主要将模型的搭建移植到keras,参照上一篇博客。
新的差异主要如下:
1. 之前我们可以初始化一个tensor,可以通过tf.nn,或者tf.layers模块,有些模块中出现了重复的片段,因此新的版本保留的前提下, 引入了一个新的tensorflow.keras.layers全新的模块。
tf.keras.layers.Dense(units,activate,use_bais,input_size=[])
例如,全连接层改编为此,我们可以通过这个方式完成我们全连接层的搭建。
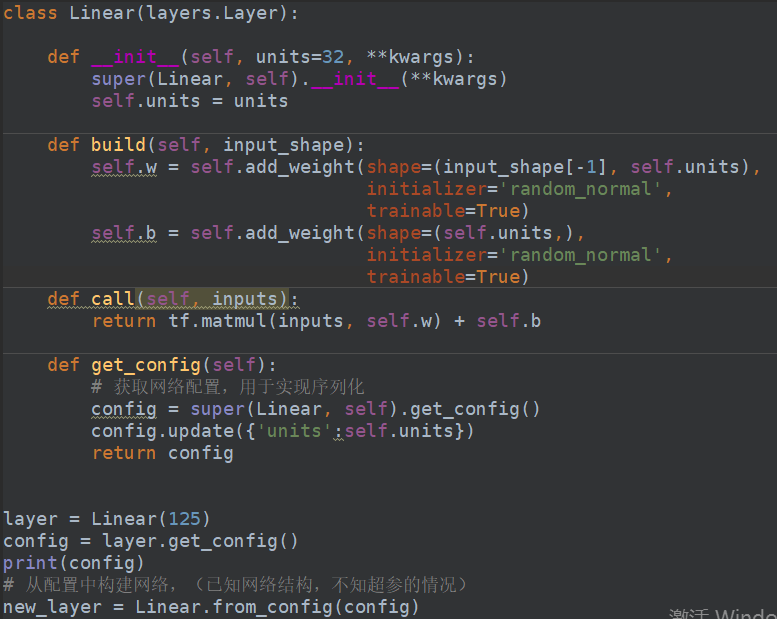
我们当然也可以通过继承 tf.keras.layers.Layer 类,重写build和call方法,build中我们需要把Input_shape作为我们的输入参数。call方法则是调用我们这个实例时,运行当前层。eg:
class MyDense(tf.keras.layers.Layer):
def __init__(self, n_outputs):
super(MyDense, self).__init__()
self.n_outputs = n_outputs
def build(self, input_shape):
self.kernel = self.add_variable('kernel',
shape=[int(input_shape[-1]),
self.n_outputs])
def call(self, input):
return tf.matmul(input, self.kernel)
layer = MyDense(10)
print(layer(tf.ones([6, 5])))
print(layer.trainable_variables)
# 残差块
class ResnetBlock(tf.keras.Model):
def __init__(self, kernel_size, filters):
super(ResnetBlock, self).__init__(name='resnet_block')
# 每个子层卷积核数
filter1, filter2, filter3 = filters
# 三个子层,每层1个卷积加一个批正则化
# 第一个子层, 1*1的卷积
self.conv1 = tf.keras.layers.Conv2D(filter1, (1,1))
self.bn1 = tf.keras.layers.BatchNormalization()
# 第二个子层, 使用特点的kernel_size
self.conv2 = tf.keras.layers.Conv2D(filter2, kernel_size, padding='same')
self.bn2 = tf.keras.layers.BatchNormalization()
# 第三个子层,1*1卷积
self.conv3 = tf.keras.layers.Conv2D(filter3, (1,1))
self.bn3 = tf.keras.layers.BatchNormalization()
def call(self, inputs, training=False):
# 堆叠每个子层
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = self.conv2(x)
x = self.bn2(x, training=training)
x = self.conv3(x)
x = self.bn3(x, training=training)
# 残差连接
x += inputs
outputs = tf.nn.relu(x)
return outputs
resnetBlock = ResnetBlock(2, [6,4,9])
# 数据测试
print(resnetBlock(tf.ones([1,3,9,9])))
# 查看网络中的变量名
print([x.name for x in resnetBlock.trainable_variables])
2. 目前有两种创建模型的方式,分别是函数式的方式和面向对象式的。

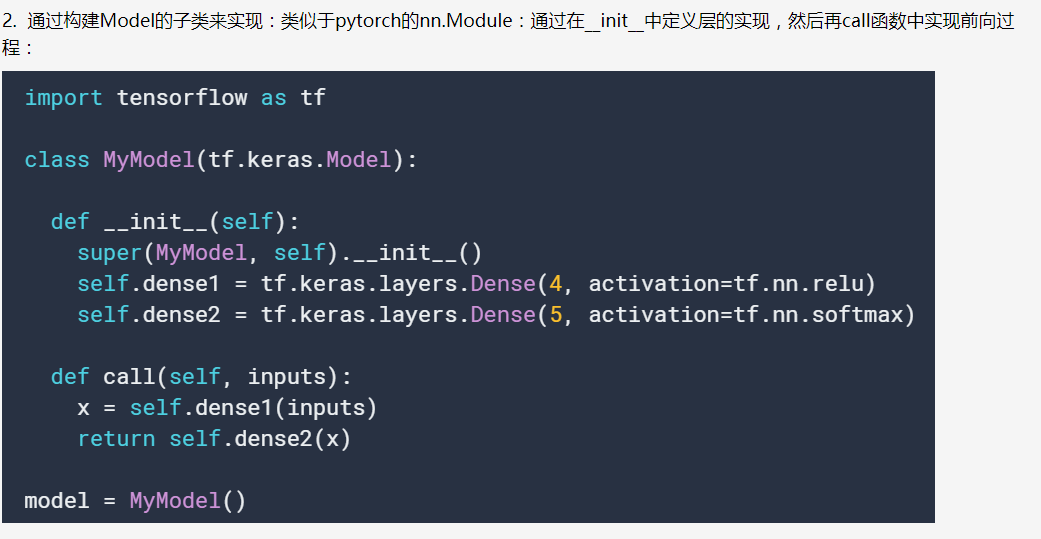
第二个方法中,我们就可以通过类似于pytorch的方式,完成我们的前向传递的调试过程,不需要再向tensorflow1中那样。
他们都是通过tf,keras.Model对象衍生出来的,可以通过该对象的方法完成训练评估等。详情见:https://www.cnblogs.com/king-lps/p/12743485.html

此方法用于model.compile完成模型的优化目标。其中,metrics可以传递我们的测评指标,包括不限于召回率精确率等。
函数式模式:
inputs = tf.keras.Input(shape=(784,), name='img')
# 以上一层的输出作为下一层的输入
h1 = layers.Dense(32, activation='relu')(inputs)
h2 = layers.Dense(32, activation='relu')(h1)
outputs = layers.Dense(10, activation='softmax')(h2)
