做任何事情都要有目标,然后根据这个目标根据自身的条件和外部的情况制定一个思路,这个思路也可以理解为实现目标的路径。那么大数据的平台搭建也不例外。
脚本工具化
在数据收集,存储、分析的初期,通常来说程序员都是根据业务需求,通过一些脚本来完成数据收集,分析的工作。表面上是完成了一些数据操作的功能,同时也满足了用户的需求,但是在编写脚本的时候,都是“头疼医头脚疼医脚”,只是针对具体的数据问题提出解决方法。
没有一个统一的解决方案,针对一些基础通用的功能也没有做抽象和提取,导致脚本维护的成本增加,后期服用的成本也会增高,有重复造轮子的嫌疑,效率不高。
因此,我们会讲这些脚本组件包装成一个个工具,用命令行或者 UI 界面的方式提供给客户。
这样一来,脚本的经验得到了总结和提炼,整个工具考虑得会比组件更加周到,效率有所提高。
工具服务化
有了工具可以满足一些数据上的需求,但是由于工具运行在本地无法发挥公用的特性。为了让工具被更加广泛的使用,于是将其以服务的方式发布的云端,此时业务人员可以在有网络的地方访问到大数据工具,从而实现计算和分析工作,打破了地域的限制。
服务平台化
既然有了服务上云,那么将这些服务做一些聚合的操作,让相关联的服务互相沟通产生“化学反应”,从而给用户带来更大的价值。同时可以将多个数据源都接入到平台中,利用这些服务提供给客户更高的价值。
此时,数据源,服务,客户需求都是不同的,那么通过平台进行整合,从而显示出更大的威力。现在流行的 SAAS 系统就是一个很好的例子,采用多租用户的方式,整合资源提供优质的数据服务。
平台产品化
既然产生了一个大数据的平台,整合了数据、服务、需求(客户)各个方面的资源。
如果继续发展就需要针对不同的用户需求建立不同的业务场景,由于行业不同、企业内部和市场环境不同,大数据的应用场景也千差万别。此时如果还提供统一的数据服务恐怕就不合时宜了,那么此时需要针对行业以及细分领域进行业务服务的客制化。针对一些行业底层的业务进行抽象和拆分,给用户更多的客制化空间,针对不同的行业和使用场景退出不同的大数据产品,给到用户。
图 1:大数据平台指导方针

从脚本到工具,服务、平台、产品的转化不仅是大数据平台发展的进程和步骤,同样也是不同规模企业进行大数据平台搭建的准绳。为什么这么说呢?技术始终是为业务服务的,大数据平台平台也是如此,只要让数据产生对企业有正向推动力就是正确的方向。在最开始的时候,就可以通过脚本的方式进行实验和试错,积累数据分析抽取的经验,从而得到一些对业务有价值的数据信息。后面通过不断迭代和试错,将这些经验从脚本→工具→服务→平台→产品进行转换。这样以终为始,即减少了开发走的弯路,也提高了效率,最重要的是做出来的东西是有价值的,老板的投入看得见。每个企业也可以根据自身情况选择对应的切入点,不用做大而全的大数据平台,做适合自己的就好。
大数据平台的建设路径
说了建立大数据平台的基本思路以后,我们知道针对不同的企业业务规模以及不同的发展阶段,可以选择适合自身的大数据平台建设思路。那么这里就说说如何建立大数据平台,怎样的建设路径能够帮助我们落地大数据平台,这里分两个方面讨论。
针对业务场景的建设方式
正如上面提到的以终为始的思路,针对企业面对的具体业务场景建立大数据平台,让数据针对具体的业务发挥作用,是最能够体现数据价值的。
例如:企业需要做拉新的线下活动,假设这次拉新 1 万人。针对的群体是学校的学生,那么需要多少花多长时间,在多少个学校,摆出多少个展位才能达到效果。这些都可以通过企业系统中现有的数据进行分析,得到结果。
因此这种方式的优点是 :
和具体业务结合紧密,业务逻辑可以根据企业业务状况进行定制,从而最大限度匹配需求。
技术开发人员与业务人员的交互效果和业务复杂度可控,甚至是无缝对接,基本屏蔽与业务无关的内容,确保易用性。业务人员定义的需求,使用者就是业务人员本身。
专业对口,不考虑平台通用性问题,也不用考虑与其他平台、应用的对接。整体平台用时短,成型快,效果明显。
这种方式的缺点是:
仅限于固定的业务场景拓展性差,对整个行业和系统缺乏统筹考虑。
可能会做重复建设的工作,从长远来看开发效率不高。
