字符编码
在计算机的世界里面只认0、1的数据,如果要想描述一些文字的编码就需要对这些二进制的数据进行组合,所以才有了现在可以看到的中文,但是在进行编码的时候如果要想正确的显示一些内容则一定需要有解码,所以编码和解码肯定要采用统一的标准,如果不统一的时候就会出现乱码。不想乱码就是要编码和解码规则一样。
那么在实际的开发中对于常见的编码有如下几种
GBK/GB2312:国标编码,可以描述中文信息,其中GB2312只描述简体中文,而GBK包含简体中文和繁体中文;
ISO8859-1:国际通用编码,可以用其描述所有的字母信息,如果是象形文字则需要进行编码处理;
UNICODE编码:采用十六进制,可以描述所有的文字信息,不会乱码,但是太大了;
UTF编码:象形文字部分使用十六进制编码,而普通的字母采用的是ISO8859-1的通用编码,好处适用于快速的传输,节约带宽,也就成为了开发中首选的编码;
如果要想支持当前系统中支持的编码规则,则可以采用如下代码列出全部的本机属性

也就是说现在什么都不设置的话,则采用的编码就是UTF-8
此时为默认的处理操作,不设置编码就采用默认的编码进行
项目中出现乱码问题就是编码和解码标准不统一,而最好的解决乱码的方式就是所有的编码都采用UTF-8
内存操作流
在之前使用的全部都是文件操作流,文件操作流的特点,程序利用InputStream读取文件内容,而后程序利用OutputStream向文件输出内容,所有的操作都是以文件为终端的。
假如说现在需要实现IO操作,可是又不希望产生文件(临时文件)则就可以以内存为终端进行处理,这个时候的流使用如下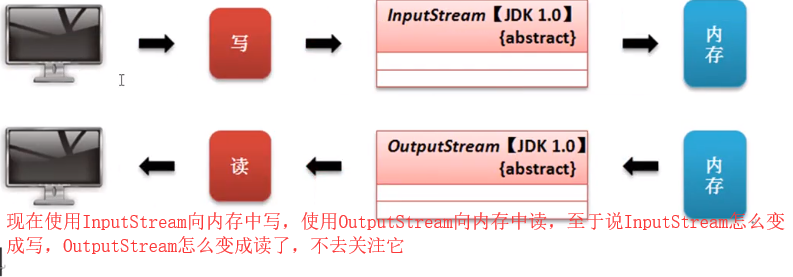
在Java里面提供有两类的内存操作流
字节内存操作流:ByteArrayOutputStream、ByteArrayInputStream;
字符内存操作流:CharArrayWriter、CharArrayReader;下图这四个流的关系图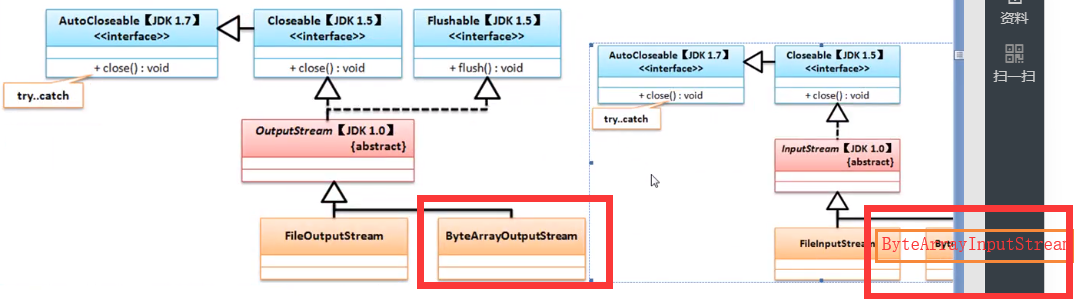
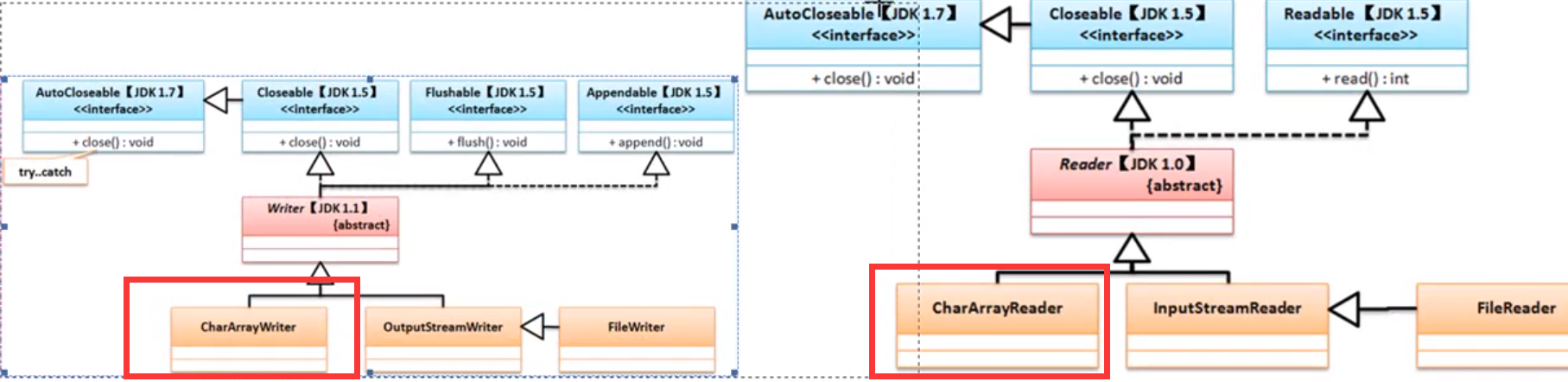
下面以ByteArrayOutputStream和ByteArrayInputStream类为主进行内存的使用分析,首先来分析各自的构造方法
在ByteArrayOutputStream类里面有一个重要的方法,这个方法可以获取全部保存的内存流中的信息,该方法为:

如果现在不希望只是以字符串的形式返回,因为可能存放的是其它二进制的数据,那么此时就可以利用ByteArrayOutputStream子类的扩展功能获取全部字节数据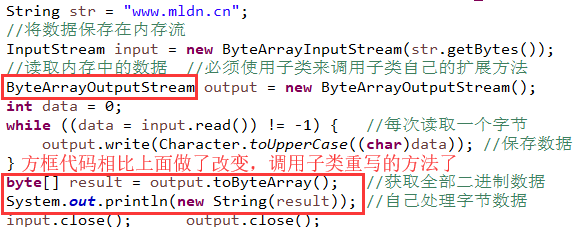
在最初的时候可以利用ByteArrayOutputStream实现大规模文本文件的获取。现在使用较少。
管道流
管道流主要功能是实现两个线程之间的IO处理操作。
对于管道留也是分为两类:

package cn.mldn.demo; import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.PipedInputStream; import java.io.PipedOutputStream; class SendThread implements Runnable{ //发送 private PipedOutputStream output; public SendThread() { this.output = new PipedOutputStream(); } @Override public void run() { try { //利用管道实现数据的发送处理 this.output.write("www.mldn.cn".getBytes()); this.output.close(); } catch (IOException e) { e.printStackTrace(); } } public PipedOutputStream getOutput() { return output; } } class ReceiveThread implements Runnable{ //接收 private PipedInputStream input; public ReceiveThread() { this.input = new PipedInputStream(); } @Override public void run() { byte[] data = new byte[1024]; int len = 0; ByteArrayOutputStream bos = new ByteArrayOutputStream(); try { //现在有了循环就是为了可以发送多次,所以定义了一个len while ((len = this.input.read(data)) != -1) { bos.write(data,0,len); //所有数据保存在内存流里面 } System.out.println(new String(bos.toByteArray())); bos.close(); } catch (IOException e) { e.printStackTrace(); } try { this.input.close(); }catch(Exception e){ e.printStackTrace(); } } public PipedInputStream getInput() { return input; } } public class JavaAPIDemo { public static void main(String[] args) throws Exception { SendThread send = new SendThread(); ReceiveThread receive = new ReceiveThread(); send.getOutput().connect(receive.getInput()); new Thread(send,"消息发送线程").start(); new Thread(receive,"消息接收线程").start(); } }
管道就类似于医院打点滴的效果,一个只是负责发送,一个负责就是,中间靠管道连接
RandomAccessFile(随机读取文件类)
对于文件的内容处理操作主要是通过InputStream(Reader)、OutputStream(Writer)来实现,但是利用这些类实现的内容读取只能够将数据部分部分读取进来,如果说现在有这样一种要求。
现在给了你一个非常庞大的文件,这个文件的大小有20G(很正常,不要觉得荒唐,当然这也属于设计的问题,正常一个文件是3~4个G,后面日志采集会干这事),如果此时按照传统的IO操作进行读取和分析,根本不可能完成,所以这种情况下就有一个RandomAccessFile类,这个类可以实现文件的跳跃式的读取,可以只读取中间的部分内容(前提:需要有一个完善的保存形式),数据的保存位数都要确定好。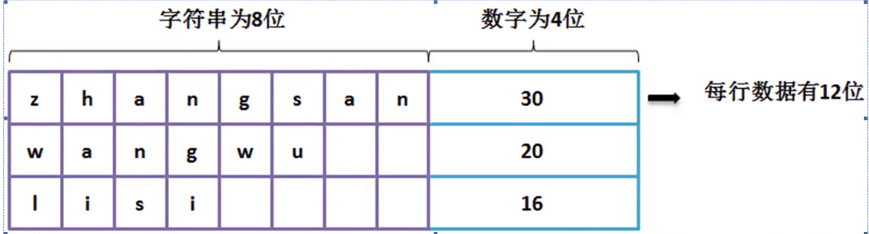

