比较器问题引出
Comparable比较器
所谓的比较器指的就是进行大小关系的确定判断,下面首先来分析一下比较器存在的意义是什么
如果要进行数组操作,肯定使用java.util.Arrays的操作类完成,这个类里面提供有绝大部分的数组操作支持,同时在这个类里面还提供有一种对象数组的排序支持:public static void sort(Object[] a)

同样,如果说现在给定的是一个String型的对象数组,也是可以进行排序处理的

得出String数组也可以进行排序
java.lang.Integer与java.lang.String两个类都是由系统提供的程序类,那么如果说现在有一个自定义的类要实现排序处理呢?
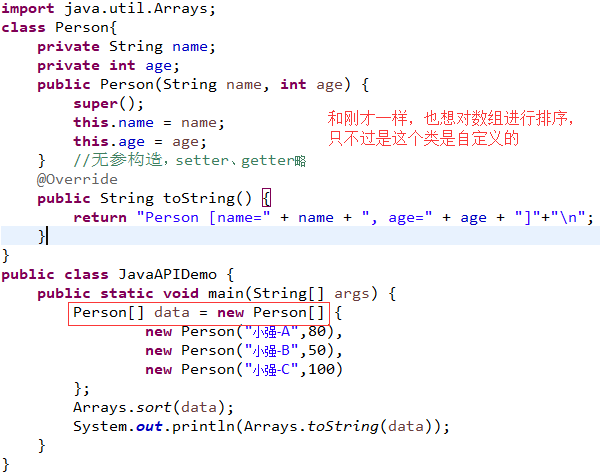

任意一个类默认情况下是无法使用系统内部的类实现数组排序或比较需求的,看下图,我们只需实现Comparable,并且复写Comparable方法即可
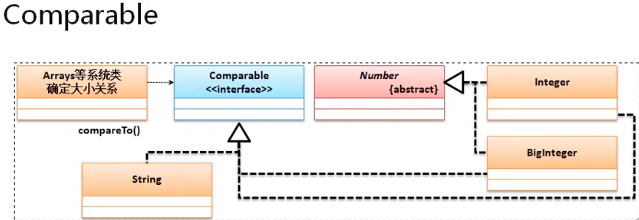