通用组件的建设方式
“通用”顾名思义,将大数据平台中通用的功能抽离出来,通常这些功能和具体的业务实现无关。无论什么业务场景都会用到的,例如:数据收集、数据导入、数据计算、数据搜索、数据展示等。让后在这些基础功能/模块的基础上进行业务功能的封装,其目的很明确,为了更长远的业务发展做准备。
此类建设方式不仅关注当前业务的落地,更关系以后不同业务场景,不同行业的平台扩展。
这种方式的优点是 :
通用功能作为大数据平台的基础,可以针对不同业务场景进行拓展。
同功能避免重复造轮子,将技术功能和业务需求进行解耦。
对于架构设计考虑会更多,对行业的理解会更深,对使用场景的考虑会更多。
这种方式的缺点是:
架构设计难度大,考虑因素多,开发周期长。
架构中模块关系负载,开发复杂度高。
对业务的抽象能力有要求,需要一个或者多个行业的丰富经验,业务理解成本较高。
上面两种基于业务和通用组件的建设方式各有利弊。在企业进行搭建大数据平台的时候,需要根据自身的情况进行抉择。如果是大数据刚刚起步的企业建议使用前一种方式,边做边摸索,边总结边重构,最终过度到第二种方式。如果说企业在大数据平台技术和业务上都有了深厚的积累,则可以考虑从更高的视角,切入第二种方式。
大数据平台的实现架构
说了大数据平台的思路和实现路径以后,再来从技术架构的角度来看看如何落地。
有的企业会借鉴其他企业的成功案例,有的企业会根据自身情况进行摸索。笔者在这里给出的建议是依托方法论,结合企业实际情况,参照行业经典案例进行构建。说起来有点虚,来看看具体的架构实现。
Lambda 架构
Lambda 架构(Lambda Architecture)是由 Twitter 工程师南森·马茨(Nathan Marz)提出的大数据处理架构。
这一架构的提出基于马茨在 BackType 和 Twitter 上的分布式数据处理系统的经验。
图 2:Lambda 架构示意图
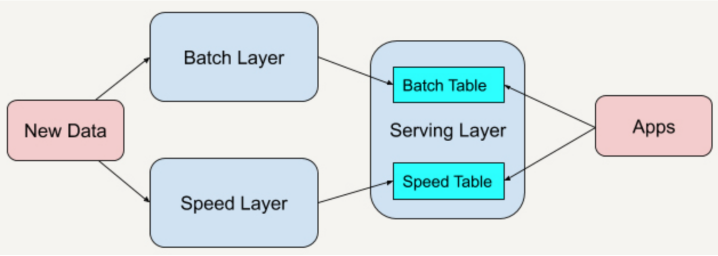
如图 2 所示,Lambda 共分为三层,分别是批处理层(Batch Layer),速度处理层(Speed Layer),以及服务层(Serving Layer)。
下面来看看他们分别有什么作用:
批处理层(Batch Layer),存储管理主数据集和预先批处理计算好的视图。这部分数据对及时性要求不高,会采取批处理的方式同步到主库中,通常以定时任务的形式存在。
速度处理层(Speed Layer),会处理实时数据。由于对数据及时性的要求,这部分数据会通过内存计算出结果,马上提供给使用者,同时对于数据的准确性要求也不高。
会通过批处理层入库以后针对部分数据进行校验,通常以 Storm 之类的应用的形式出现。
服务层(Serving Layer),数据进入到平台以后,会进行存储、同步、计算、分析等过程。但是,最终都是需要提供给用户使用的。由于用户使用的方式和业务试图的差异性,需要有一个服务对其进行权衡。
服务层就应运而生了,它主要负责以服务的方式将数据提供给终端客户,其形式有报表、仪表盘、API 接口等等。
如果说 Lambda 架构是方法论的话,那么每个企业会根据其建立自己的大数据平台,从架构方面来看,都大同小异。
图 3:大数据平台技术架构
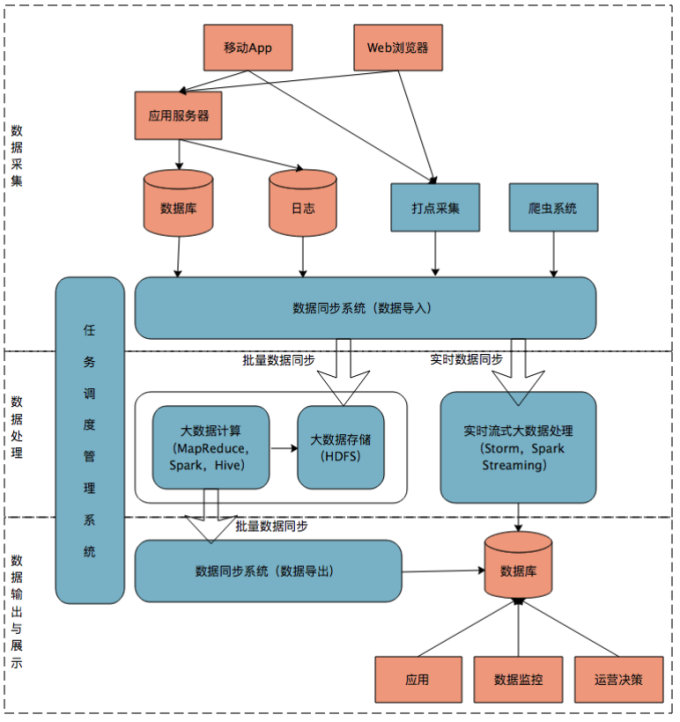
如图 3 所示大数据平台由上到下,可分为:
数据采集
数据处理
数据输出与展示
①数据采集
里包括从多个源头收集数据信息,例如:浏览器、移动设备、服务器日志文件。再将这些信息数据和日志等同步到大数据系统中,注意同步的过程需要考虑数据源和数据结构的差异。同步会使用 Sqoop,日志同步可以选择 Flume,行为数据采集经过格式化转换后通过 Kafka 等消息队列进行传递。这些数据在解决了数据源和数据异构以后,还需要进行数据清洗,特别是日志和爬虫数据,需要提取对业务有意义的数据进行存储。
②数据处理