model = tf.keras.Model(inputs=inputs, outputs=outputs, name='mnist_model') # 名字字符串中不能有空格
model.summary()
keras.utils.plot_model(model, 'mnist_model.png')
keras.utils.plot_model(model, 'model_info.png', show_shapes=True)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 将数值归到0-1之间
x_train = x_train.reshape(60000, 784).astype('float32') /255
x_test = x_test.reshape(10000, 784).astype('float32') /255
model.compile(optimizer=keras.optimizers.RMSprop(),
loss='sparse_categorical_crossentropy', # 直接填api,后面会报错
metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.2)
test_scores = model.evaluate(x_test, y_test, verbose=0)
print('test loss:', test_scores[0])
print('test acc:', test_scores[1])
还有一种通过tf.keras.Sequential()来创建模型,我们可以使用如下方式:
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
//优化的方式
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
//或
model.compile(optimizer=keras.optimizers.RMSprop(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
//或多个优化目标的权重
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={'score_output': keras.losses.MeanSquaredError(),
'class_output': keras.losses.CategoricalCrossentropy()},
metrics={'score_output': [keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()],
'class_output': [keras.metrics.CategoricalAccuracy()]},
loss_weight={'score_output': 2., 'class_output': 1.})
//训练
model.fit(train_x, train_y, batch_size=32, epochs=5)
//下面这种可以保证在验证集上的指标在多少轮次之后每次提升的性能指标低于阈值,则结束训练
callbacks = [
keras.callbacks.EarlyStopping(
# 不再提升的关注指标
monitor='val_loss',
# 不再提升的阈值
min_delta=1e-2,
# 不再提升的轮次
patience=2,
verbose=1)
]
model.fit(x_train, y_train,
epochs=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2)
//下面可以保证每次如果新的轮次中模型的性能在某个指标上得到了提升,那么把这个模型保存为filepath的路径下。
check_callback = keras.callbacks.ModelCheckpoint(
# 模型路径
filepath='mymodel_{epoch}.h5',
# 是否保存最佳
save_best_only=True,
# 监控指标
monitor='val_loss',
# 进度条类型
verbose=1
)
model.fit(x_train, y_train,
epochs=3,
batch_size=64,
callbacks=[check_callback],
validation_split=0.2)
//动态调整学习率
initial_learning_rate = 0.1
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
# 初始学习率
initial_learning_rate,
# 延迟步数
decay_steps=10000,
# 调整百分比
decay_rate=0.96,
staircase=True
)
optimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)
model.compile(
optimizer=optimizer,
