这篇博客来记录下python对文件的操作。
一、对文件的操作分为三步:
1、打开文件获取文件的句柄,句柄就理解为这个文件
2、通过文件句柄操作文件
3、关闭文件
现有文件file.txt
还记得 你说家是唯一的城堡
随着稻香河流继续奔跑
微微笑 小时候的梦我知道
二、文件的基本操作
python2和3都有open方法,python2中还可以用file()打开文件,python3只有open()
f = open('file','r',encoding='utf-8') #以只读方式打开一个文件,获取文件句柄,如果是读的话,r可以不写,默认就是只读 print(f.readline())#获取文件的第一行内容 print(type(f.readline())) #<class 'str'> print(f.readlines())#是把文件的每一行放到一个list里面 f.seek(0) print(f.read())#读文件 f.close() #关闭文件
window的默认编码是GBK, Python默认是utf-8
window下不加utf-8会报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 8: illegal multibyte sequence
打开文件时需要指定文件路径和以何种方式打开文件,打开后,即可获取改文件句柄,后面通过此文件句柄对该文件操作
f = open('file','r+',encoding='utf-8') #encoding参数可以指定文件的编码 print(f.readline()) #读一行 print(f.readlines())#读取所有文件内容,返回一个list,元素是每行的数据,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆 print(f.read()) #读取所有内容,大文件时不要用,因为会把文件内容都读到内存中,内存不够的话,会把内存撑爆 print(f.readable()) #判断文件是否可读 print(f.writable()) #判断文件是否可写 print(f.encoding) #打印文件的编码 print(f.tell()) #获取当前文件的指针指向 f.seek(0) #把当前文件指针指向哪 f.write('稻香') #写入内容 f.writelines(['稻香','周杰伦']) #将一个列表写入文件中 f.flush() #写入文件后,立即从内存中把数据写到磁盘中 f.truncate() #清空文件内容 f.close() #关闭文件
f.write()#只能写字符串
f.writelines(['123','123'])#既可以传字符串也可以传list,但用writelines写字符串也会循环,效率会低
writelines会帮助咱们循环一次,仅限写入一维list
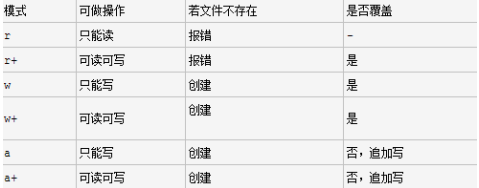
三、打开文件的模式
1、基本打开方式
r,只读模式(默认),不能写,文件不存在会报错
f = open('file',encoding='utf-8') #默认只读模式 print(f.read()) #可读 f.write('test')#不能写,io.UnsupportedOperation: not writable f1 = open('file1',encoding='utf-8')#f1不存在,会报错,No such file or directory: 'file1'
w,只写模式,不可读,不存在则创建,存在则删除内容写入
f = open('file','w',encoding='utf-8') #写模式 f.write('test')#清空原有内容并写入 print(f.read()) #不可读,io.UnsupportedOperation: not readable f1 = open('file1','w',encoding='utf-8')#f1不存,创建f1
a,追加模式,不可读,不存在则创建,存在则只追加内容
f = open('file','a',encoding='utf-8') #追加模式 f.write('test')#能写,file末尾追加test print(f.read()) #不可读,io.UnsupportedOperation: not readable f1 = open('file1','w',encoding='utf-8')#f1不存,创建f1
2、“+”表示同时读写某个文件
r+,可读可写(从文件开头写入)可追加,文件不存在会报错
f = open('file','r+',encoding='utf-8') #读写模式 print(f.read()) #可读 f1 = open('file1','r+',encoding='utf-8') f1.write('bb') #能写,从文件开头写入覆盖,f1:aaaa, 写入后变为bbaa f2 = open('file2','r+',encoding='utf-8')#f2不存,会报错
w+,写读模式,已经存在的文件内容会被清空,只能读到已经写的内容
f = open('file','w+',encoding='utf-8') #写读模式 print(f.read()) #清空f,不会报错 f1 = open('file1','w+',encoding='utf-8')#f1为'aaaa' f1.write('bb') #清空原有内容并写入 f2 = open('file2','w+',encoding='utf-8')#f2不存,创建f2
a+,追加读写模式,不存在则创建,存在则只追加内容
f = open('file','a+',encoding='utf-8') #追加读写模式 print(f.read()) #可读,但读取为空,追加读模式默认指针在文末 f1 = open('file1','a+',encoding='utf-8')#f1为'aaaa' f1.write('bb') #可写,file1末尾追加写入‘bb',f1为‘aaaabb’ f2 = open('file2','a+',encoding='utf-8')#f2不存,创建f2
综上只要沾上r,文件不存在就会报错;只要沾上w,都会清空原来的内容;所以友好的方式是a+。
3、“U”表示在读取时,可以将 自动转换成 (与r或r+模式同试用)
rU
r+U
4、“b”表示处理二进制文件(如FTP发送上传ISO镜像文件。linux可忽略,windows处理二进制文件时需标注)
wb
rb
ab
四、文件的指针
是用来记录文件到底读到哪里了,f.seek(0) 移动文件指针到最前面
f = open('file','r+',encoding='utf-8') print('f.readlines()',f.readlines()) print('f.read',f.read())#读不到东西,因为readlines已经将文件指针指向文件末尾了
f = open('file','a+',encoding='utf-8') print('f.read',f.read())#读不到东西,因为a+模式指针默认指向文件末尾 f.seek(0) print('f.read',f.read())#加入seek(0)后可以读到 f.write('test') f.seek(0) print('f.read',f.read())#seek移动完文件指针后,是只能读,写的时候还是在文件末尾写
五、读取大文件的高效做法
用上面的read()和readlines()方法操作文件的话,会先把文件所有内容读到内存中,这样的话,内存数据一多,非常卡,高效的操作,就是读一行操作一行,读过的内容就从内存中释放了
f = open('file','r+',encoding='utf-8') for line in f:#读完一行的话,就会释放一行的内存 print(line)
六、with使用
在操作文件的时候,经常忘了关闭文件,这样的就可以使用with,它会在使用完这个文件句柄之后,自动关闭该文件
with open('稻香','a+',encoding='utf-8') as f: #打开一个文件,把这个文件的句柄付给f for line in f: print(line)
打开多个文件
with open('file',encoding='utf-8') as fr, open('file_bak','w',encoding='utf-8') as fw: for line in fr:#循环file.txt中的每一行 fw.write(line)#写到file_bak文件中
七、缓冲区
电脑在执行f.write()这种写文件操作时,会先写入内存的缓冲区,当缓冲区满了以后,再从内存写入磁盘。因此有时执行完f.write()写操作,磁盘并未写入,原因是写入缓冲区,还未写入磁盘。此时可以强制写入磁盘。
fw = open('username','a+',encoding='utf-8') fw.write('Amy')#有时写完,磁盘并未写入,原因是写入缓冲区,还未写入磁盘 fw.flush() #强制把缓冲区里面的数据写到磁盘上
八、修改文件
修改文件有两种方式,一种简单粗暴直接,把文件的全部内容读到内存中,然后把原有的文件内容清空,重新写新的内容
1、打开一个文件,获取到它的所有内容(磁盘-> 内存)
2、对内容进行修改
3、清空原文件内容
4、把新的内容写进去
syz_Amy,78910 syz_Kate,78910 syz_Lily,78910 syz_Ben,78910
f = open('username','a+',encoding='utf-8') f.seek(0) all_str = f.read() new_str = all_str.replace('78910','123456') #替换文件中的密码 f.seek(0) #读完后,指针又指向文件末尾了,如果不重新seek,下面的清空文件不会清空指针之前的内容 f.truncate()#清空文件内容 f.write(new_str) f.close()
f = open('username','a+',encoding='utf-8') f.seek(0) all_str = '' for line in f: new_line = line.split('_')[-1] #将所有用户名前面的'syz_'去除 all_str += new_line f.seek(0) f.truncate()#清空文件内容 f.write(all_str) f.close()
第二种是把修改后的文件内容写到一个新的文件中
1、打开2个文件
2、a文件,读取一行
3、写一行写到b文件
4、a.txt a.txt.bak
5、删掉a文件,把b文件的文件名改为a文件名
桃flower
杏flower
梨flower
import os with open('words',encoding='utf-8') as fr, open('.words.bak','a+',encoding='utf-8') as fw: for line in fr: new_line = line.replace('flower','花')#读取原文件并替换 fw.write(new_line)#将替换后的内容写入新文件 os.remove('words') #删除原文件 os.rename('.words.bak','words') #重命名新文件