一。概述
提出了新的一种通过pattern来减少远程监督中的噪声。ARNOR认为一个可以信赖的关系的标签可以被神经网络解释的。ARNOR框架迭代的去学习一个可以解释的模型并利用它去选择新的可以信赖的实例。本文作者提出通过pattern来进行确定信赖的关系标签。
二。现状分析
在远程监督提出后,差不多有3种方式去减少远程监督中的噪音。
1.多实例学习
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 148–163. Springer.
Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 2124–2133.
Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati, and Christopher D Manning. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, pages 455–465. Association for Computational Linguistics.
Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1753– 1762.
2.强化学习或者对抗性训练去选择信赖的数据
Jun Feng, Minlie Huang, Li Zhao, Yang Yang, and Xiaoyan Zhu. 2018b. Reinforcement learning for relation classification from noisy data. In Proceedings of AAAI.
Pengda Qin, Weiran Xu, and William Yang Wang. 2018a. Dsgan: Generative adversarial training for distant supervision relation extraction. arXiv preprint arXiv:1805.09929.
Xu Han, Zhiyuan Liu, and Maosong Sun. 2018. Denoising distant supervision for relation extraction via instance-level adversarial training. arXiv preprint arXiv:1805.10959.
Zeng Xiangrong, Liu Kang, He Shizhu, Zhao Jun, et al. 2018. Large scaled relation extraction with reinforcement learning.
Pengda Qin, Weiran Xu, and William Yang Wang. 2018b. Robust distant supervision relation extraction via deep reinforcement learning. arXiv preprint arXiv:1805.09927.
3.基于pattern
Marti A. Hearst. 1992. Automatic acquisition of hyponyms from large text corpora. In COLING 1992 Volume 2: The 15th International Conference on Computational Linguistics.
Thierry Hamon and Adeline Nazarenko. 2001. Detection of synonymy links between terms: experiment and results. Recent advances in computational terminology, 2:185–208.
Jun Feng, Minlie Huang, Yijie Zhang, Yang Yang, and Xiaoyan Zhu. 2018a. Relation mention extraction from noisy data with hierarchical reinforcement learning. arXiv preprint arXiv:1811.01237.
三。ARNOR
总体架构:
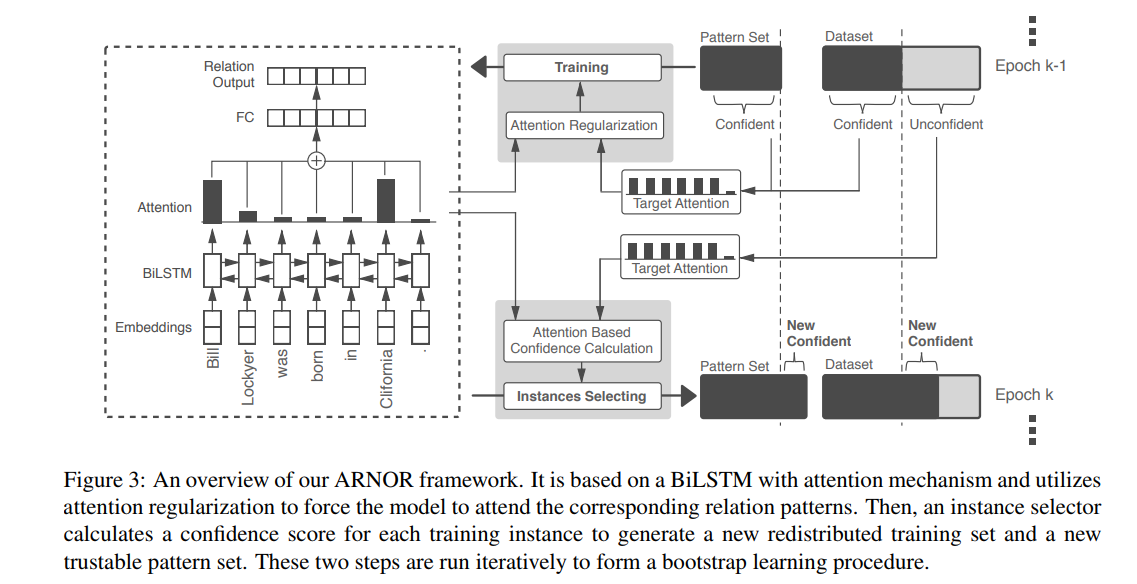
这个实验是通过bootstrap的方式进行类似增强学习的方式来进行pattern的新发现和feed to model操作
由上图,主要是两个步骤:attention regularization training 和 instance selection
模型分成几个小步骤:
1.Input Embeddings
包括三部分,word embedding和position embedding和entity type embedding.
2.Attention-based BiLSTM.
H = {hi}来表示bilstm的隐藏层向量。那么一个句子的输出可以通过如下方式:
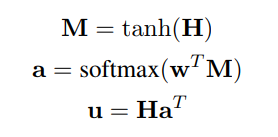
3. Training with Attention Regularization
这步可以说是整个论文的核心了
首先,进行一些表示。一个t个词的句子s表示为 x1,x2...xt。实体对e1.d2。关系标签为y。关系的pattern为m
根据输入m条件下的模式提及函数q(z|s, e1, e2, m),我们可以计算一个注意引导值am ( 下面的b用来表示xi是否属于实体对和关系pattern中) :
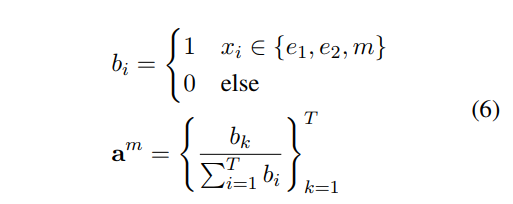
然后我们希望分类器能够将其注意分布as = p(z|s)近似到am,其中p表示神经网络分类器,提出kl散度作为 loss function:
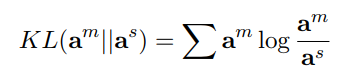
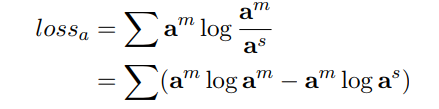
因为am为定值,

