1、变量
为了节省内存,python解释器会对一些简单的字符串以及小整型数,做出一些优化,当要定义的新变量的内容与定义过的内容相同时,会让两者使用同一个内存空间。
例如:
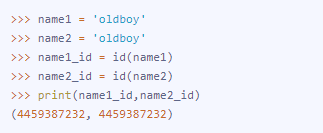
在这个例子里面,‘old’是一个简单的字符串,因此python解释器使name1与name2都指向同一个内存地址,用这一个地址存储‘oldboy’。
注意:对于长字符串和数字(对于范围在【-5,257】的数字,优化机制仍存在),优化机制将不再存在,变量将会各自占用一个内存地址。
小伙伴们要记得哦,查看内存地址时,使用id()这个命令哦!
2、字符编码
①ASCII,最早只有127个字母,即大小写英文字母、数字和一些符号,后128位被称为扩展ASCII码。
②GBK和GB2312:为了能显示中文,并且和ASCII兼容 ,中国制定GB2312.。而GBK是GB2312的扩展字符集,支持繁体字,且兼容GB2312.
③Unicode:把各国的编码语言都统一到一套编码里,防止乱码的问题。值得注意的是:现代操作系统和大多数编程语言都直接支持Unicode。ASCII与Unicode的区别:ASCII编码是1个字节,而Unicode编码通常是两个字节。
小伙伴们,是不是觉得Unicode很厉害呦,但同时与ASCII一比较,有没有看出一个问题,那就是:如果都统一成Unicode编码,我们肯定对不用担心乱码的问题了,但是若文本都是英文的话,用Unicode编码就多占了一部分的存储空间,而传输速度也会减慢。
④UTF-8:为了改良Unicode的缺点,UTF-8诞生。UTF-8是一个‘可变长编码’,即UTF-8编码可以把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英语字母被编码成1个字节,汉字通常是3个字节,仅一些生僻字符被编码成4-6个字节。
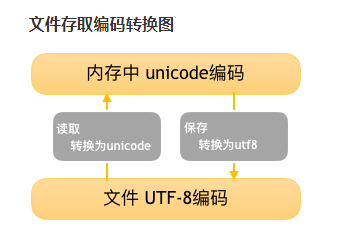
总结:计算机系统通用的字符编码的工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或需要传输的时候,就转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存时再将Unicode转换为UTF-8保存到文件中。具体见下图:
3、进制转换
bin():转换为二进制,二进制前面标注为0b。oct():转换为八进制,八进制前面标注为0o。hex():转换为16进制,16进制前面标注为0x。

4.字符串(常用操作)
例如 s = ‘world’
s.index() #索引
s.find () #查找
#移除空白:
s.lstrip = left strip = 去除字符串左边的 = strip leading = 去除(字符串)开始的
s.rstrip = right strip = 去除字符串右边的
s.strip = strip left and right = 去除(字符串)左边的和右边的
len(s) #字符串s的长度
#替换:
s = ‘hello world’
s.replace('h','H') #将h替换为H
输出:‘Hello world’
#切片
s = ‘helloworld’
s[0:7] #取出0到6,即取头不取尾
输出:hellowo
5、字符串中的工厂函数(常用的总结如下):
例如:s = ‘Hello world’
s.capitalize() #将首字母大写,其它的均小写
s.count('o') #统计字符串中o出现的次数 s.count(‘o’,0,5) #统计字符串s中0-5字符中o出现的次数
s.center(50,'*') #一共占用50个字符,不够50个字符,则用*来填充,而目标文字s始终位于中间位置
s.find('o',0,3) #从字符串s中位于0-3位置的字符中寻找‘o’,返回所找到的最小索引值
s.format() #格式化输出,如下图所示

s.index('o',0,5) #返回0-5字符中找到o的位置的索引值,但若没有找到,则会报Valueerror
s.join() #举例如下:

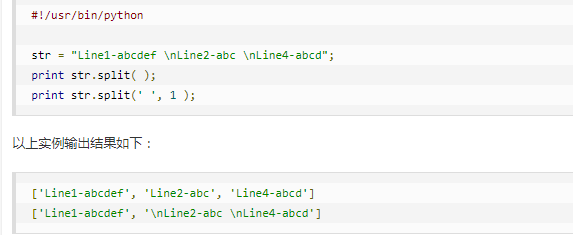
s.split():


使用方法如下:
s.join()