public class JavaAPIDemo { public static void main(String[] args) throws Exception { File file = new File("d:"+File.separator+"mldn.txt");//定义操作文件 RandomAccessFile raf = new RandomAccessFile(file,"rw");//读写模式 String[] names = new String[] {"zhangsan","wangwu ","lisi "}; int[] ages = new int[] {30,20,16}; for (int x = 0; x < names.length; x++) { raf.write(names[x].getBytes()); //写入字符串 raf.writeInt(ages[x]); } raf.close(); } }
RandomAccessFile的特点是在于数据的读取处理上,因为所有的数据是按照固定的长度进行的保存,所以读取的时候就可以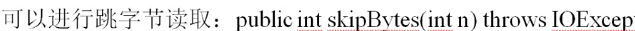
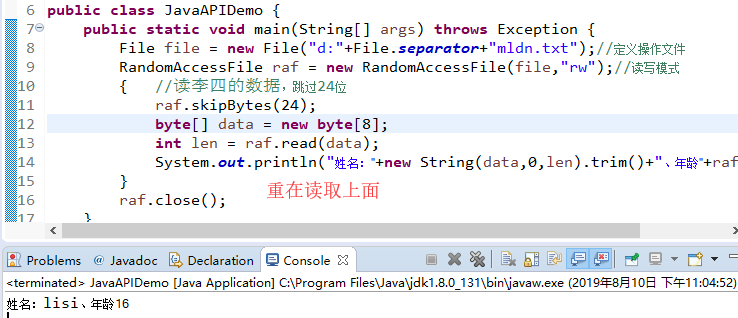
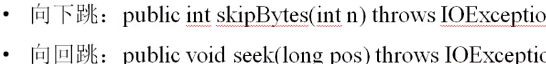
public class JavaAPIDemo { public static void main(String[] args) throws Exception { File file = new File("d:"+File.separator+"mldn.txt");//定义操作文件 RandomAccessFile raf = new RandomAccessFile(file,"rw");//读写模式 { //读取lisi raf.skipBytes(24); byte[] data = new byte[8]; int len = raf.read(data); System.out.println("姓名:"+new String(data,0,len).trim()+"、年龄"+raf.readInt()); } { //读wangwu的数据,回跳12位 raf.seek(12); byte[] data = new byte[8]; int len = raf.read(data); System.out.println("姓名:"+new String(data,0,len).trim()+"、年龄"+raf.readInt()); } { //读zhangsan的数据,回到顶点 raf.seek(0); byte[] data = new byte[8]; int len = raf.read(data); System.out.println("姓名:"+new String(data,0,len).trim()+"、年龄"+raf.readInt()); } raf.close(); } }
整体的使用之中由用户自行定义要读取的位置,而后按照指定的结构进行数据的读取。
要求数据的长度一定要保持一致。