https://www.cnblogs.com/yxy8023ustc/p/3421146.html
感谢Blog主要从这里翻译过来:
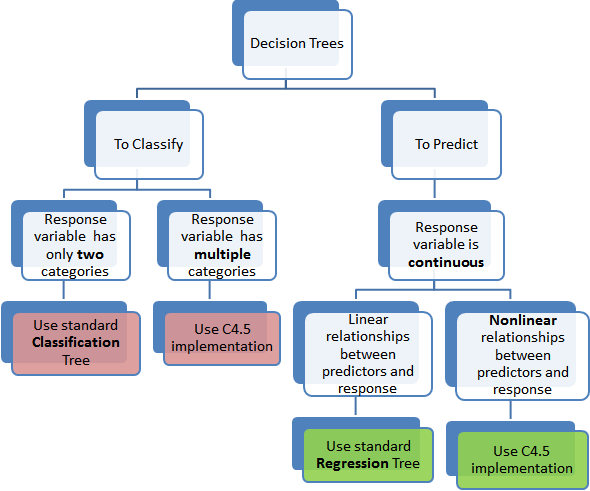
对于技术领域众多的预测工具,决策树是其中比较普遍和容易理解的,而决策树中又以分类树和回归树为主要方法,这边文章主要介绍一下他们的使用条件以及算法上的不同之处。
不同点1:
分类树主要用于将数据集分类到响应变量所对应的不同类别里,通常响应变量对应两类0 or 1. 如果目标变量对应了2个以上的类别,则需要使用分类树的一个扩展版C4.5(很popular)。然而对于一个二分类问题,常常使用标准的CART算法。不难看出分类树主要用于响应变量天然对应分类的情况。
回归树主要用于响应变量是数值的或者连续的,例如预测商品的价格,其适用于预测一些非分类的问题。
【注意:预测源或者说自变量也可能是分类的或者数值的,但决策树的选择只和目标变量的类型有关】
不同点2:
标准分类树的思想是根据数据的相似性(homogeneity)来进行数据的分类。举一个简单的例子就是:****。对于标准的非纯度计算,一般会基于一个可计算的模型,比如entropy 或者Gini index通常用来量化分类树的均匀性。
用于回归树里的目标变量是连续的,我们通常用自变量拟合一个回归模型。然后对于每个自变量,数据被几个分割点分离。在每个分割点,最小化预测值和真实值的误差和 (SSE)得到回归模型的分类方法。
`(2 + 2 = 5)`
We discussed a C4.5 classification tree (for more than 2 categories of target variable) here which uses information gain to decide on which variable to split. In a corresponding regression tree, standard deviation is used to make that decision in place of information gain. More technical details are here. Regression trees, by virtue of using regression models lose the one strength of standard decision trees: ability to handle highly non-linear parameters. In such cases, it may be better to use the C4.5 type implementation.