一、维度变换
多维张量在物理上以一维的方式连续存储,通过定义维度和形状,在逻辑上把它理解为多维张量。
当对多维张量进行维度变换时,只是改变了逻辑上索引的方式,没有改变内存中的存储方式。
1、改变张量形状
使用函数:tf.reshape(tensor, shape)
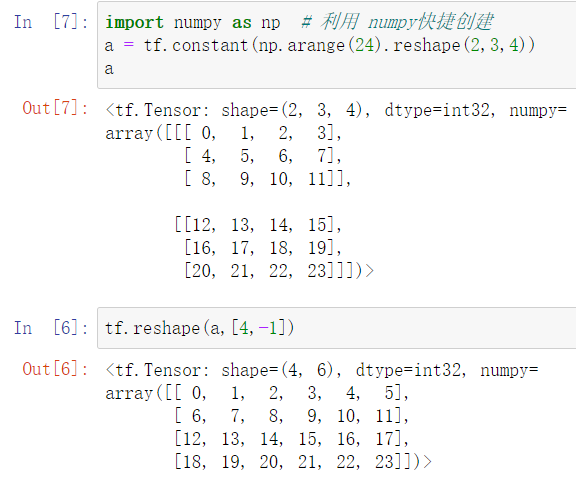
shape参数=-1:表示自动推导出长度
2、增加和删除维度
多维张量的轴,就是张量的维度,张量中轴的概念和用法,和 numpy 中一样。
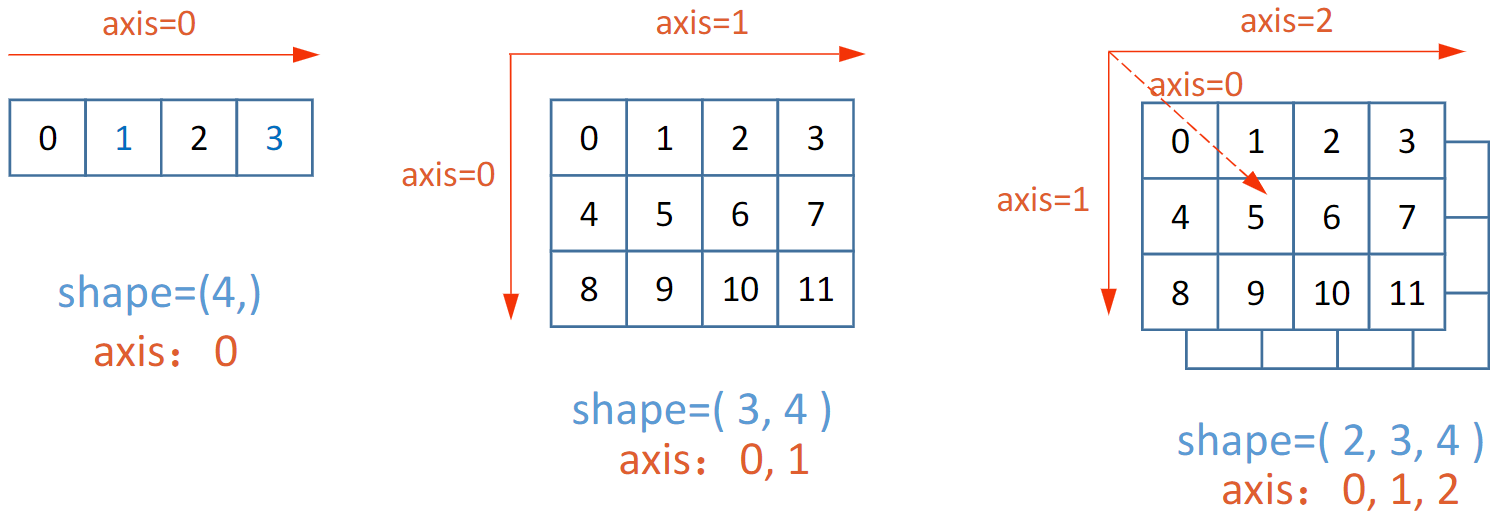
轴也可以是负数,表示从后向前索引。
(1)增加维度
使用函数:tf.expand_dims(tensor, axis):增加指定轴axis的维度,长度为 1。axis 的取值可为正,可为负。

(2)删除维度
tf.squeeze(tensor, asix=None) :tensor 原始张量,axis 要删除的维度(只能删除长度为1的维度,省略时删除所有长度为1的维度)

增加和删除维度,只是改变了张量的视图,不会改变张量的存储。
3、交换维度
tf.transpose(tensor, perm) : perm 调整张量中各个轴的顺序,例如perm=[1,0,2],即表示将tensor张量按照axis为1,0,2的顺序调整。
