http://eugenezhulenev.com/blog/2014/11/14/stock-price-prediction-with-big-data-and-machine-learning/
Apache Spark and Spark MLLib for building price movement prediction model from order log data.
The code for this application app can be found on Github
Synopsis
This post is based on Modeling high-frequency limit order book dynamics with support vector machines paper. Roughly speaking I’m implementing ideas introduced in this paper in scala with Spark and Spark MLLib. Authors are using sampling, I’m going to use full order log from NYSE (sample data is available from NYSE FTP), just because I can easily do it with Spark. Instead of using SVM, I’m going to use Decision Tree algorithm for classification, because in Spark MLLib it supports multiclass classification out of the box.
If you want to get deep understanding of the problem and proposed solution, you need to read the paper. I’m going to give high level overview of the problem in less academic language, in one or two paragraphs.
Predictive modelling is the process by which a model is created or chosen to try to best predict the probability of an outcome.
Model Architecture
Authors are proposing framework for extracting feature vectors from from raw order log data, that can be used as input to machine learning classification method (SVM or Decision Tree for example) to predict price movement (Up, Down, Stationary). Given a set of training data with assigned labels (price movement) classification algorithm builds a model that assigns new examples into one of pre-defined categories.
Time(sec) Price($) Volume Event Type Direction - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 34203.011926972 598.68 10 submission ask 34203.011926973 594.47 15 submission bid 34203.011926974 594.49 20 submission bid 34203.011926981 597.68 30 submission ask 34203.011926991 594.47 15 execution ask 34203.011927072 597.68 10 cancellation ask 34203.011927082 599.88 12 submission ask 34203.011927097 598.38 11 submission ask
In the table, each row of the message book represents a trading event that could be either a order submission, order cancellation, or order execution. The arrival time measured from midnight, is in seconds and nanoseconds; price is in US dollars, and the Volume is in number of shares. Ask - I’m selling and asking for this price, Bid - I want to buy for this price.
From this log it’s very easy to reconstruct state of order book after each entry. You can read more about order book and limit order book in Investopedia, I’m not going to dive into details. Concepts are super easy for understanding.
An electronic list of buy and sell orders for a specific security or financial instrument, organized by price level.
Feature Extraction and Training Data Preparation
After order books are reconstructed from order log, we can derive attributes, that will form feature vectors used as input to classification model.
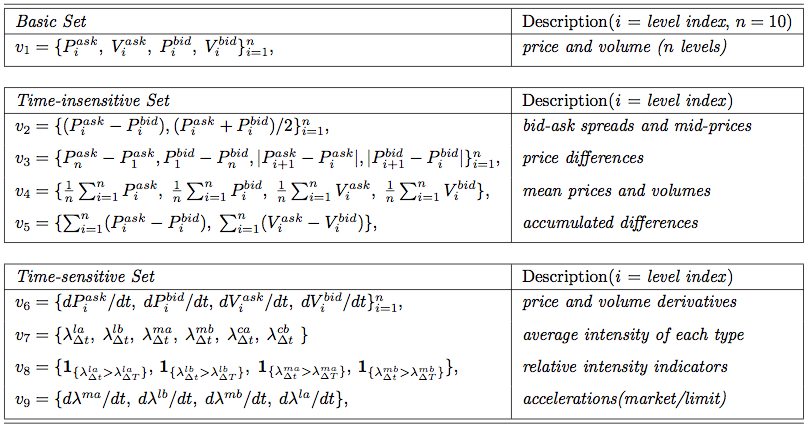
Attributes are divided into three categories: basic, time-insensitive, and time-sensitive, all of which can be directly computed from the data. Attributes in the basic set are the prices and volumes at both ask and bid sides up to n = 10 different levels (that is, price levels in the order book at a given moment), which can be directly fetched from the order book. Attributes in the time-insensitive set are easily computed from the basic set at a single point in time. Of this, bid-ask spread and mid-price, price ranges, as well as average price and volume at different price levels are calculated in feature sets v2, v3, and v5, respectively; while v5 is designed to track the accumulated differences of price and volume between ask and bid sides. By further taking the recent history of current data into consideration, we devise the features in the time-sensitive set. More about calculating other attributes can be found in original paper.
Labeling Training Data
To prepare training data for machine learning it’s also required to label each point with price movement observed over some time horizon (1 second fo example). It’s straightforward task that only requires two order books: current order book and order book after some period of time.
