倒排索引架构
在广告系统中倒排索引起着至关重要的作用,当请求过来时,需要根据定向信息从倒排索引中匹配合适的广告。我们的倒排索引采用的是ElasticSearch(后面简称ES),考虑点是社区活跃,相关采集、可视化、监控以及报警等组件比较完善,同时ES基于java开发,所以调优和二次开发相对方便
先看下我们的倒排索引的架构图
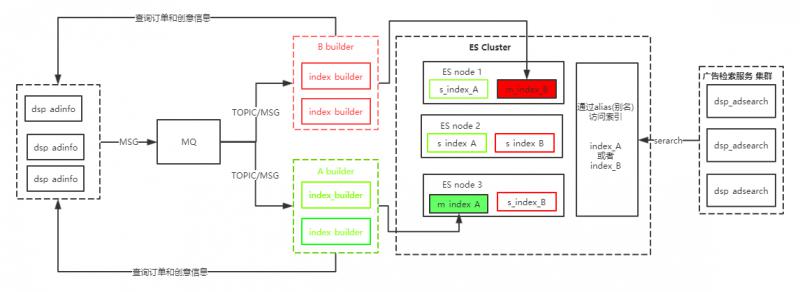
这个架构设计成如上图这样,经过了下面的思考与迭代
索引问题与优化
单点与稳定性问题
采用多节点部署
其中 A builder和 B builder都是两个节点,一个主和一个备,他们通过争抢锁(用zookeeper实现)来决定谁是主
多个节点会带来数据不一致问题
-
多生产者多消费者产生消息时序问题
把消息设置成无状态的
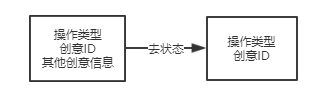
查询数据库获取最新数据(订单和创意更新频率低,所以对数据库压力不大)
-
因为出异常导致数据不一致
采用重试(幂等)和定时任务处理异常
-
全量更新索引,影响线上索引查询功能
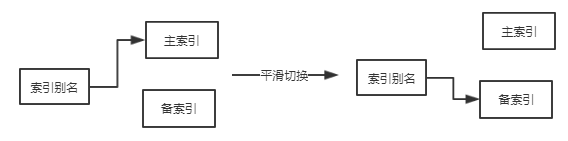
采用主备索引
主备索引切换流程:更新备用索引->验证备用索引->主备切换->更新主索引
索引查询与重建索引问题与优化
压测ES QPS不高、CPU负载高、YGC频繁、索引重建索引耗时长
我们分别从查询和重建两个方向来看
查询
-
1s一次YGC,STW约10ms,对低延迟系统影响较大
调整 -Xmn 3g->7g,调整后10s一次YGC,STW约12ms
调整前YGC频繁,对低延迟系统影响较大,所以想增大YGC的时间间隔,降低性能抖动,考虑到YGC采用复制算法,每次垃圾回收时间主要包括扫描年轻代存活对象和复制存活对象,扫描对象的成本远低于复制对象,所以YGC的时间主要取决于存活对象的数量,在对象生命周期没有较大变化的情况下,YGC的时间自然不会有较大变化
调整后,YGC的时间间隔有了很大改善,GC时间并没有线性增加
-
调整分片数和副本数,减少线程损耗、较少IO
ES默认分片数是5,默认条件下,索引会被分配到不同的节点,这样每个节点只有部分索引,会导致一次请求需要合并多个节点的数据,IO数多
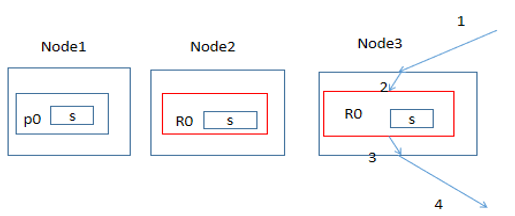
如图所示,假设有3个节点,2个主分片,每个分片有一个副本。当一次查询过来的时候
查询流程大致为:首先是node3收到请求,它可能会把请求转发到node2的R0或node1的P0,然后完成检索后把数据汇集到node3,最后返回。其中每个索引的内部,数据会保存到多个segment中,而对segment的查询是串行的
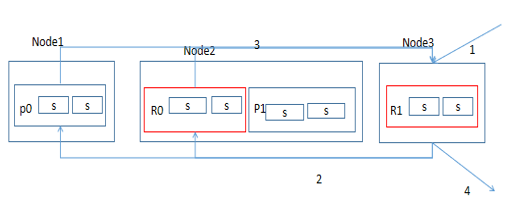
而我们的场景是请求量大,索引小(100M以内),所以把主分片调整为1,副本调整为节点数-1,这样能保证每个节点都存储所有索引,这样只会有一次io操作,如下图所示
-
ES(lucencu) 串行读取所有segment
索引更新会使segment数量增加,es对segment的查询是串行的,所以我们采用每分钟定时用 _forcemerge将segment降为1
-
热点方法排查发现JSON反序列化占50%cpu
禁用source只采用field存储必要字段
-
指定查询偏向本机节点
设置preference:_local
重建
-
全量重建前关闭从分片,禁用实时索引
replicas:0 refresh_interval:-1
减少索引在重建过程中索引同步带来的消耗
-
批量重建索引
使用 bulk批量重建索引,提高建索引的性能
后记
我们采用的方案,有些并不符合业界常用和推荐的方式,但是符合我们自己的业务,所以方案一定要适合自己团队的业务,没有最好的方案,只有更适合的方案