前文:
https://www.cnblogs.com/devilmaycry812839668/p/14975860.html
前文中我们使用自己编写的损失函数和单步梯度求导来实现算法,这里是作为扩展,我们这里使用系统提供的损失函数和优化器,代码如下:
import mindspore import numpy as np #引入numpy科学计算库 import matplotlib.pyplot as plt #引入绘图库 np.random.seed(123) #随机数生成种子 import mindspore.nn as nn import mindspore.ops as ops from mindspore import Tensor from mindspore import ParameterTuple, Parameter from mindspore import dtype as mstype from mindspore import Model import mindspore.dataset as ds from mindspore.train.callback import ModelCheckpoint, CheckpointConfig from mindspore.train.callback import LossMonitor # 数据集 class DatasetGenerator: def __init__(self): self.input_data = 2*np.random.rand(500, 1).astype(np.float32) self.output_data = 5+3*self.input_data+np.random.randn(500, 1).astype(np.float32) def __getitem__(self, index): return self.input_data[index], self.output_data[index] def __len__(self): return len(self.input_data) def create_dataset(batch_size=500): dataset_generator = DatasetGenerator() dataset = ds.GeneratorDataset(dataset_generator, ["input", "output"], shuffle=False) #buffer_size = 10000 #dataset = dataset.shuffle(buffer_size=buffer_size) dataset = dataset.batch(batch_size, drop_remainder=True) #dataset = dataset.repeat(1) return dataset class Net(nn.Cell): def __init__(self, input_dims, output_dims): super(Net, self).__init__() self.matmul = ops.MatMul() self.weight_1 = Parameter(Tensor(np.random.randn(input_dims, 128), dtype=mstype.float32), name='weight_1') self.bias_1 = Parameter(Tensor(np.zeros(128), dtype=mstype.float32), name='bias_1') self.weight_2 = Parameter(Tensor(np.random.randn(128, 64), dtype=mstype.float32), name='weight_2') self.bias_2 = Parameter(Tensor(np.zeros(64), dtype=mstype.float32), name='bias_2') self.weight_3 = Parameter(Tensor(np.random.randn(64, output_dims), dtype=mstype.float32), name='weight_3') self.bias_3 = Parameter(Tensor(np.zeros(output_dims), dtype=mstype.float32), name='bias_3') def construct(self, x): x1 = self.matmul(x, self.weight_1)+self.bias_1 x2 = self.matmul(x1, self.weight_2)+self.bias_2 x3 = self.matmul(x2, self.weight_3)+self.bias_3 return x3 def main(): epochs = 10000 dataset = create_dataset() net = Net(1, 1) # loss function loss = nn.MSELoss() # optimizer optim = nn.SGD(params=net.trainable_params(), learning_rate=0.000001) model = Model(net, loss, optim, metrics={'loss': nn.Loss()}) config_ck = CheckpointConfig(save_checkpoint_steps=10000, keep_checkpoint_max=10) ck_point = ModelCheckpoint(prefix="checkpoint_mlp", config=config_ck) model.train(epochs, dataset, callbacks=[ck_point, LossMonitor(1000)], dataset_sink_mode=False) np.random.seed(123) # 随机数生成种子 dataset = create_dataset() data = next(dataset.create_dict_iterator()) x = data['input'] y = data['output'] y_hat = model.predict(x) eval_loss = model.eval(dataset, dataset_sink_mode=False) print("{}".format(eval_loss)) fig=plt.figure(figsize=(8,6))#确定画布大小 plt.title("Dataset")#标题名 plt.xlabel("First feature")#x轴的标题 plt.ylabel("Second feature")#y轴的标题 plt.scatter(x.asnumpy(), y.asnumpy())#设置为散点图 plt.scatter(x.asnumpy(), y_hat.asnumpy())#设置为散点图 plt.show()#绘制出来 if __name__ == '__main__': """ 设置运行的背景context """ from mindspore import context # 为mindspore设置运行背景context # context.set_context(mode=context.PYNATIVE_MODE, device_target='GPU') context.set_context(mode=context.GRAPH_MODE, device_target='GPU') import time a = time.time() main() b = time.time() print(b-a)
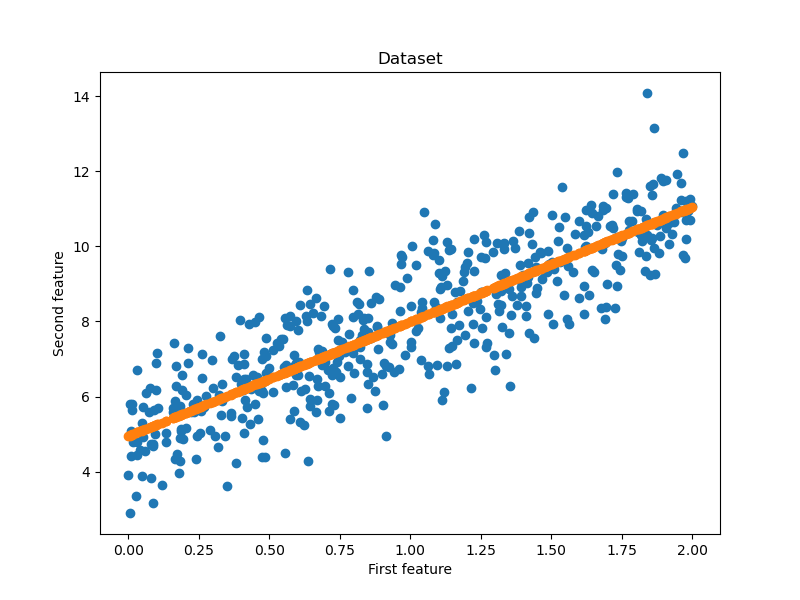
输入结果:

epoch: 1000 step: 1, loss is 1.0764071
epoch: 2000 step: 1, loss is 1.0253074
epoch: 3000 step: 1, loss is 1.0251387
epoch: 4000 step: 1, loss is 1.0251383
epoch: 5000 step: 1, loss is 1.0251379
epoch: 6000 step: 1, loss is 1.0251367
epoch: 7000 step: 1, loss is 1.0251377
epoch: 8000 step: 1, loss is 1.0251374
epoch: 9000 step: 1, loss is 1.0251373
epoch: 10000 step: 1, loss is 1.025136
{'loss': 1.0251359939575195}
62.462594985961914
可以看到使用系统提供的损失函数和优化器同样可以实现算法,但是很神奇的地方是算法的整体运算时间没有降低反而增加了,由前文中的41秒左右提高到了62秒左右,具体原因这里就不知道了,毕竟mindspore框架内部有很多其他的实现,如自动并行之类的,因此它的表现我们这里难以分析,这里只是作为功能尝试而已。