

桔妹导读:滴滴数据通道引擎承载着全公司的数据同步,为下游实时和离线场景提供了必不可少的源数据。随着任务量的不断增加,数据通道的整体架构也随之发生改变。本文介绍了滴滴数据通道的发展历程,遇到的问题以及今后的规划。
1. 背景
数据,对于任何一家互联网公司来说都是非常重要的资产,公司的大数据部门致力于解决如何更好的使用数据,挖掘数据价值,而数据通道服务作为“大数据”的前置链路,一直以来都在默默的为公司提供及时,完整的数据服务,这里我们对滴滴数据通道的演进做一个全面的介绍。
2. 数据通道简介
数据通道服务,顾名思义,是数据的通路,负责将数据从A同步到B的一套解决方案。
异构数据的同步是公司很多业务的普遍需求,通道服务也就成为了一项基础服务。包括但不限于日志,Binlog同步到下游各类存储和引擎中,如HIVE,ES,HBase等,用于报表,运营等场景。
数据通道方案本身涉及的组件很多,链路也比较复杂,这里通过一个简化的有向图来介绍下通道的核心流程。
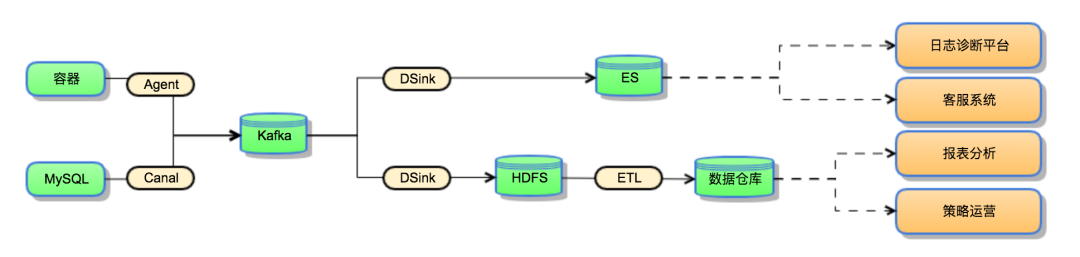
有向图的顶点表示存储,包括磁盘,消息队列以及各种存储服务,边和方向表示数据流量,而数据流动的动力则是边上的各个同步引擎。仅从图中的链路可以看出,基础组件包括以下几种:
| 组件名称 | 组件说明 |
|---|---|
| 容器 | 业务方运行的容器是数据产生的地方,是异构数据的原始数据,包括业务日志和Binlog等。 |
| Agent | Agent负责数据采集,常见的远端数据包括普通日志和Binlog,Agent负责将这类数据采集后发送到消息队列中,通过读取文件,并记录offset的方式,保证至少一次的数据采集服务。 |
| Kafka | 消息队列的加入主要用于数据复用,削峰填谷以及上下游解耦。采集一份数据,多个下游可以根据需要消费后自行处理,同时借用消息队列的高吞吐能力,减少上下游的耦合,在流量突增的时候可以起到缓冲的效果。 |
| DSink | DSink组件是公司内对数据投递服务的简称,主要负责消费MQ数据投递到下游存储,通过消息队列的OffSet保证至少一次的数据投递。 |
| ES/HDFS | 存储引擎,异构数据通过上述投递服务,完成结构化处理,投递到下游存储中,供业务方使用。 |
| ETL | 写入HDFS数据一般来说都是作为业务方ETL的输入,经过自定义的处理逻辑后写入HIVE,供分析和计算使用。 |