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
//保存 加载
model.save_weights('./model.h5', save_format='h5')
model.load_weights('./model.h5')
//此处的test_scores里面包含了我们需要的loss和compile中的metrics
test_scores = model.evaluate(x_test, y_test, verbose=0)
print('test loss:', test_scores[0])
print('test acc:', test_scores[1])
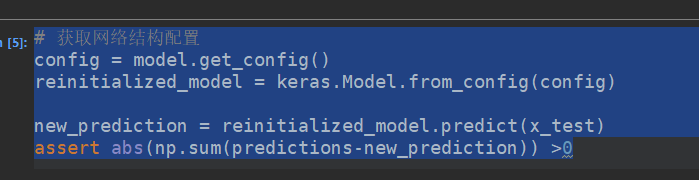
还可以从配置文件中去重新加载模型的结构,当然参数是没有的。

或者
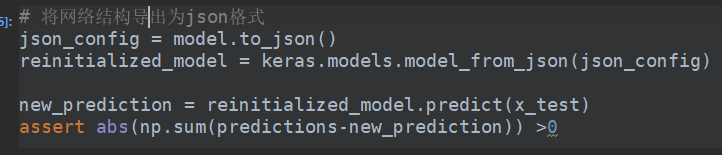
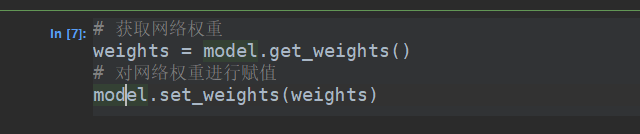
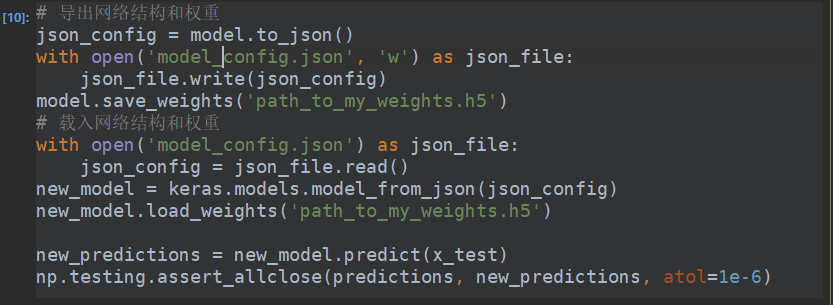

tensorflow2精化了很多,但是同时也保留了tensorflow1中的训练方式。
train_dataset = tf.data.Dataset.from_tensor_slices(x_train)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
original_dim = 784
vae = VAE(original_dim, 64, 32)
# 优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
# 损失函数
mse_loss_fn = tf.keras.losses.MeanSquaredError()
# 评价指标
loss_metric = tf.keras.metrics.Mean()
# 训练循环
for epoch in range(3):
print('Start of epoch %d' % (epoch,))
# 每批次训练
for step, x_batch_train in enumerate(train_dataset):
with tf.GradientTape() as tape:
# 前向传播
reconstructed = vae(x_batch_train)
# 计算loss
loss = mse_loss_fn(x_batch_train, reconstructed)
loss += sum(vae.losses) # Add KLD regularization loss
# 计算梯度
grads = tape.gradient(loss, vae.trainable_variables)
# 反向传播
optimizer.apply_gradients(zip(grads, vae.trainable_variables))
# 统计指标
loss_metric(loss)
# 输出
if step % 100 == 0:
print('step %s: mean loss = %s' % (step, loss_metric.result()))
loss_history = []
for (batch, (images, labels)) in enumerate(dataset.take(400)):
if batch % 10 == 0:
print('.', end='')
with tf.GradientTape() as tape:
# 获取预测结果
logits = mnist_model(images, training=True)
# 获取损失
loss_value = loss_object(labels, logits)
loss_history.append(loss_value.numpy().mean())
# 获取本批数据梯度
grads = tape.gradient(loss_value, mnist_model.trainable_variables)
# 反向传播优化
optimizer.apply_gradients(zip(grads, mnist_model.trainable_variables))
# 绘图展示loss变化
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel('Batch #')
plt.ylabel('Loss [entropy]')
callback作为fit的一个参数,可以自定义等等,需要继承keras.callbacks.CallBack类。
LR_SCHEDULE = [
# (epoch to start, learning rate) tuples
(3, 0.05), (6, 0.01), (9, 0.005), (12, 0.001)
]
def lr_schedule(epoch, lr):
if epoch < LR_SCHEDULE[0][0] or epoch > LR_SCHEDULE[-1][0]:
return lr
for i in range(len(LR_SCHEDULE)):
if epoch == LR_SCHEDULE[i][0]:
return LR_SCHEDULE[i][1]
return lr
model = get_model()
_ = model.fit(x_train, y_train,
batch_size=64,
steps_per_epoch=5,
epochs=15,
verbose=0,
callbacks=[LossAndErrorPrintingCallback(), LearningRateScheduler(lr_schedule)])
nlp:
常用的句子填充:
raw_inputs = [
[83, 91, 1, 645, 1253, 927],
[73, 8, 3215, 55, 927],
[711, 632, 71]
]
# 默认左填充
padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(raw_inputs)
print(padded_inputs)
# 右填充需要设 padding='post'
padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(raw_inputs,
padding='post')
print(padded_inputs)
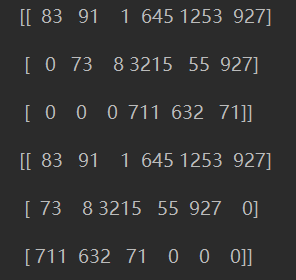
更一般的:
train_x = keras.preprocessing.sequence.pad_sequences(
train_x, value=word2id['<PAD>'],
padding='post', maxlen=256
)
test_x = keras.preprocessing.sequence.pad_sequences(
test_x, value=word2id['<PAD>'],
padding='post', maxlen=256
)
print(train_x[0])
print('len: ',len(train_x[0]), len(train_x[1]))
嵌入层:
inputs = tf.keras.Input(shape=(None,), dtype='int32')
x = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)(inputs)
outputs = layers.LSTM(32)(x)
//或者
class MyLayer(layers.Layer):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
self.embedding = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)
self.lstm = layers.LSTM(32)
def call(self, inputs):
x = self.embedding(inputs)
# 也可手动构造掩码
mask = self.embedding.compute_mask(inputs)
output = self.lstm(x, mask=mask) # The layer will ignore the masked values
return output
//引入nlp中常用的transformers,这个是mask的transformers
def scaled_dot_product_attention(q, k, v, mask):
# query key 相乘获取匹配关系
matmul_qk = tf.matmul(q, k, transpose_b=True)
# 使用dk进行缩放
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 掩码
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# 通过softmax获取attention权重
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
# attention 乘上value
output = tf.matmul(attention_weights, v) # (.., seq_len_v, depth)
return output, attention_weights
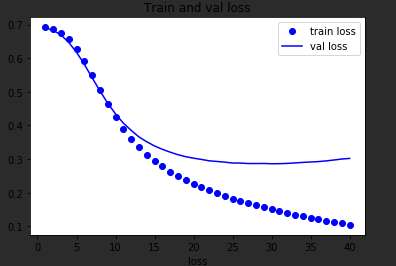
穿插一个plt的画图工具:
import matplotlib.pyplot as plt
history_dict = history.history
history_dict.keys()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, loss, 'bo', label='train loss')
plt.plot(epochs, val_loss, 'b', label='val loss')
plt.title('Train and val loss')
plt.xlabel('Epochs')
plt.xlabel('loss')
plt.legend()
plt.show()