I’m going to use MeanPriceMove label that can be: Stationary, Up or Down.
trait Label[L] extends Serializable { label =>
def apply(current: OrderBook, future: OrderBook): Option[L]
}
sealed trait MeanPriceMove
object MeanPriceMove {
case object Up extends MeanPriceMove
case object Down extends MeanPriceMove
case object Stationary extends MeanPriceMove
}
object MeanPriceMovementLabel extends Label[MeanPriceMove] {
private[this] val basicSet = BasicSet.apply(BasicSet.Config.default)
def apply(current: OrderBook, future: OrderBook): Option[MeanPriceMove] = {
val currentMeanPrice = basicSet.meanPrice(current)
val futureMeanPrice = basicSet.meanPrice(future)
val cell: Cell[MeanPriceMove] =
currentMeanPrice.zipMap(futureMeanPrice) {
(currentMeanValue, futureMeanValue) =>
if (currentMeanValue == futureMeanValue)
MeanPriceMove.Stationary
else if (currentMeanValue > futureMeanValue)
MeanPriceMove.Down
else
MeanPriceMove.Up
}
cell.toOption
}
}
Order Log Data
I’m going to use NYSE TAQ OpenBook orders data, and parse it with Scala OpenBook library. It’s easiest data set to get, free sample data for 2 trading days is available for download at NYSE FTP.
TAQ (Trades and Quotes) historical data products provide a varying range of market depth on a T+1 basis for covered markets. TAQ data products are used to develop and backtest trading strategies, analyze market trends as seen in a real-time ticker plant environment, and research markets for regulatory or audit activity.
Prepare Training Data
OrderBook is two sorted maps, where key is price and value is volume.
case class OrderBook(symbol: String,
buy: TreeMap[Int, Int] = TreeMap.empty,
sell: TreeMap[Int, Int] = TreeMap.empty)
Feature Sets
I’m using Cell from Framian library to represent extracted feature values. It can be Value, NA or NM.
As defined in original paper we have three feature sets, first two calculated from OrderBook, last one requires OrdersTrail which effectively is window computation over raw order log.
sealed trait BasicAttribute[T] extends Serializable { self =>
def apply(orderBook: OrderBook): Cell[T]
def map[T2](f: T => T2): BasicAttribute[T2] = new BasicAttribute[T2] {
def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f)
}
}
sealed trait TimeInsensitiveAttribute[T] extends Serializable { self =>
def apply(orderBook: OrderBook): Cell[T]
def map[T2](f: T => T2): TimeInsensitiveAttribute[T2] = new TimeInsensitiveAttribute[T2] {
def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f)
}
}
trait TimeSensitiveAttribute[T] extends Serializable { self =>
def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T]
def map[T2](f: T => T2): TimeSensitiveAttribute[T2] = new TimeSensitiveAttribute[T2] {
def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T2] = self(ordersTrail).map(f)
}
}
and it’s how features calculation looks like
class BasicSet private[attribute] (val config: BasicSet.Config) extends Serializable {
private[attribute] def askPrice(orderBook: OrderBook)(i: Int): Cell[Int] = {
Cell.fromOption {
orderBook.sell.keySet.drop(i - 1).headOption
}
}
private[attribute] def bidPrice(orderBook: OrderBook)(i: Int): Cell[Int] = {
Cell.fromOption {
val bidPrices = orderBook.buy.keySet
if (bidPrices.size >= i) {
bidPrices.drop(bidPrices.size - i).headOption
} else None
}
}
private def attribute[T](f: OrderBook => Cell[T]): BasicAttribute[T] = new BasicAttribute[T] {
def apply(orderBook: OrderBook): Cell[T] = f(orderBook)
}
def askPrice(i: Int): BasicAttribute[Int] = attribute(askPrice(_)(i))
def bidPrice(i: Int): BasicAttribute[Int] = attribute(bidPrice(_)(i))
val meanPrice: BasicAttribute[Double] = {
val ask1 = askPrice(1)
val bid1 = bidPrice(1)
BasicAttribute.from(orderBook =>
ask1(orderBook).zipMap(bid1(orderBook)) {
(ask, bid) => (ask.toDouble + bid.toDouble) / 2
})
}
}
Label Training Data
To extract labeled data from orders I’m using LabeledPointsExtractor
class LabeledPointsExtractor[L: LabelEncode] {
def labeledPoints(orders: Vector[OpenBookMsg]): Vector[LabeledPoint] = {
log.debug(s"Extract labeled points from orders log. Log size: ${orders.size}")
// ...