| 数据仓库 | 数据仓库中保存结构化的数据,方便业务系统或者下游级联使用。 |
| 各类业务系统 | 业务系统直接对接ES或者数据仓库,提供线上或者准线上服务。 |
3. 数据通道服务的演进
数据通道致力于解决异构数据同步的问题,从开始构建到现在,经历了组件平台化,服务化,产品化,引擎升级和智能化几个阶段,每个阶段都面临着各种各样的问题,而问题的解决都伴随着系统稳定性,可靠性的提升。
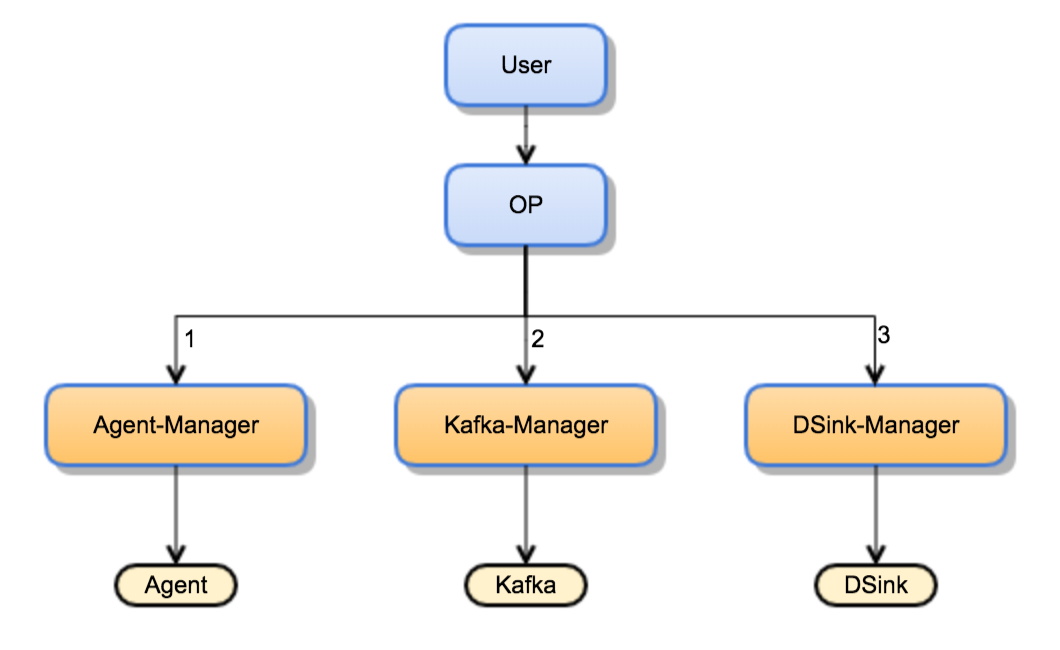
3.1 组件平台化
目标:更好地服务业务
数据通道构建初期,各个组件各自维护,为业务方提供数据服务,业务有需求过来的时候各个组件快速启动一个进程就可以为业务方提供一个端到端的数据通路,业务拿到数据就可以分析计算,完整相关的业务指标。随着业务发展,需求不断增多,经过了一段时间的野蛮增长后,通道的任务数也水涨船高,大量的任务需要规范的平台来管控,因此在通道服务活下来以后第一件需要做的事就是组件平台化,这么多任务需要有一个统一的管控平台管理起来,方便根据用户的需求,新建修改或者删除任务。
3.2 服务化
目标:承诺SLA
面临问题:如何保证各个环节的At Least Once数据的完整性和及时性是下游服务关注的重点,完整性是基础,在这之上尽可能保障及时性。对于下游来说,可以容忍短暂的延迟,但是不能数据数据不准确的情况,因此,自下而上的,通道服务要为自己同步的数据负责。要为下游提供一致性服务,一方面需要各个组件能够提供At Least Once的语义保证,另外一方面则需要一个数据质量中心对外提供数据质量服务。

介绍一个简单的场景:DSink在数据同步过程中如何实现At Least Once数据投递服务DSink是消费MQ消息,投递到下游存储,MQ以Kakfa为例,DSink在投递的过程中是异步多线程同时投递,那怎么保证数据投递完成之后提交准确的offset呢,毕竟一个partition的数据会分不到多个线程中同时投递,投递的下游可能会因为网络或者压力的原因失败,还需要重试。方案一:一批数据都投递完成后再继续消费,也就是全部投递成功之前阻塞上游消费,这样可以保证提交的offset是准确的。但是这样就会有性能问题,在日志场景下会严重影响性能。方案二(DSink采用方案):使用TreeMap保存offset,Map的value为一个范围,A-B的offset范围,Key则为这个范围的最小值A,每次有一个partition的offset处理成功后则加入到TreeMap中,具体过程如下:
 定时提交offset时只需要获取Map中第一个Entry value的结束offset进行提交即可。
定时提交offset时只需要获取Map中第一个Entry value的结束offset进行提交即可。
offset经过这种处理,可以保证每次提交的offset都是准确的,完成投递的数据,基于此,DSink实现了At Least Once语义。
3.3 产品化
目标:提升用户体验
数据通道服务渐渐完善后,接入的需求也越来越多,遇到的问题也与日俱增,比较直观的一点就是答疑量上升,一方面用户需求的接入是通过邮件或者钉钉,开发同学需要根据需求手动创建任务;另一方面用户的不规范配置会影响任务运行,当数据不产出或者产出有问题时需要引擎同学定位解决,答疑的大部分精力都耗在这些问题之上。数据通道服务是随着公司发展一起发展起来的,众所周知,在发展初期,缺乏各种规范,业务方的日志或者MySql表差异很大,遵循的规范也是五花八门,或者根本就没有规范,为了数据通道服务的标准化和自动化,我们通过产品的方式规范用户数据,符合我们规范的数据可以自动接入,而其他乱七八糟的格式则需要整改后再接入。为了解决这些问题,数据通道孵化了统一的接入平台——同步中心,在该平台之上用户通过点击配置的方式完成任务创建,同步中心会将用户需求拆分到各个通道引擎管控平台,各个管控平台再根据配置自行创建任务运行,最后回调同步中心,整个过程实现自动化。经过这一改造,任务创建时间从原来的平均几个小时降到5-10分钟,极大的提升了用户体验。

3.4 引擎升级——Flink(StreamSQL)
目标:降成本,模板化
DSink组件运行在公司的统一的容器内,在申请容器的时候为了减少碎片及便于管理,容器的规格只有固定的几种,如4C8G,8C16G,16C32G等,不同的任务都只能在这些规格中选择,这样就会导致资源的浪费,比如一个需要10个VCORE的任务,就只能申请16C的容器,大部分情况CPU会空闲一部分,同时内存也只能浪费。引擎升级,将投递组件升级到Flink引擎之上主要有以下收益:
- Flink是基于yarn来调度资源,最小的单位是1C1G,通过计算,可以对每一个任务的资源进行精准控制,尽可能的减少资源浪费。
