安装pytorch时我们一般都是会一并选择安装自带的视觉模型库 torchvision , 该库不仅有经典的视觉模型结构同时还提供了对应参数的下载功能,可以说torchvision库是十分方便于研究视觉的pytorch使用者来使用的。
给出pytorch的视觉库torchvision的GitHub地址:
https://github.com/pytorch/vision
该库中提供的模型结构定义文件:
pytorch官方也给出了对应torchvision库的一些介绍和使用说明:
https://pytorch.org/vision/stable/models.html

使用随机权重的torchvision中的视觉模型:
import torchvision.models as models resnet18 = models.resnet18() alexnet = models.alexnet() vgg16 = models.vgg16() squeezenet = models.squeezenet1_0() densenet = models.densenet161() inception = models.inception_v3() googlenet = models.googlenet() shufflenet = models.shufflenet_v2_x1_0() mobilenet_v2 = models.mobilenet_v2() mobilenet_v3_large = models.mobilenet_v3_large() mobilenet_v3_small = models.mobilenet_v3_small() resnext50_32x4d = models.resnext50_32x4d() wide_resnet50_2 = models.wide_resnet50_2() mnasnet = models.mnasnet1_0() efficientnet_b0 = models.efficientnet_b0() efficientnet_b1 = models.efficientnet_b1() efficientnet_b2 = models.efficientnet_b2() efficientnet_b3 = models.efficientnet_b3() efficientnet_b4 = models.efficientnet_b4() efficientnet_b5 = models.efficientnet_b5() efficientnet_b6 = models.efficientnet_b6() efficientnet_b7 = models.efficientnet_b7() regnet_y_400mf = models.regnet_y_400mf() regnet_y_800mf = models.regnet_y_800mf() regnet_y_1_6gf = models.regnet_y_1_6gf() regnet_y_3_2gf = models.regnet_y_3_2gf() regnet_y_8gf = models.regnet_y_8gf() regnet_y_16gf = models.regnet_y_16gf() regnet_y_32gf = models.regnet_y_32gf() regnet_x_400mf = models.regnet_x_400mf() regnet_x_800mf = models.regnet_x_800mf() regnet_x_1_6gf = models.regnet_x_1_6gf() regnet_x_3_2gf = models.regnet_x_3_2gf() regnet_x_8gf = models.regnet_x_8gf() regnet_x_16gf = models.regnet_x_16gf() regnet_x_32gf = models.regnet_x_32gf()
使用torchvision给出的权重及torchvision中的视觉模型:
import torchvision.models as models resnet18 = models.resnet18(pretrained=True) alexnet = models.alexnet(pretrained=True) vgg16 = models.vgg16(pretrained=True) squeezenet = models.squeezenet1_0(pretrained=True) densenet = models.densenet161(pretrained=True) inception = models.inception_v3(pretrained=True) googlenet = models.googlenet(pretrained=True) shufflenet = models.shufflenet_v2_x1_0(pretrained=True) mobilenet_v2 = models.mobilenet_v2(pretrained=True) mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True) mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True) resnext50_32x4d = models.resnext50_32x4d(pretrained=True) wide_resnet50_2 = models.wide_resnet50_2(pretrained=True) mnasnet = models.mnasnet1_0(pretrained=True) efficientnet_b0 = models.efficientnet_b0(pretrained=True) efficientnet_b1 = models.efficientnet_b1(pretrained=True) efficientnet_b2 = models.efficientnet_b2(pretrained=True) efficientnet_b3 = models.efficientnet_b3(pretrained=True) efficientnet_b4 = models.efficientnet_b4(pretrained=True) efficientnet_b5 = models.efficientnet_b5(pretrained=True) efficientnet_b6 = models.efficientnet_b6(pretrained=True) efficientnet_b7 = models.efficientnet_b7(pretrained=True) regnet_y_400mf = models.regnet_y_400mf(pretrained=True) regnet_y_800mf = models.regnet_y_800mf(pretrained=True) regnet_y_1_6gf = models.regnet_y_1_6gf(pretrained=True) regnet_y_3_2gf = models.regnet_y_3_2gf(pretrained=True) regnet_y_8gf = models.regnet_y_8gf(pretrained=True) regnet_y_16gf = models.regnet_y_16gf(pretrained=True) regnet_y_32gf = models.regnet_y_32gf(pretrained=True) regnet_x_400mf = models.regnet_x_400mf(pretrained=True) regnet_x_800mf = models.regnet_x_800mf(pretrained=True) regnet_x_1_6gf = models.regnet_x_1_6gf(pretrained=True) regnet_x_3_2gf = models.regnet_x_3_2gf(pretrained=True) regnet_x_8gf = models.regnet_x_8gf(pretrained=True) regnet_x_16gf = models.regnet_x_16gf(pretrained=True) regnet_x_32gf = models.regnet_x_32gf(pretrained=True)
有一点需要注意,那就是这些模型的预训练参数都是对数据进行正则化后再进行训练的,官方具体说明:

不过对于为什么要采用该种方式进行正则数据只给出了简单解释,这里我们暂且可以认为该种正则方式是习惯操作或惯例操作。
import torch from torchvision import datasets, transforms as T transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()]) dataset = datasets.ImageNet(".", split="train", transform=transform) means = [] stds = [] for img in subset(dataset): means.append(torch.mean(img)) stds.append(torch.std(img)) mean = torch.mean(torch.tensor(means)) std = torch.mean(torch.tensor(stds))
官方给出的解释是当时他们最原始编写代码时计算了一下数据集的均值与方差,然后并一直用这个数字来进行计算了。
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
从代码:
transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
dataset = datasets.ImageNet(".", split="train", transform=transform)
中可以看到官方原始操作时是将数据集中的数据进行resize,crop操作后在进行均值和方差计算的。
for img in subset(dataset):
means.append(torch.mean(img))
stds.append(torch.std(img))
分别求每张图片R G B三色中每一色像素的均值与方差。
mean = torch.mean(torch.tensor(means))
std = torch.mean(torch.tensor(stds))
对所有图片的R G B均值与方差求数据集范围的统计均值,最终得到:
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
官方给出补充解释:
Unfortunately, the concrete subset that was used is lost. For more information see this discussion or these experiments.
也就是原始数据集已经找不到了,但是我们即使使用其他数据集也已然按照惯例使用这个均值与方差,如果自己的数据集本身过小那么自己重新求这个均值与方差可能导致泛化性降低,而如果使用大数据集的话进行如此计算也十分耗计算资源,这可能也是领域内现在也惯例使用这个均值方差来进行数据正则的原因。
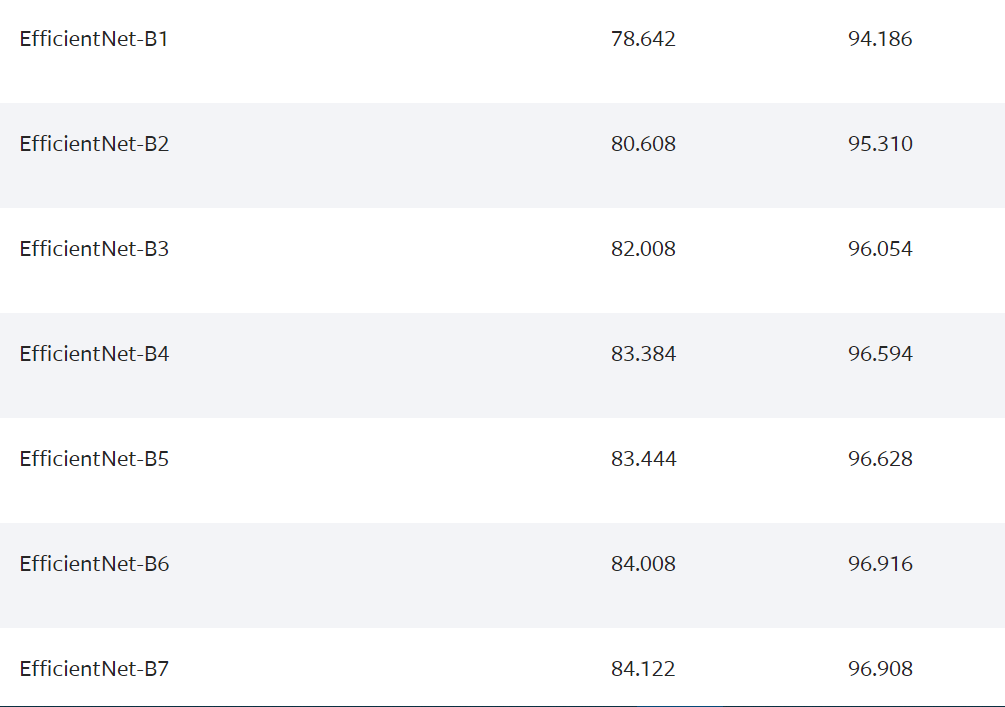
官方给出说明,对于 EfficientNet 网络来说模型的尺寸与变量有关。不过个人解读就是不同版本的EfficientNet模型其crop及input的size也是不同的,具体的size如下给出:
The sizes of the EfficientNet models depend on the variant. For the exact input sizes check here
例子中的代码设置:

====================================================