最后,我们将有损分析应用于分类损失,使注意力学习正规化。最后的损失(本次实验 β为1):
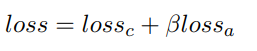
4.Instance Selection with Attention from Model
进行实例选择的时候,有一个置信度,置信度同样根据kl进行选择,超过一定阈值视为符合
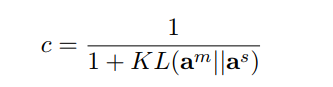
am为上个步骤式子6计算,as为神经网络的输出。
5.Bootstrap Learning Procedure

5.1 Relation Pattern Extraction
实际上,很一般的关系pattern抽取就能取得很好的效果,如果是更好的关系pattern抽取器,也能取得更好的效果。
本次实验中,只是进行了简单的关系pattern抽取。将两个entity中间的部分视为pattern,然后对每个关系类别都选取top10%的作为pattern。
5.2 Data Redistribution
所有positive的实例全部添加到正例set中。发现新的pattern,用于新的一轮的迭代。直到验证集的F1值消失。
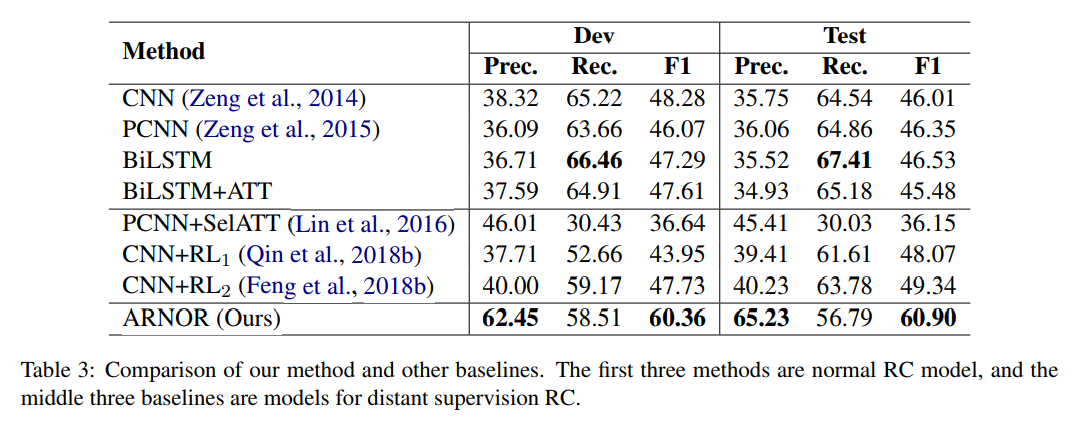
四。实验的数据集:

五,实验结果: