在介绍 Spark SQL之前,我们先了解两种基本的数据分析方式。
一、数据分析的两种方式
数据分析的方式大致上可以划分为 SQL 和 命令式两种。
命令式
在前面的 RDD部分,非常明显可以感觉的到是命令式的,主要特征是通过一个算子,可以得到一个结果,通过结果再进行后续计算。例如:
sc.parallelize(...)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey( _ + _ )
.reduceByKey( _ + _ )
.collect()
针对于过程进行表达。
命令式的优点
- 操作粒度更细,能够控制数据的每一个处理环节
- 操作更明确,步骤更清晰,容易维护
- 支持非结构化数据的操作
命令式的缺点
需要一定的代码功底,写起来比较麻烦。
SQL式
比起命令式表达起来更清晰,更适用于做一些小规模的查询。例如:
SELECT name, age, school FROM students WHERE age > 20
SQL的优点
表达非常清晰,比如说这段SQL明显就是为了查询三个字段,又比如说这段SQL明显能看到是想查询年龄大于10岁的条目
SQL的缺点
- 想象—下3层嵌套的SQL,维护起来应该挺力不从心的吧.
- 试想一下,如果使用SQL来实现机器学习算法,也挺为难的吧
SQL擅长数据分析和通过简单的语法表示查询,命令式操作适合过程式处理和算法性的处理.在Spark出现之前,对于结构化数据的查询和处理,一个工具一向只能支持SQL或者命令式,使用者被迫要使用多个工具来适应两种场景,并且多个工具配合起来比较费劲.
而Spark出现了以后,统一了两种数据处理范式,是一种革新性的进步.
二、SparkSQL简介
1、Spark SQL
解决的问题
-
Spark SQL使用Hive解析SQL生成AST语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖Hive -
执行计划和优化交给优化器
Catalyst -
内建了一套简单的
SQL解析器, 可以不使用HQL, 此外, 还引入和DataFrame这样的DSL API, 完全可以不依赖任何Hive的组件 -
Shark只能查询文件,Spark SQL可以直接降查询作用于RDD, 这一点是一个大进步
新的问题
对于初期版本的 SparkSQL, 依然有挺多问题, 例如只能支持 SQL 的使用, 不能很好的兼容命令式, 入口不够统一等
2、Dataset
SparkSQL 在 2.0 时代, 增加了一个新的 API, 叫做 Dataset, Dataset 统一和结合了 SQL 的访问和命令式 API 的使用, 这是一个划时代的进步
在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据, 然后使用命令式 API 进行探索式分析
总结: SparkSQL 是什么
SparkSQL 是一个为了支持 SQL 而设计的工具, 但同时也支持命令式的 API
3、SparkSQL适用场景
| 定义 | 特点 | 举例 | |
|---|---|---|---|
|
结构化数据 |
有固定的 |
有预定义的 |
关系型数据库的表 |
|
半结构化数据 |
没有固定的 |
没有固定的 |
指一些有结构的文件格式, 例如 |
|
非结构化数据 |
没有固定 |
没有固定 |
指文档图片之类的格式 |
结构化数据
-
一般指数据有固定的
Schema, 例如在用户表中,name字段是String型, 那么每一条数据的name字段值都可以当作String来使用
半结构化数据
一般指的是数据没有固定的 Schema, 但是数据本身是有结构的
-
指的是半结构化数据是没有固定的
Schema的, 可以理解为没有显式指定Schema
比如说一个用户信息的JSON文件, 第一条数据的phone_num有可能是String, 第二条数据虽说应该也是String, 但是如果硬要指定为BigInt, 也是有可能的