排序里面只需要有一个compareTo()方法进行排序规则的定义,而后整个java系统里面就可以为其实现排序处理了。Arrays.binarySearch(a,key),二分法查找,其实看源码
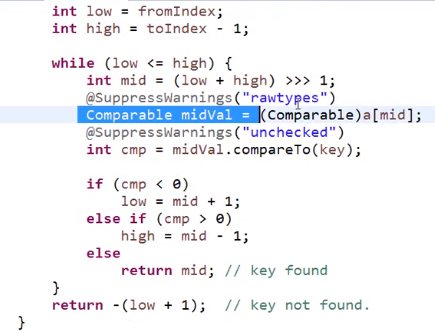
整个过程中用的是Comparable,也用CompareTo进行比较,千万记住以后遇到对象数组的排序需求,一定要使用Comparable比较器处理。
Comparator比较器
Comparator属于一种挽救的比较器支持,其主要的目的是解决一些没有使用Comparable排序的 类的对象数组排序操作。现在程序项目已经开发完成了,并且由于先期的设计并没有去考虑到所谓的比较器功能。(比如上面的类Person在定义的时候根本就没想实现Comparable接口,根本没想排序)。后来经过若干版本的迭代更新后发现需要对Person类进行排序处理,但是又不能去修改Person类(无法实现Comparable接口了),所以这个时候就需要采用一种挽救的形式来进行比较,在Arrays类里面排序有另外一种实现
基于Comparator的排序处理:public static<T> void sort ( T[] a , Comparator<? super T> c)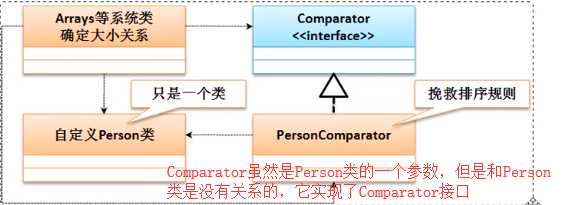
在java.util.Comparator里面最初只定义有一个排序的compare()方法(public int compare(T o1,T o2)),但是后来持续发展又出现了许多static方法。
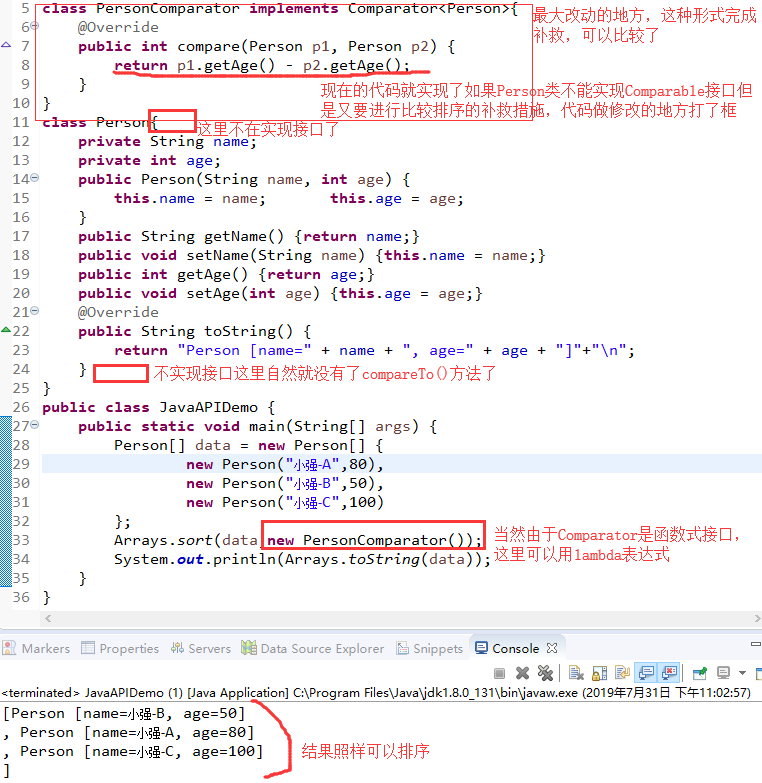
对于这种排序的操作如果不是必须的情况强烈不建议使用Comparator,最好以Comparable为主。
面试题:请解释Comparable与Comparator的区别?
java.lang.Comparable是在类定义的时候实现的父接口,主要用于定义排序规则,里面只有一个compareTo()方法。
java.util.Comparator是挽救的比较器操作,需要设置单独的比较器规则类实现排序,里面有compare()方法。
二叉树结构简介