对于二维张量,不指明perm就是求其转置。

4、拼接张量
将多个张量在某个维度上合并
拼接不会产生新的维度
tf.concat(tensor, axis):tensor 所有需要拼接的张量列表,axis 指定在那个轴上进行拼接。

5、分割张量
将一个张量拆分成多个张量,分割后维度不变。
tf.split(tensor, num_or_size_splits, axis=0)
- tensor:待分割张量
- num_or_size_splits:分割方案
-
是一个数值时,表示等长分割,数值是切割的份数;
-
是一个列表时,表示不等长切割,列表中是切割后每份的长度
-
- axis:指明分割的轴
分割后的多个tensor张量以列表形式返回。
6、堆叠张量
在合并张量时,创建一个新的维度,和numpy中的堆叠完全一样。
tf.stack(tensors, axis) :tensors 要堆叠的多个张量 ,axis 指定插入新维度的位置

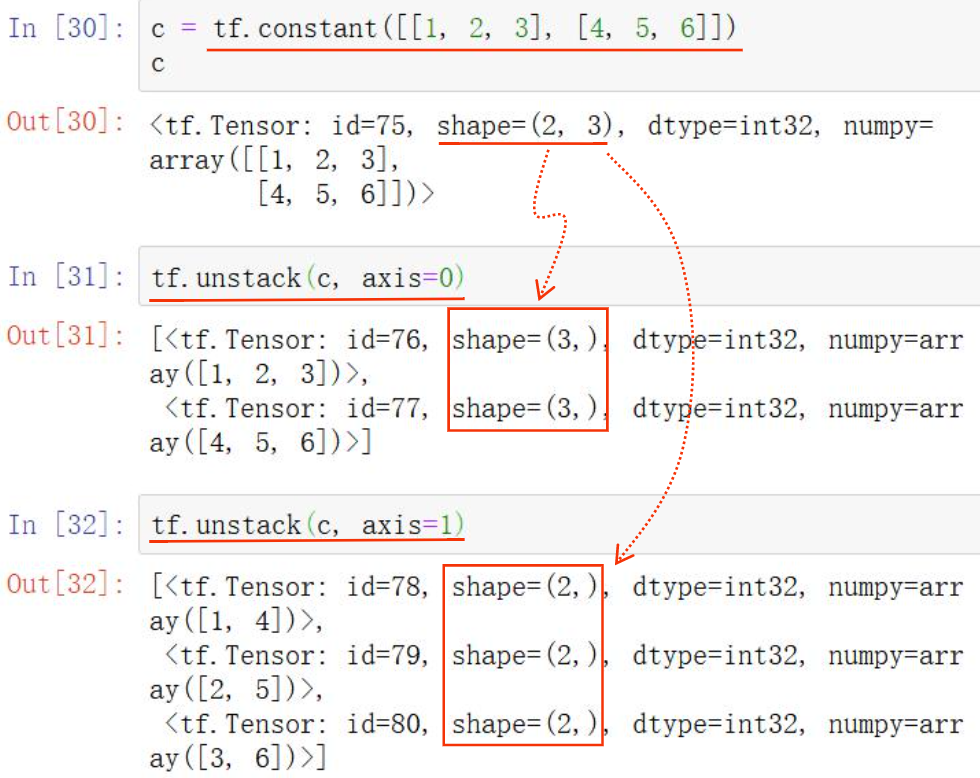
7、分解张量
是张量堆叠的逆运算,张量分解为多个张量,分解后得到的每个张量,和原来的张量相比,维数都少了一维。
tf.unstack(tensor, axis)
二、数据采样
获取张量指定位置的值,和 numpy 操作几乎完全一样。
1、索引

2、切片