同步的数据存储在 HDFS 之类的分布式数据库中。可以通过 MapReduce、Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS 或者其他库。这里会根据数据的及时性分为离线计算和实时计算,刚好和 Lambda 中的批量处理和速度处理相对应。比如针对用户的购物行为进行关联性数据挖掘,这时候数据量大、逻辑复杂,需要较长的运行时间,这类计算可以使用离线计算来处理。
另外对处理时间敏感的计算,比如双 11 每秒产生的订单数,为了及时地展示和监控,会采用流式计算。通常用 Storm、Spark Steaming 等流式计算引擎完成,可以在秒级甚至毫秒级内完成处理。
③数据输出与展示
有了采集和处理就一定会面对输出和展示。一般来说通过应用程序直接访问数据库来完成数据展示。由于对于业务、市场、管理的复杂性,对外需要展示客户、竞争对手、产品的信息;对内需要根据操作层、管理层、决策层进行数据的聚合和汇总。对数据输出和展示有一定要求。后面我们会针对这部分进行展开说明。
由于通过上面三个部分需要写作完成采集、同步、存储、计算、展示的工作,因此需要任务调度管理系统对其进行协调调用。
大数据平台驱动业务运营
前面我们说了如何在企业中落地大数据平台,其中提到了以终为始的概念,大数据平台最终还是需要为业务运营系统提供正向推力的。有了大数据平台就需要用好它,从中挖掘出更多的商业价值。
通常的情况是这样的,根据公司战略目标以及公司目前的能力和外部的威胁和机会,公司会定义一个战略思路。这个是公司发展的纲领,围绕这个战略纲领业务部门和运营部门对其进行分析和拆分,生成业务需求,然后从这个业务需要推到出需要哪些关键要素(节点)。再来看这些关键要素需要哪些数据为其进行决策和支撑。最后,将这些要素变成业务需求提交给产品团队进行分析,然后交由大数据技术团队完成对应的功能。
图 4:大数据平台驱动业务运营

从思考过程来看是现有业务再才有大数据平台的功能,但是从执行层面来看。
为了实现业务的功能业务人员是先要到大数据平台上面获取对应的信息,再才能实现业务决策和行为。
例如上面提到的拉新的例子,业务人员为了达到拉新 1 万人的目的,会先到大数据平台搜索。
针对产品的受众,偏好、价格、沟通方式、市场、促销等方面的问题,获取对他们有价值的信息,例如:在哪些学校、针对什么年级的学生、开辟多少展位完成这次活动。
因此在执行过程中是大数据本身的价值在驱动业务前行的。思考和行动在方向上正好相反。
数据可视化平台的实践
既然要对企业的主要业务进行驱动和推动的作用,那么就不得不提到大数据平台的可视化以及展示功能了。
作为可视化的大数据平台需要从以下几个方面进行实践:
①用户管理与权限
平台的建立是为用户服务的,首先要标定服务的用户。由于用户的多样性,有的是企业内部客户,有的是合作伙伴,还有终端用户。
因此需要考虑:
用户的权限和角色管理。
业务分组功能,针对业务分类、子分类对用户进行划分。
根据数据功能进行不同的安全等级管理,包括流程管理。
支持对原数据的检索和浏览。
②多样化的产品功能
由于使用者的不同,导致面向的业务场景也会有所不同。那么针对不同的业务场景就要展示不同的数据输出:
提供多种图表、报表功能。
针对图表、报表提供自定义字段、过滤器功能。
增加组织视图和个人视图从不同角度审视数据。
③对其他系统的集成功能
即便大数据平台已经整合了企业级别的各种数据,拥有多种数据源,但是依旧存在短板。
如果针对其他业务系统或者生产系统进行整合,通过功能、数据集成,让数据产生关联便会产生更大的能量:
集成企业、上下游、供应链 ERP 系统。
与行业数据、国家经济指标进行结合。
与通用的邮件、通知、效率系统进行集成。
总结
从大数据平台搭建思路作为切入点,通过脚本、工具、服务、平台、产品几个递进的阶段,描述了企业在不同的发展阶段可以采取不同的思路。如果说有了思路,那么在执行的有两种方式:业务场景和通用组件来进行。落地到大数据平台架构的时候,利用 Lambda 架构的方法论,进行数据采集、处理、展示。大数据平台是为业务创造价值,反过来通过平台也可以驱动业务的发展。通过数据库可视化平台的实践,让业务人员通过多样的数据功能和大数据平台产生链接,最终产生商业价值。