因为没有指定Schema, 没有显式的强制的约束
SparkSQL处理什么数据的问题?-
-
Spark的RDD主要用于处理 非结构化数据 和 半结构化数据 -
SparkSQL主要用于处理 结构化数据
-
SparkSQL相较于RDD的优势在哪?-
-
SparkSQL提供了更好的外部数据源读写支持-
因为大部分外部数据源是有结构化的, 需要在
RDD之外有一个新的解决方案, 来整合这些结构化数据源
-
-
SparkSQL提供了直接访问列的能力-
因为
SparkSQL主要用做于处理结构化数据, 所以其提供的API具有一些普通数据库的能力
-
-
总结:SparkSQL 适用于处理结构化数据的场景
三、Spark SQL初体验
主要对两种,命令式 和 声明式 的API。
1、命令式API案例入门
package com.thorine import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} import org.junit.Test class Intro { /** * Spark SQL 初体验 */ @Test def sqlIntro(): Unit ={ // Builder 构建者模式,通过 SparkSession。 val spark = new SparkSession.Builder() .appName("sql_Intro") .master("local[6]") .getOrCreate() // 下面的 toDS() 方法需要用到 import spark.implicits._ val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 14), Person("lisi", 16), Person("wangwu", 25))) val personDS = sourceRDD.toDS() // 筛选出年龄在10岁到20岁之间的用户 val resultDS = personDS.where( 'age > 10) .where( 'age < 20) // 选择打印 name 列 .select('name) .as[String] // 打印内容 resultDS.show() } } // 如果case class放内部:Unable to generate an encoder for inner class `com.thorine.Intro$Person` case class Person(name:String, age: Int)
下面对 SparkSession 给出解释。
2、SparkSession
SparkContext 作为RDD的创建者和入口,其主要作用有如下两点
- 创建RDD,主要是通过读取文件创建 RDD
- 监控和调度任务,包含了一系列组件,例如DAGScheduler, TaskSheduler为什么无法使用SparkContext作为SparkSQL的入口?
SparkContext在读取文件的时候,是不包含Schema信息的,因为读取出来的是RDD。
SparkContext 在整合数据源如Cassandra, JSON, Parquet等的时候是不灵活的,而 DataFrame和Dataset一开始的设计目标就是要支持更多的数据源
. SparkContext 的调度方式是直接调度RDD,但是一般情况下针对结构化数据的访问,会先通过优化器优化一下
所以SparkContext确实已经不适合作为SparkSQL的入口,所以刚开始的时候Spark团队为SparkSQL设计了两个入口点,一个是sQLContext对应Spark标准的SQL执行,另外一个是HiveContext对应HiveSQL 的执行和Hive 的支持.
在Spark 2.0 的时候,为了解决入口点不统一的问题,创建了一个新的入口点 SparkSession,作为整个Spark生态工具的统一入口点,包括了SQLContext, HiveContext, SparkContext等组件的功能
