读的一种情况)。
Read committed(读提交内容)
在该级别下,未提交的写事务不允许其他事务访问该行,因此不会出现脏读;但是读取数据的事务允许其他事务的访问该行数据,因此会出现不可重复读的情况。A读取数据,B紧接着A更改了数据,并提交了事务,A再次读取数据时,发现数据已经改变。出现不可重复读和幻读想象。
Repeatable read(可重复读)
在该级别下,读事务时禁止写事务(读写互斥),A在读取数据时数据为100,事务提交后,紧接着B对数据修改为200,当A再次读取时,发现数据不一样,出现幻读。
Serialiazble read(串行)
隔离级别最高,避免一切并发问题,但效率低,生产中基本不用。
6)delete 与 truncate 区别,分别适用于哪种场景。
delete与truncate都是做删除操作,但是两者间还是有一定区别:
①truncate删除速度快,没有日志记录,数据不可恢复。释放表或索引的空间
②delete删除速度慢,因为删除中会产生日志记录,数据可恢复。不会释放表或索引的空间。
③应用场景这个不好说,delete可恢复,truncate不可恢复,只有根据具体需求进行选择了。
7)MySql中主从复制,集群。
MySql提供主从复制的功能,基础是二进制日志文件。
关于集群方面,功力不深,需要更进一步的了解,才能很好的回答该问题。
参考:
https://www.cnblogs.com/gl-developer/p/6170423.html
8)B+树、为什么使用 B+树、B+树优缺点
关于B+树,笔者并不是特别的了解。放上一链接:https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/03.02.md
为什么使用B+树?
①B+树支持区间查询,而B树不支持。
②B+树方便扫库,它直接从叶子节点出发,就可以进行扫描,而B树需进行中序遍历(LDR)。
③B+树磁盘读写代价更低。
缺点:
①当查找数据在非叶子节点时,B+树会走一条根到叶子节点的路径。
参考:
https://www.cnblogs.com/tiancai/p/9024351.html
http://darrenzhu.iteye.com/blog/2050082
9)MySql存储引擎MyISAM和InnoDB的区别。
①MyISAM不支持外键,InnoDB支持外键。
②MyISAM不支持事务,InnoDB支持事务。
③MyISAM是表锁,InnoDB是行锁。
④MyISAM支持全文索引,InnoDB不支持。
⑤MyISAM的查询速度比InnoDB快。
参考:
https://www.cnblogs.com/changna1314/p/6878900.html
by Shawn Chen,于2018.6月,开始找工作途中......