- 投递引擎切换到StreamSQL后,所有任务都通过SQL表达,统一了任务模版。StreamSQL的UDF特性可以支持用户自定义解析逻辑,基础SQL可以支持写入下游ES或者HDFS等存储,而用户逻辑增加UDF后即可直接写入。这一方面减少用户重复开发的工作量,另一方面也拓展了数据通道的服务范围。
通过这一次引擎升级,通道任务从原来的400台物理机,切换到StreamSQL,只需要约250台物理机。CPU的峰值利用率也从不到30%提升到60%+。
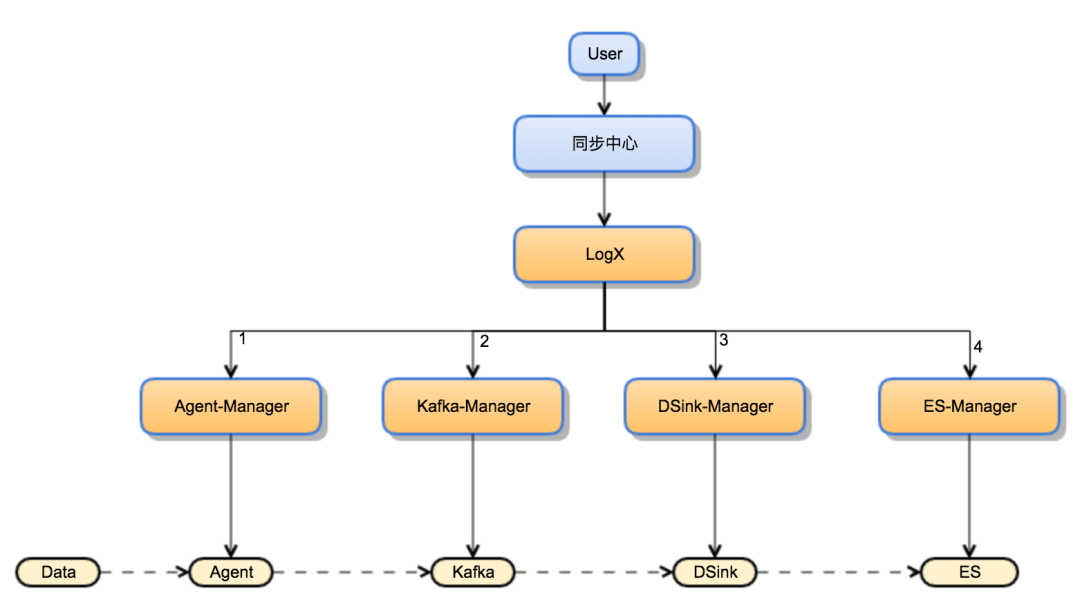
3.5 智能化(进行中)
目标:问题诊断与数据治理
随着任务数的接入越来越多,不可避免的,引擎的各类问题也越来越多,当前主要是用户问题驱动或者延迟告警来发现问题,之后依赖于各个引擎的指标大盘定位问题,再由人工来解决各类引擎问题。实际上当前有相当一部分简单问题是可以自动化处理的,比如资源不足,如果发现延迟的原因是资源不足,则可以直接扩资源即可。鉴于此,我们规划了一套问题发现与自动化处理的智能诊断与解决方案——LogX,期望基于这个方案可以解决引擎侧80%的日常问题。LogX组件的职责如下:
- 统筹整个链路资源,根据用户任务,分配各个下游引擎资源
- 问题诊断和自动化处理——基于各类指标,完成问题智能分析和诊断,对于常见问题可以自动化处理,减少人工干预
- 全链路血缘建设——根据血缘关系识别重点项目,分级保障
- 全链路数据治理——基于血缘关系完成数据治理,减少不比要的任务,进一步提升资源利用率
因为涉及到各个引擎的指标与自动化,当前该组件正在持续推进中,相信不久就可以作为通道的核心服务之一服务于引擎和公司业务了。
4. 总结
数据通道服务承载着全公司的数据同步,绝大部分离线任务的数据源都是通道服务投递的,可以说当前的通道服务是整个滴滴数据的大动脉。经过这几年的发展,通道服务也逐渐趋于完善,持续稳定的为公司提供数据采集和投递服务。

团队介绍
滴滴云平台事业群滴滴大数据架构部实时数据引擎组负责Flink流批一体计算、Kafka消息队列、日志采集与通道等核心数据引擎的研发与应用,承担全公司的数据采集、投递以及实时计算任务, 致力于打造稳定可靠、高性能、低成本的计算与通道服务。
作者介绍
 **
**
专注于大数据实时引擎技术,致力于数据通道全链路建设,基于各类实时引擎,为公司提供稳定,可靠,高效,及时的数据通道服务。
延伸阅读



内容编辑 | Charlotte
联系我们 | DiDiTech@didiglobal.com

本文由博客群发一文多发等运营工具平台 OpenWrite 发布