新的入口应该有什么特性?
- 能够整合SQLContext , HiveContext ,SparkContext , StreamingContext 等不同的入口点·为了支持更多的数据源,应该完善读取和写入体系
- 同时对于原来的入口点也不能放弃,要向下兼容
3、DataFrame & Dataset
SparkSQL 中有一个新的入口点, 叫做 SparkSession。SparkSQL 中有一个新的类型叫做 Dataset。SparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的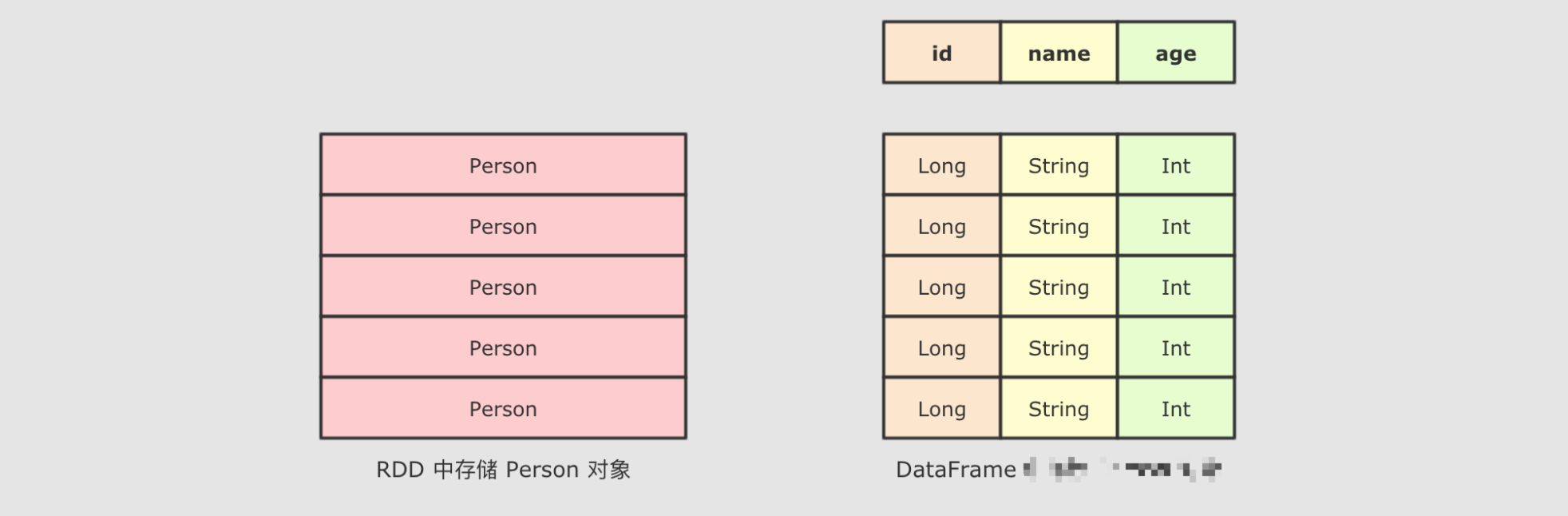
SparkSQL最大的特点就是它针对于结构化数据设计,所以SparkSQL 应该是能支持针对某一个字段的访问的,而这种访问方式有一个前提,就是SparkSQL 的数据集中,要包含结构化信息,也就是俗称的 Schema
而SparkSQL对外提供的API有两类,一类是直接执行SQL,另外一类就是命令式. SparkSQL提供的命令式API就是DataFrame和Dataset,暂时也可以认为DataFrame就是Dataset,只是在不同的API中返回的是 Dataset的不同表现形式
// RDD rdd.map { case Person(id, name, age) => (age, 1) } .reduceByKey {case ((age, count), (totalAge, totalCount)) => (age, count + totalCount)} // DataFrame df.groupBy("age").count("age")
通过上面的代码,可以清晰的看到, SparkSQL的命令式操作相比于RDD来说,可以直接通过Schema信息来访问其中某个字段,非常的方便。
4、声明式API
@Test def dfIntro(): Unit ={ val spark = new SparkSession.Builder() .appName("sql_Intro") .master("local[6]") .getOrCreate() import spark.implicits._ val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 14), Person("lisi", 16), Person("wangwu", 25))) val df = sourceRDD.toDS() // 创建一个临时表 df.createOrReplaceTempView("person") // 返回一个 DataFrame 对象 val resultDF = spark.sql("select * from person where age > 10 and age < 20") resultDF.show() }
以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表
SparkSQL 提供了 SQL 和 命令式 API 两种不同的访问结构化数据的形式, 并且它们之间可以无缝的衔接
命令式 API 由一个叫做 Dataset 的组件提供, 其还有一个变形, 叫做 DataFrame
四、Dataset
SparkSQL有两种API,Dataset 和 DataFrame,本篇先介绍前者,Dataset。
1、Dataset 是什么