在进行链表结构开发的过程中会发现所有的数据按照首尾相连的状态进行保存,那么当要进行某一个数据查询的时候(判断该数据是否存在),这种情况下它所面对的时间复杂度是“O(n)”(有多少数据就要查多少遍),如果说现在它的数据量小(不超过30个)的情况下,那么性能上是不会有太大差别的,而一旦保存的数据量很大,这个时候时间复杂度就会严重损耗程序的运行性能,那么现在对于数据的存储结构就必须发生改变,应该可以尽可能的减少检索次数为出发点进行设计,对于现在的数据结构而言,最好的性能就是“O(logn)”,所以现在要想实现它就可以利用二叉树的结构来完成。
如果要想实现一棵树结构的定义,那么就需要考虑数据的存储形式,在二叉树的实现之中其基本的实现原理如下;取第一个数据为保存的根节点,小于等于根节点的数据要放在节点的左子树,而大于节点的数据要放在该节点的右子树。
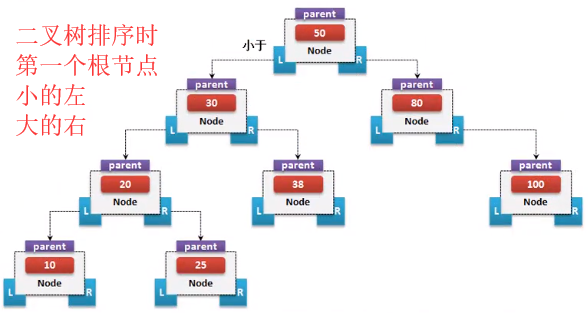
如果要进行数据检索的话,此时就需要进行每一个节点的判断,但是它的判断是区分左右的,所以不会是整个的结构都进行判断处理,那么它的时间复杂度就是O(logn)。
而对于二叉树而言,在进行数据获取的时候也有三种形式:
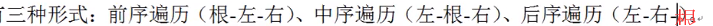
,现在只是以 中序遍历 为主,则以上的数据进行中序遍历的时候最终的结果:10、20、25、30、38、50、80、100,可以发现二叉树中的内容都是排序的结果。
二叉树基础实现
在二叉树的处理之中最为关键性的问题在于数据的保存,而且数据由于牵扯到对象比较的问题,那么一定要有比较器的支持,而这个比较器首选的一定就是Comparable,所以本次将保存一个Person类数据:
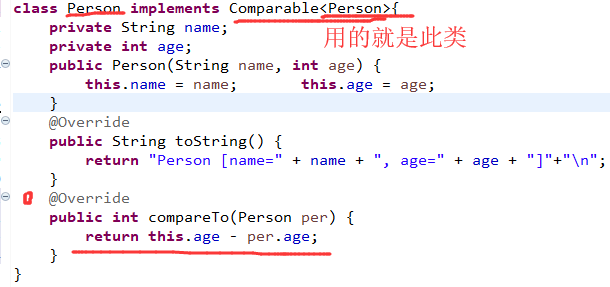
随后如果要想进行数据的保存,首选一定需要有一个节点类,节点类里面由于牵扯到数据的保存问题,所以必须使用Comparable(可以区分大小)
下面内容为手写二叉树基础功能(盗版二叉树),相当有难度
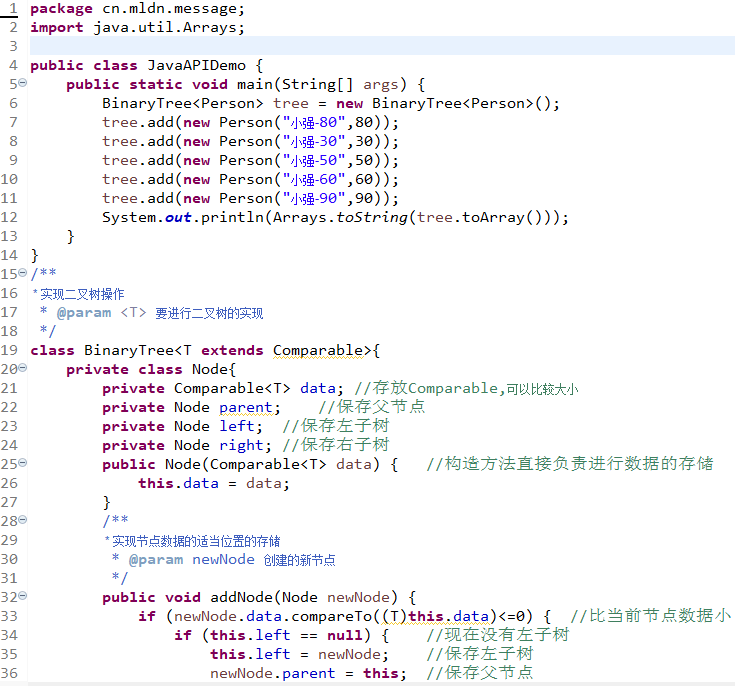
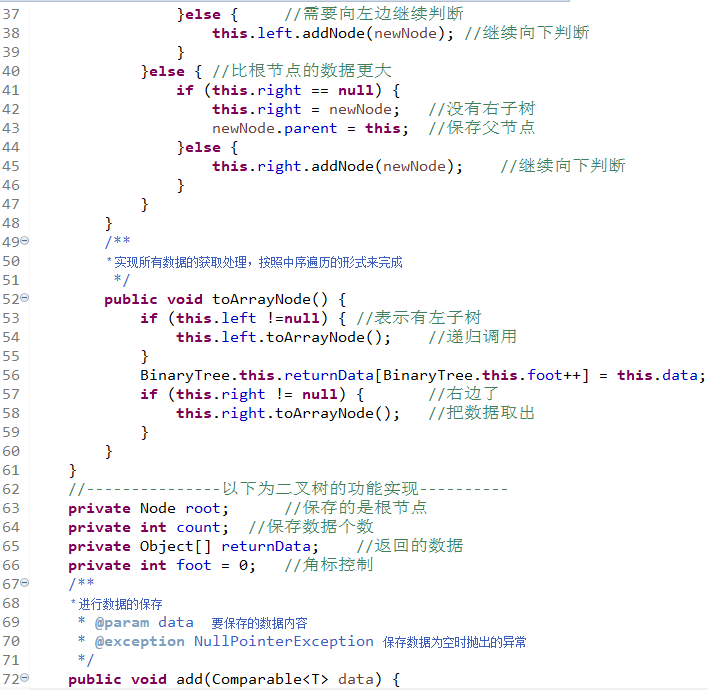