}
}
and it can be constructed nicely with builder
val extractor = {
import com.scalafi.dynamics.attribute.LabeledPointsExtractor._
(LabeledPointsExtractor.newBuilder()
+= basic(_.askPrice(1))
+= basic(_.bidPrice(1))
+= basic(_.meanPrice)
).result(symbol, MeanPriceMovementLabel, LabeledPointsExtractor.Config(1.millisecond))
}
This extractor will prepare labeled points using MeanPriceMovementLabel with 3 features: ask price, bid price and mean price
Run Classification Model
In “real” application I’m using 36 features from all 3 feature sets. I run my tests with sample data from NYSE ftp, EQY_US_NYSE_BOOK_20130403 for model training and EQY_US_NYSE_BOOK_20130404 for model validation.
object DecisionTreeDynamics extends App with ConfiguredSparkContext with FeaturesExtractor {
private val log = LoggerFactory.getLogger(this.getClass)
case class Config(training: String = "",
validation: String = "",
filter: Option[String] = None,
symbol: Option[String] = None)
val parser = new OptionParser[Config]("Order Book Dynamics") {
// ....
}
parser.parse(args, Config()) map { implicit config =>
val trainingFiles = openBookFiles("Training", config.training, config.filter)
val validationFiles = openBookFiles("Validation", config.validation, config.filter)
val trainingOrderLog = orderLog(trainingFiles)
log.info(s"Training order log size: ${trainingOrderLog.count()}")
// Configure DecisionTree model
val labelEncode = implicitly[LabelEncode[MeanPriceMove]]
val numClasses = labelEncode.numClasses
val categoricalFeaturesInfo = Map.empty[Int, Int]
val impurity = "gini"
val maxDepth = 5
val maxBins = 100
val trainingData = trainingOrderLog.extractLabeledData(featuresExtractor(_: String))
val trainedModels = (trainingData map { case LabeledOrderLog(symbol, labeledPoints) =>
log.info(s"$symbol: Train Decision Tree model. Training data size: ${labeledPoints.count()}")
val model = DecisionTree.trainClassifier(labeledPoints, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
val labelCounts = labeledPoints.map(_.label).countByValue().map {
case (key, count) => (labelEncode.decode(key.toInt), count)
}
log.info(s"$symbol: Label counts: [${labelCounts.mkString(", ")}]")
symbol -> model
}).toMap
val validationOrderLog = orderLog(validationFiles)
log.info(s"Validation order log size: ${validationOrderLog.count()}")
val validationData = validationOrderLog.extractLabeledData(featuresExtractor(_: String))
// Evaluate model on validation data and compute training error
validationData.map { case LabeledOrderLog(symbol, labeledPoints) =>
val model = trainedModels(symbol)
log.info(s"$symbol: Evaluate model on validation data. Validation data size: ${labeledPoints.count()}")
log.info(s"$symbol: Learned classification tree model: $model")
val labelAndPrediction = labeledPoints.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val trainingError = labelAndPrediction.filter(r => r._1 != r._2).count().toDouble / labeledPoints.count
log.info(s"$symbol: Training Error = " + trainingError)
}
}
}
Training Error
Output of running Decision Tree classification for single symbol ORCL:
ORCL: Train Decision Tree model. Training data size: 64064 ORCL: Trained model in 3740 millis ORCL: Label counts: [Stationary -> 42137, Down -> 10714, Up -> 11213] ORCL: Evaluate model on validation data. Validation data size: 54749 ORCL: Training Error = 0.28603262160039455
As you can see this pretty simple model was able to successfully classify ~70% of the data.
Remark: Despite the fact, that this model shows very good success rate, it doesn’t mean that it can be successfully used to build profitable automated trading strategy. First of all I don’t check if it’s 95% success predicting stationary and 95% error rate predicting any price movement with average 70% success rate. It doesn’t measure “strength” of price movement, it has to be sufficient to cover transaction costs. And many other details that matters for building real trading system.
For sure it’s huge room for improvement and result validation. Unfortunately it’s hard do get enough data, 2 trading days is to small data set to draw conclusions and start building system to earn all the money in the world. However I think it’ a good starting point.
Results
I was able to relatively easy reproduce fairly complicated research project at much lager scale than in original paper.
Latest Big Data technologies allows to build models using all available data, and stop doing samplings. Using all of the data helps to build best possible models and capture all details from full data set.
The code for this application app can be found on Github