BN的出现大大解决了训练收敛问题。作者主要围绕归一化的操作做了一系列优化思路的阐述,值得细看。
Batch Normalization: Accelerating Deep Network Training
by Reducing Internal Covariate Shift
-
深度网络为什么难训练?
因为internal covariate shift
- internal covariate shift:在训练过程中,每层的输入分布因为前层的参数变化而不断变化
- 从不同的角度说明问题internal covariate shift
1.SGD训练多层网络
总损失是 ,当
,当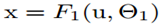 ,损失转换为
,损失转换为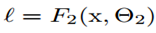
梯度更新是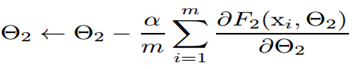
当x的分布固定时候,训练 是容易收敛的。而当x的分布不断变化时候,需要不断调整去修正x分布的变化带来的影响
是容易收敛的。而当x的分布不断变化时候,需要不断调整去修正x分布的变化带来的影响
2.易进入饱和状态
什么是饱和状态?以sigmoid为例,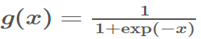 ,当|x|增加,
,当|x|增加,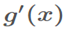 趋向于0,称为饱和状态。(梯度消失,模型将缓慢训练)。这里
趋向于0,称为饱和状态。(梯度消失,模型将缓慢训练)。这里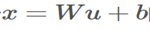 x受W、b和前面层参数的影响,训练期间前面层参数的变化可能会将x的许多维度移动到非线性的饱和状态并收敛减慢。且这个前层的影响随着网络深度的增加而放大。
x受W、b和前面层参数的影响,训练期间前面层参数的变化可能会将x的许多维度移动到非线性的饱和状态并收敛减慢。且这个前层的影响随着网络深度的增加而放大。
- BN之前的做法 :1.较低的学习率,但减慢了收敛速度。2.谨慎的参数初始化。3.ReLU代替sigmoid
-
如何解决internal covariate shift,BN的思考起源:
whitened(LeCun et al,1998b),对输入进行白化即输入线性变化为具有0均值和单位方差,并去相关。使用白化来进行标准化(normalization),以此来消除internal covariate shift的不良影响由于whitened需要计算协方差矩阵和它的平方根倒数,而且在每次参数更新后需要对整个训练集进行分析,代价昂贵。因此寻求一种可替代的方案,BN。
-
Batch Normalization
在白化的基础上做简化:
简化1,单独标准化每个标量特征(每个通道)
简单标准化可能改变该层的表达能力,以sigmoid层为例会把输入约束到线性状态。因此我们需要添加新的恒等变换去抵消这个(scale操作)。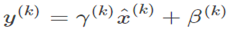
简化2,mini-batch方式进行normalization。计算过程如图:

为了数值稳定, 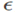 是一个加到方差上的常量。
是一个加到方差上的常量。
-
Batch Normalization的求导
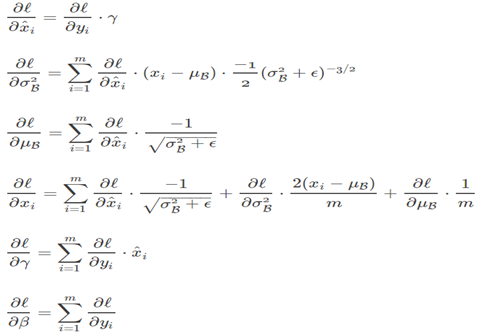
-
BN的训练和预测
训练时取决于当前batch的输入。
预测需要用总体统计来进行标准化。训练完成后得到均值参数 和方差参数
和方差参数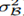 :
:

-
网络中加入BN
仿射(线性)变换和非线性变换组成用下式表示: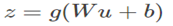
其中g是非线性如sigmoid。当normalization非线性输出时,它的分布形状可能会改变无法消除internal covariate shift。
而线性 更加具有对称性,非稀疏分布 ,即更高斯。对其进行normalization更能产生稳定分布的激活。
更加具有对称性,非稀疏分布 ,即更高斯。对其进行normalization更能产生稳定分布的激活。
因此BN的对象是线性变换的输出。
这时 中偏置可以忽略。
中偏置可以忽略。
偏置b的作用可以被BN的中心化取消,且后面scale部分会有shift。最终的公式如下:
-
添加BN后可以采用更大学习
通过bn整个网络的激活值,在数据通过深度网络传播时,它可以防止层参数的微小变化被放大。(梯度消失)
bn使参数缩放更有弹性。通常,大的学习率可能增加参数的缩放,这在BP时会放大梯度并导致梯度爆炸。通过BN,bp不受其参数缩放的影响。
-
实验1:minist训练
a图是性能和迭代次数。b,c是某一层的激活值分布。添加bn训练收敛更快且性能更优,且分布更加稳定。

-
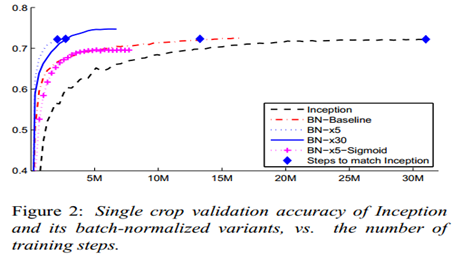
实验2:Imagenet Classfication
训练tricks:1.提高学习率。大学习率依然能收敛。2.去掉dropout。删除后获得更高的验证准确率。推测bn能提供类似dropout的正则化收益。(这里只测试了验证集,感觉不够严密)。3.更彻底的shuffle。防止同一类一起出现在同一个minibatch。验证集提高了1%。4.减小L2正则权重。减小5倍后验证集性能提高。(相当于caffe里deacy)。5.加速学习率衰减。训练时间更短。6.去掉RPN。7.减少photometric distortions(光照扭曲)。
单模型实验:
Inception
BN-Baseline:在Inception 基础上加bn
BN-x5: 在BN-Baseline 基础上增大5倍学习率到0.0075
BN-x30:在BN-Baseline 基础上增大30倍学习率到0.045
BN-x5-Sigmoid:使用sigmoid替代ReLU

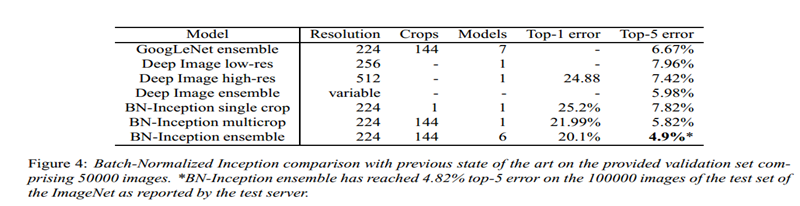
多模型实验结果:
(BN-inception就是我们说的V2)
-
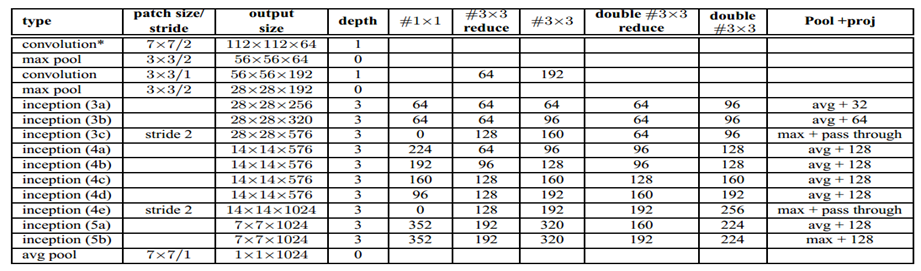
附录BN-inception的结构
V1到BN的改动:1.2个3*3代替5*5。2.28*28 modules从2个增加到3个。3.在modules中,pooling有时average ,有时maximum 。4.
没有across board pooling layers在任意两个inception modules。只在3c,4e里会有stride-2的卷积和pooling。