在进行数据添加的时候只是实现了节点关系的保存,而这种关系保存后的结果就是所有的数据都属于有序排列。
二叉树数据删除
二叉树之中的数据删除操作是非常复杂的,因为在进行数据删除的时候需要考虑的情况是比较多的
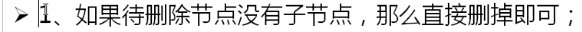
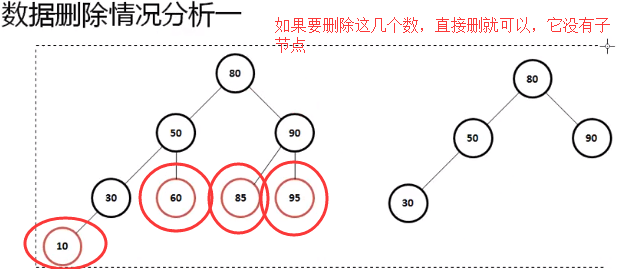


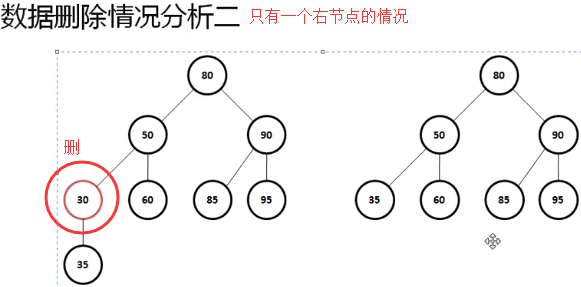

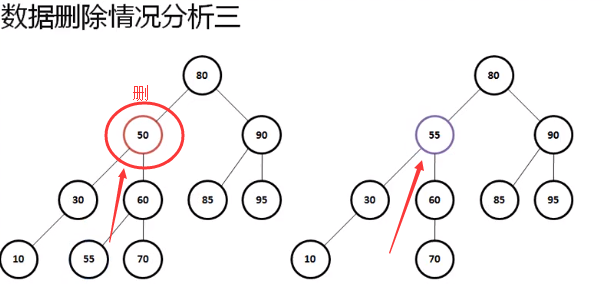
下面通过具体的代码实现操作功能

这种数据结构的删除操作是非常繁琐的,所以如果不是必须的情况下不建议使用删除,增加、删除、查询是数据结构里面必须会的三种形式。
上面代码不全
这节代码不学了,太麻烦
红黑树原理简介
通过整个的二叉树的实现相信已经可以清楚二叉树的主要特点:数据查询的时候可以提供更好的查询性能,但是这种原始的二叉树结构是有明显缺陷的,例如:当二叉树结构改变的时候(增加或删除)就有可能出现不平衡的问题。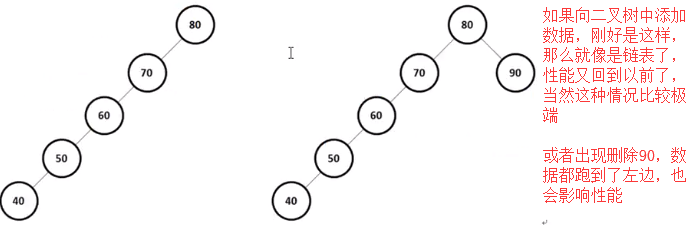
之前所谓的解决二叉树性能的方式最终全部都变成了null,也就是说如果要想达到最良好效果的二叉树,那么它首先应该是一个平衡二叉树,同时所有的节点层次深度应该平衡
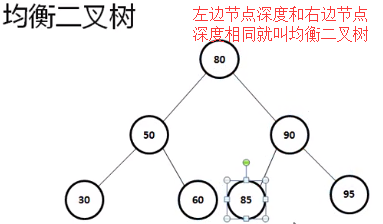
如果所有的数据按照以上的结构进行保存,那么二叉树的检索执行效率一定是最高的,可是你的树需要忍受着这些频繁的增加和删除操作。所以针对于二叉树有了进一步的设计要求:

在java中的类集框架里面大量的采用了红黑树的结构,这也是为什么红黑树成为了面试常问的原因,这种改变从jdk1.8开始。
红黑树的本质就是在节点上追加了一个表示颜色的操作信息而已。
。。。。。。。。。。。。。。此处省略一万字,(红黑树看了心里排斥障碍)