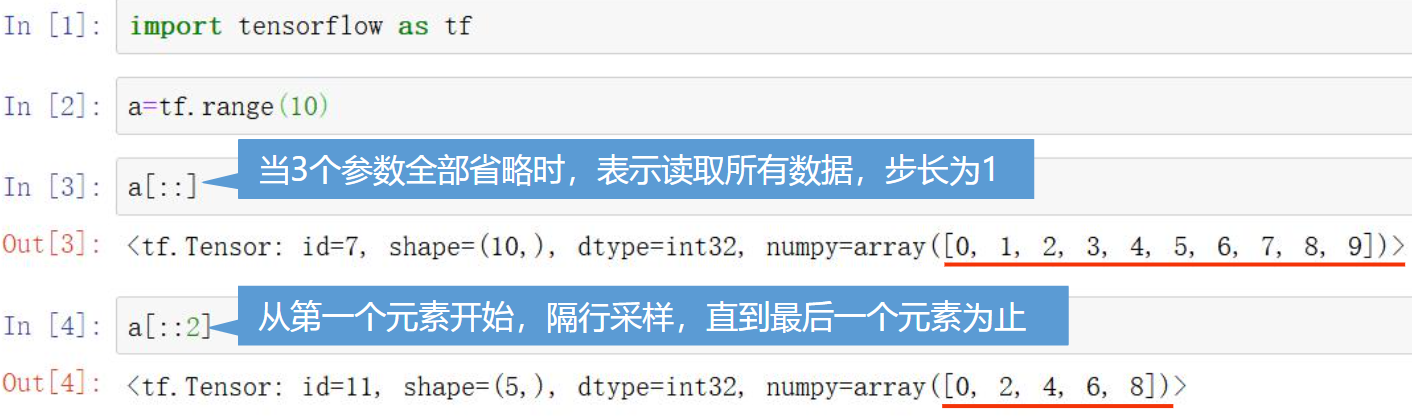
使用如下格式取得一定范围内的值。
[起始位置:结束位置:步长]
起始位置、结束位置 是前闭后开的,切片中不包含结束位置
起始位置、结束位置、步长都可以省略
步长可以是负数,这时起始位置的索引号,应该大于结束位置
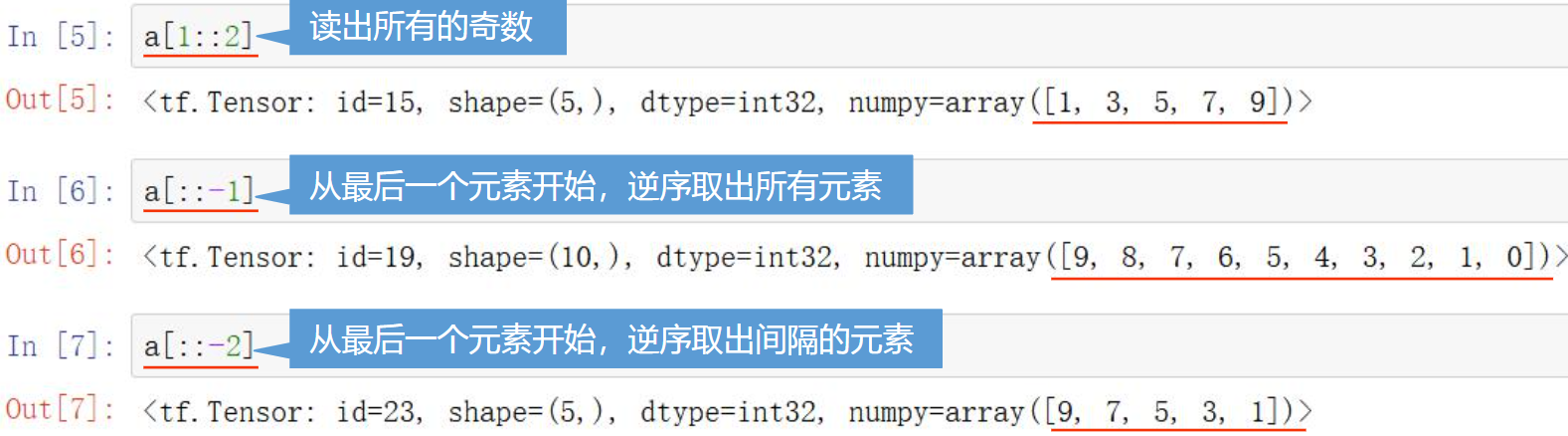
二维以上的张量维度之间用逗号间隔

3、数据提取
根据索引,抽取出没有规律的、特定的数据,用一个索引列表,将给定张量中对应索引值的元素提取出来
使用函数 gather(tensor. indices) 参数为 输入张量 和 索引值列表

如果是对 多维张量 进行取值,可以在 gather函数中指定维度:axis

同时采取多个点的值
使用函数 gather_nd(tensor, position)

也可以对部分维度进行采用,例如对一个三维张量,给出的位置列表中元素为二维等。
三、张量数字运算
1、基本数学运算
(1)加减乘除运算
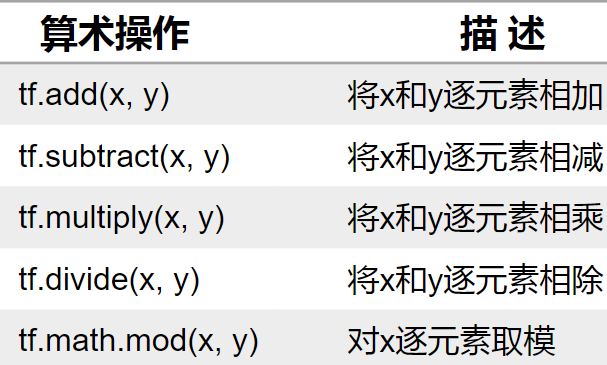
参数x,y是参加运算的两个张量,并且要求各个张量中的元素数据类型必须一致。
(2)幂指对数运算
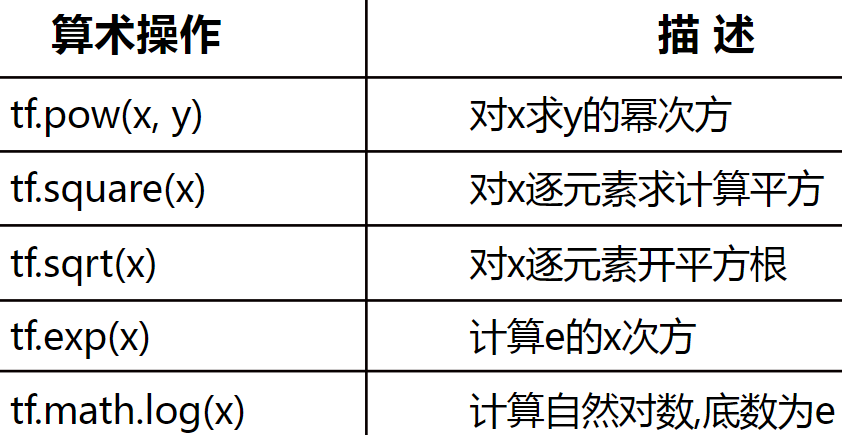
pow 函数也可对二维张量进行运算,例如:

对于求对数运算注意:tensorflow中只有以 e 为底的对数运算函数
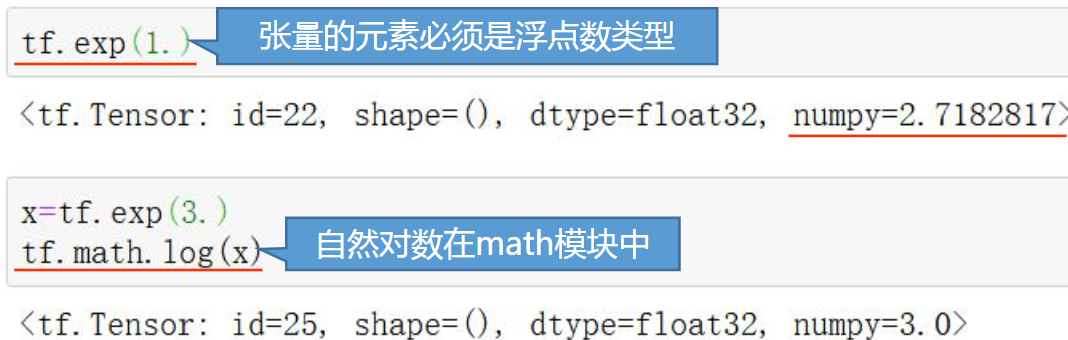
注意:sqrt、exp、math.log等函数中的张量的数据类型都必须是浮点型
(5)其他运算
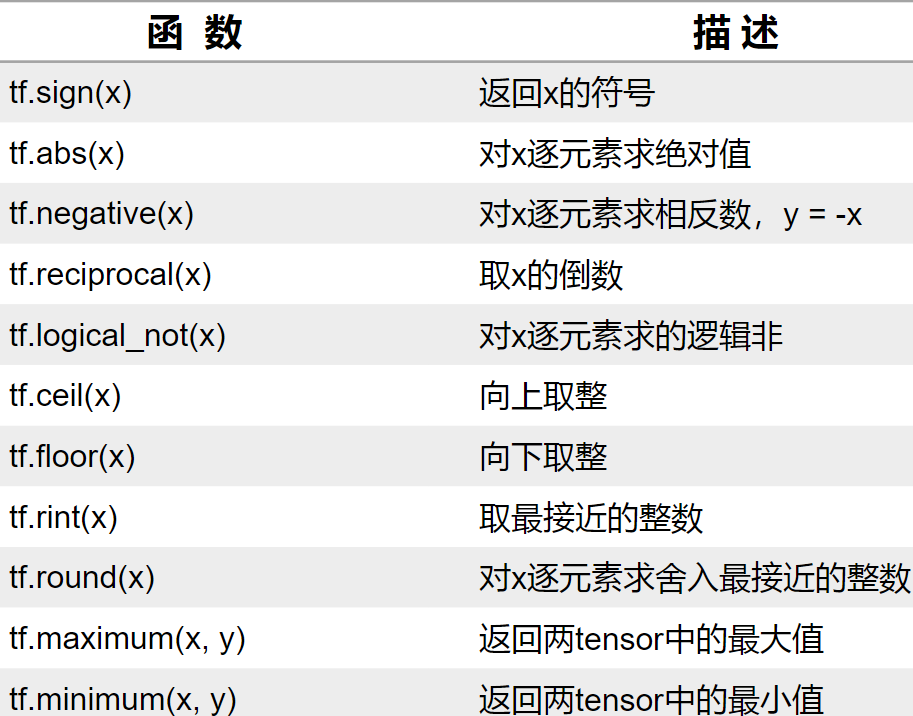
(6)三角函数和反三角函数运算
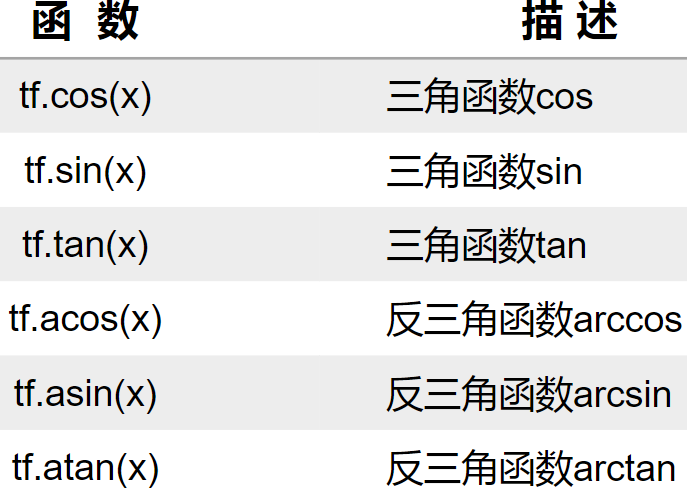
2、重载运算符
为了方便简洁,tensorflow重载了常用的运算符,如下表所示。
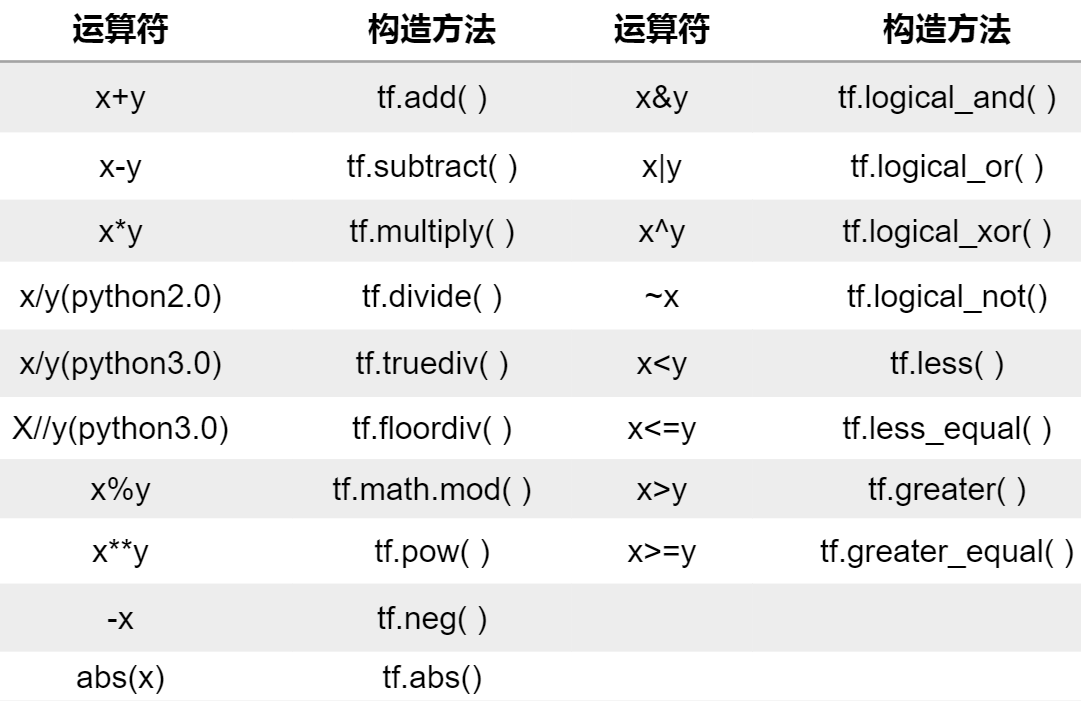
3、广播机制
可以实现不同维度的张量的运算,要求两个张量的最后一个维度必须相等。
当张量和一个数字值运算时,会将这个值广播到张量的各个元素。
4、张量和numpy之间的相互转换
当张量 和 numpy的ndarray 共同参与运算时,他们之间会自动的转换。
例如,若一个张量和一个 ndarray 执行 tf 下的函数操作,则 ndarray自动转换为张量,然后进行计算;反之亦然。
当使用运算符计算时,只要操作数中有张量对象,就都转换为张量,然后进行计算。
四、张量乘法运算
我们上面介绍的乘法是元素乘法,即对应元素相乘。实际中,我们更多使用的是张量乘法运算,即矩阵的乘法。在tensor中,用二维张量表示矩阵。使用方法如下:
向量乘法:tf.matmul() 函数 或 @运算符
例如 :张量 a 的形状为 (2, 3),张量 b 的形状为 (3, 2),使用 tf.matmul(a, b) 或 a@b 得到向量乘法结果。
五、常用数据统计函数
求张量在某个维度上、或者全局的统计值。

reduce表示降维,input_tensor表示输入的张量,axis表示对哪个维度进行计算,不指定则默认为全局。
注意:在求值时,为求得精确结果,可以指定数据类型为浮点型,或者使用 tf.cast(tensor, dtype) 函数转换为浮点型。
求最值的索引
使用 tf.argmax(input_tensor, axis) 和 tf.argmin(input_tensor, axis) 求最大值和最小值的索引。
注意:没有指定 axis 时,默认 axis=0,和上面的reduce 有区别。
其他常用函数
1、tf.data.Dataset.from_tensor_slices
data = tf.data.Dataset.from_tensor_slices((输入特征, 标签))
numpy 和 tensor 都适用于该语句的输入
feature = tf.constant([12, 23, 10, 17]) labels = tf.constant([0, 1, 1, 0]) dataset = tf.data.Dataset.from_tensor_slices((feature, labels))
2、enumerate
enumerate 是python 的内建函数,他可遍历每个元素,常在for循环中使用,得到的是一个元组 (索引,元素)
seq = ['one', 'two', 'three'] for i, element in enumerate(seq): print(i, element) for i in enumerate(seq): print(i)
结果:
0 one 1 two 2 three (0, 'one') (1, 'two') (2, 'three')
3、tf.one_hot
独热编码:在分类问题中,常用独热编码做标签
tf.one_hot(待转换数据,depth=几分类)
classes = 3 labels = tf.constant([1, 0, 2]) output = tf.one_hot(labels, depth=classes) print(output)
结果
tf.Tensor( [[0. 1. 0.] [1. 0. 0.] [0. 0. 1.]], shape=(3, 3), dtype=float32)
4、tf.nn.softmax
当n分类的n个输出通过softmax()函数,便符合概率分布。也就是使输出的每个值在0~1之间,而这些值的和为1.
