之前我们已经完成了一个小demo的测试,将数据库的数据查了出来今天我们会对其他的操作也进行练习。
1.mp实现添加操作
@Test public void insertTest() { User user=new User(); user.setName("dumeng"); user.setAge(21); user.setEmail("810615483@qq.com"); int insert = userMapper.insert(user); System.out.println("insert:"+insert); }
实现结果:
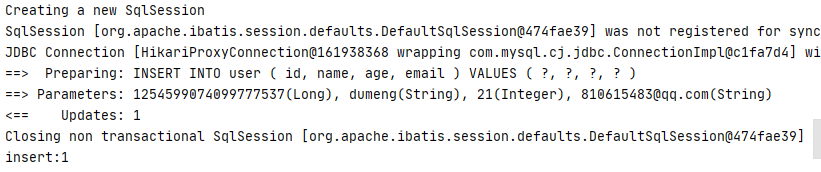
数据库:
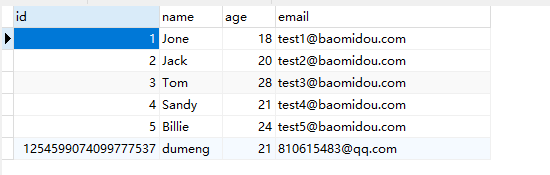
可以看到这个id是mp帮我们生成的,有19位。
在此说一下主键的增长策略:
1. 自动增长:AUTO_INCREMENT
最常见的方式。利用数据库,全数据库唯一。
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
优化方案:
1)针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
2. UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
3.Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
例:
那么如何进行一个自增id操作呢?
在实体类中添加注解
@TableId(type = IdType.AUTO) private Long id;
要想影响所有实体的配置,可以设置全局主键配置
#全局设置主键生成策略
mybatis-plus.global-config.db-config.id-type=auto
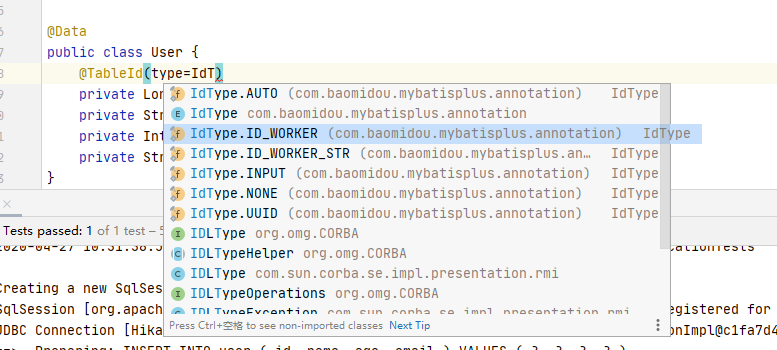
这里说一下这几个策略:
@Getter public enum IdType { /** * 数据库ID自增 */ AUTO(0), /** * 该类型为未设置主键类型 */ NONE(1), /** * 用户输入ID * 该类型可以通过自己注册自动填充插件进行填充 */ INPUT(2), /* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */ /** * 全局唯一ID (idWorker) */ ID_WORKER(3), /** * 全局唯一ID (UUID) */ UUID(4), /** * 字符串全局唯一ID (idWorker 的字符串表示) */ ID_WORKER_STR(5); private int key; IdType(int key) { this.key = key; } }
好了言归正传我们用的mp自带的增长策略,简单说一下:
snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。具体实现的代码可以参看https://github.com/twitter/snowflake。
@TableId(type= IdType.ID_WORKER)//mp自带的策略,生成19位,数字类型用这种策略,如果是字符串类型用ID_WORKER_STR private Long id;
2. mp修改操作
@Test public void updateTest() { User user=new User(); user.setId(2l); user.setAge(40); int i = userMapper.updateById(user); System.out.println("update:"+i); }
运行结果:
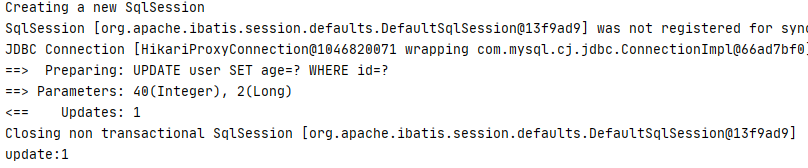
数据库:

自动填充
首先在数据库添加字段create_time ,update_time

正常来讲我们需要加时间应该自己去set设置,我们可以用mp的方式加时间。
实现过程:
1.在需要自动填充的属性上加注解
@TableField(fill= FieldFill.INSERT) private Date createTime; @TableField(fill=FieldFill.INSERT_UPDATE) private Date updateTime;
2.自己创建类实现
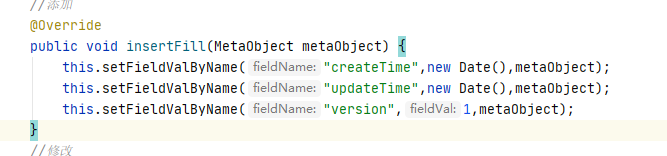
@Component//交给Spring管理 public class MyMetaObjectHandler implements MetaObjectHandler { //添加 @Override public void insertFill(MetaObject metaObject) { this.setFieldValByName("createTime",new Date(),metaObject); this.setFieldValByName("updateTime",new Date(),metaObject); } //修改 @Override public void updateFill(MetaObject metaObject) { this.setFieldValByName("updateTime",new Date(),metaObject); } }
测试代码:
@Test public void insertTest2() { User user=new User(); user.setName("dumeng1"); user.setAge(21); user.setEmail("810615483@qq.com"); int insert = userMapper.insert(user); System.out.println("insert:"+insert); }
此时可以看到我们的数据库就会有时间(记得保存数据库更改)

3.乐观锁
乐观锁实现方式:
- 取出记录时,获取当前version
- 更新时,带上这个version
- 执行更新时, set version = newVersion where version = oldVersion
- 如果version不对,就更新失败
(1)数据库中添加version字段
ALTER TABLE `user` ADD COLUMN `version` INT

(2)实体类添加version字段
@Version
@TableField(fill = FieldFill.INSERT)
private Integer version;
@Configuration @MapperScan("com.example.demo.mapper.UserMapper") public class mpconfig { /** * 乐观锁插件 */ @Bean public OptimisticLockerInterceptor optimisticLockerInterceptor() { return new OptimisticLockerInterceptor(); } }
修改自动填充
测试:先查后改
@Test public void testOptimisticLocker() { //查询 User user = userMapper.selectById(1L); //修改数据 user.setName("DM"); user.setEmail("DM@qq.com"); //执行更新 userMapper.updateById(user); }
运行前:

运行后:

4. 查询
通过多个id批量查询@Test public void testSelectBatchIds(){ List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3)); users.forEach(System.out::println); }

@Test public void testSelectByMap(){ HashMap<String, Object> map = new HashMap<>(); map.put("name", "Helen"); map.put("age", 18); List<User> users = userMapper.selectByMap(map); users.forEach(System.out::println); }
5. 分页
1.配置插件
/** * 分页插件 */ @Bean public PaginationInterceptor paginationInterceptor() { return new PaginationInterceptor(); }
2.编写代码
@Test public void testPage(){ //1.创建page对象 //两个参数,当前页和每页显示的记录数 Page<User> page=new Page<>(1,3); userMapper.selectPage(page, null); System.out.println(page.getCurrent());//当前页 System.out.println(page.getRecords());//每页数据list集合 System.out.println(page.getSize());//每页显示记录数 System.out.println(page.getTotal());//总记录数 System.out.println(page.getPages());//总也是有 System.out.println(page.hasNext());//有没有下一页 System.out.println(page.hasPrevious());//有没有上一页 }

6.物理删除
1.物理删除
@Test public void testdelete(){ int i = userMapper.deleteById(1); System.out.println("delete"+i); }
2. 批量删除
@Test public void testDeleteBatchIds() { int result = userMapper.deleteBatchIds(Arrays.asList(8, 9, 10)); System.out.println(result); }
3.条件删除
@Test public void testDeleteByMap() { HashMap<String, Object> map = new HashMap<>(); map.put("name", "Helen"); map.put("age", 18); int result = userMapper.deleteByMap(map); System.out.println(result); }
7. 逻辑删除
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据
- 逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
(1)数据库中添加 deleted字段
ALTER TABLE `user` ADD COLUMN `deleted` boolean
@TableLogic @TableField(fill = FieldFill.INSERT) private Integer deleted;
(3)在 MybatisPlusConfig 中注册 Bean
/** * 逻辑删除插件 */ @Bean public ISqlInjector sqlInjector() { return new LogicSqlInjector(); }
(4)元对象处理器接口添加deleted的insert默认值
this.setFieldValByName("deleted", 0, metaObject);
测试:
/** * 测试 逻辑删除 */ @Test public void testLogicDelete() { int result = userMapper.deleteById(2L); System.out.println(result); }

用之前的查询语句测试是否查询deleted为0是否可以查询出来
此时就没有id为2的了。