package com.thorine import org.apache.spark.sql.SparkSession import org.junit.Test class Dataset { @Test def dataset1(): Unit ={ // 1、创建 SparkSession val spark = new SparkSession.Builder() .master("local[6]") .appName("dataset1") .getOrCreate() // 通过 Builder 的 getOrCreate() 方法得到 Builder 对象 // 2、导入隐式转换 import spark.implicits._ // 3、演示 val dataset = spark.createDataset(Seq(Person("zhangsan", 14), Person("lisi", 16), Person("wangwu", 25))) /* val sourceRDD = spark.sparkContext. parallelize(Seq(Person("zhangsan", 14), Person("lisi", 16), Person("wangwu", 25))) val dataset = sourceRDD.toDS() 两种方式效果一样 */ // Dataset 支持强类型的API (像之前的 RDD操作) dataset.filter( item => item.age > 10).show() // Dataset 支持弱类型 API // 第一种弱类型 API dataset.filter( 'age > 10 ).show() // 第二种弱类型 API dataset.filter($"age" > 10).show() // Dataset支持sql表达式 dataset.filter("age > 10").show() } } // case class Person(name:String,age:Int)
Dataset 是一个强类型, 并且类型安全的数据容器, 并且提供了结构化查询 API 和类似 RDD 一样的命令式 API
可以获取 Dataset 对应的 RDD 表示:
- 使用
Dataset.rdd将Dataset转为RDD的形式 Dataset的执行计划底层的RDD
Dataset是一个强类型,并且类型安全的数据容器,并且提供了结构化查询API和类似RDD一样的命令式API
并且,即使使用 Dataset 的命令式 API,执行计划也依然被优化,可以使用 代码 dataset.explain(true),查看逻辑执行图和 物理执行图,可以看到在执行sql语句前就已经被优化。
2、Dataset 的底层是什么
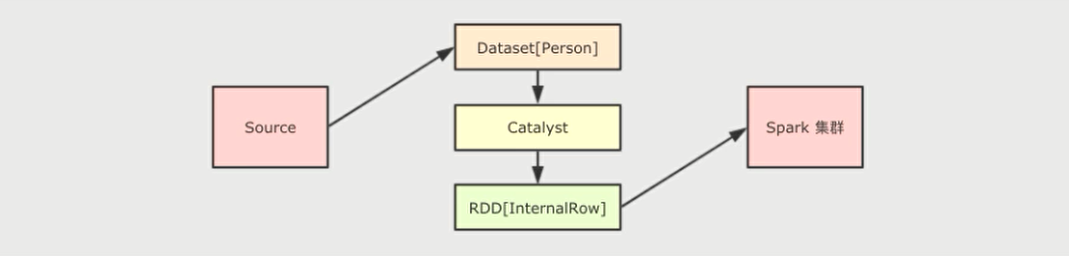
Dataset最底层处理的是对象的序列化形式,通过查看Dataset 生成的物理执行计划,也就是最终所处理的 RDO ,就可以判定Dataset底层处理的是什么形式的数据
val dataset = spark.createDataset(Seq(Person("zhangsan", 14), Person("lisi", 16), Person("wangwu", 25)))
// 查看逻辑执行计划和 物理执行计划
dataset.explain(true)
// 无论 dataset 中放置的是什么类型对象,最终执行计划的RDD都是 InternalRow 类型
val executionRdd: RDD[InternalRow] = dataset.queryExecution.toRdd
dataset.queryExecution.toRdd这个 API可以看到 Dataset 底层执行的 RDD ,这个 RDD中的范型是InternalRow ,InternalRow又称之为Catalyst Row ,是Dataset底层的数据结构,也就是说,无论 Dataset 的范型是什么,无论是Dataset[Person]还是其它的,其最底层进行处理的数据结构都是InternalRow
所以, Dataset 的范型对象在执行之前,需要通过Encoder转换为 InternalRow ,在输入之前,需要把InternalRow通过Decoder转换为范型对象
以上初步介绍了 Spark SQL 的一些基本执行,和 Dataset的初步认识,下篇总结 DataFrame这一重要数据结构的知识。