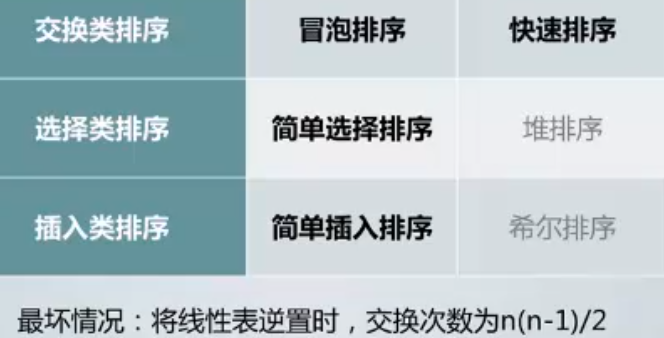
一般来说排序算法实现起来要比查找算法实现起来要复杂很多,所以这节课不一一介绍每一种算法实现的原理了,我们主要侧重比较不同排序算法之间的算法复杂度,所以这节课介绍6中不同的算法,我们把这些算法分为3类,听名字就知道分类是根据排序的原理分类的。

实际上还有一种分类方式,根据算法的稳定性来分类,什么是稳定性呢?举例来说现在有一个线性表,我们要按照从小到大进行排序,假设这个线性表里面有两个数字一个是3一个是15,在排序之前3在左边15在右边,虽然这两个数字最终都不在它们应该在的位置上,但是它们两个相对位置是准确的,如果说排序前两个数的位置与排序后两个数的位置相对是不变的我们称之为稳定的排序,否则是不稳定的排序,


在刚才给的排序中有4中都是不稳定的排序,所以这样就造成了一个主观的印象,好像不稳定的排序多一些,但是事实上由于考试的需要这节课只列出了6中典型的排序算法,如果真的去学习数据结构与算法这种专业课的话,你会发现大多数常见的算法还是稳定算法的,所以把所有主流的能叫得出名字的排序算法都拿出来的话实际上只有快速、选择、希尔、堆排序这四种算法是不稳定的,简称快选希堆。所以在稳定性这个问题上只需要记住快选希堆这4个是不稳定的就可以了。

对他们的性质有了基本了解之后来看看它们的时间复杂度,实际上这6种算法的时间复杂度非常好记

冒泡排序实现的原理,所以冒泡排序在最坏情况下要比较n(n-1)/2这么多次,由于我们前面在讲算法概念的时候说了算法的复杂度是取它最大的,所以n(n-1)/2它的数量级就是n^2,所以说冒泡排序的算法复杂度就是O(n^2),所以冒泡排序搞清楚了只需要再记住简单选择排序和简单插入排序它们的算法复杂度和冒泡排序是一样的也都是O(n^2)就可以了。右边的三个算法刚才说了它的实现原理要复杂一些算法复杂度也要更低一些因为它的效率更高,所以右边三个算法的复杂度都是O(n*n的对数)。所以可以看出来算法实现的方法不一样,它们算法的效率果然是不一样的,这种效率的差距实际上只有对大规模的数据才看的出来,就好比都知道汽车比自行车要快,但是你只在小胡同里面跑一百米的话这种差距也不是特别得明显,只有放在高速公路上跑一个长途差距才会很明显。

对于我们普通的家用的或者办公用的电脑来说,只要是十万个以上个数据,基本上都可以用肉眼来分辨速度的快慢了,所以现在就有了一个问题,假设我们现在就对大规模数据排序,而且都是随机数据,那么在这种最常规的情况下,我们计算机学科发展了这么多年,发展到今天有没有一个定论就是哪一个算法是最快的,这个是如果有定论的话以后我们处理大规模的排序算法就不需要想了直接用这个算法就对了,答案是有的,那就是快速排序。虽然它和下面的堆排序和希尔排序一般情况下都是O(n*n的对数),但是这个仅仅是表示数量级,从统计学的角度来说,绝大多数情况下在处理大规模的数据的时候快速排序还是现在已知排序算法中最快的,不过这么牛逼的算法还是有一个致命的缺点,这个致命的缺点就是如果我们排列的数据是一种极端的情况,比喻说我们有十万个从小到大排列的数字是有序的,但是我们现在要把它变成从大到小排列,也就是说整个线性表完全是反的,那么在这种最极端的情况下,快速排序的比较次数就退回到了和冒泡排序一样的水平,它在最坏的情况下也需要比较n(n-1)/2这么多次才能完成这么多的排序,而堆排序和希尔排序就没有这样的特点,即使在最坏的情况下也不需要比较这么多次,所以说快速排序的威力是建立在大量和随机这两个条件之上的。