y = tf.constant([1, 2, 3,4], dtype=tf.float32) # 必须是浮点型 y_pro = tf.nn.softmax(y) print(y_pro)
结果:
tf.Tensor([0.0320586 0.08714432 0.23688284 0.6439143 ], shape=(4,), dtype=float32)
5、assign_sub
赋值操作,更新参数的值并返回。调用 assign_sub前,要先用 tf.Variable 指定为可训练变量(可自更新)
w.assign_sub(w要自减的内容)
w = tf.Variable(4) w.assign_sub(1) # w -= 1 print(w)
6、np.random.RandomState
import numpy as np # 返回一个 [0, 1) 的随机值 rdm = np.random.RandomState(seed=1) # 设置随机数种子 a = rdm.rand() # 返回一个随机标量 b = rdm.rand(2, 3) # 返回维度为2行3列随机数矩阵 print(a, " ", b)
7、
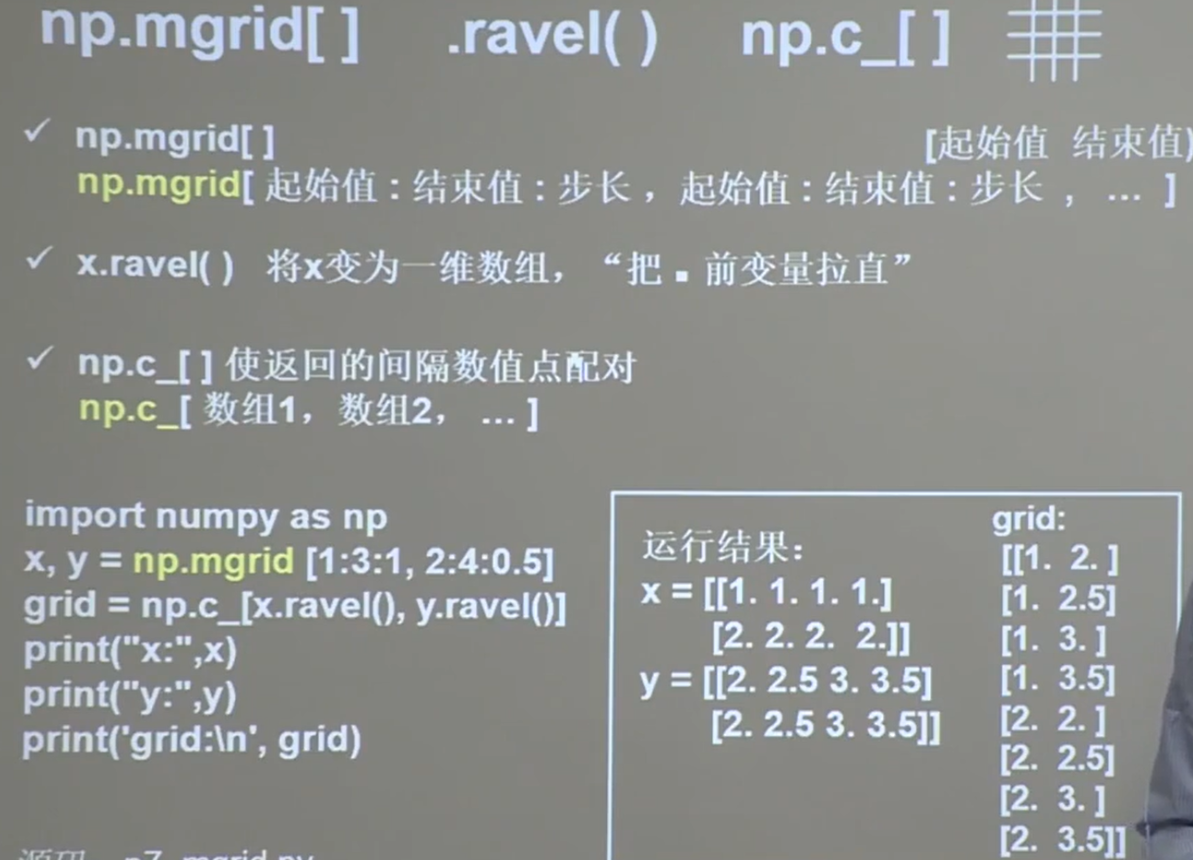
综上。