在介绍矩阵的压缩存储前,我们需要明确一个概念:对于特殊矩阵,比如对称矩阵,稀疏矩阵,上(下)三角矩阵,在数据结构中相同的数据元素只存储一个。
三元组顺序表
稀疏矩阵由于其自身的稀疏特性,通过压缩可以大大节省稀疏矩阵的内存代价。具体操作是:将非零元素所在的行、列以及它的值构成一个三元组(i,j,v),然后再按某种规律存储这些三元组,这种方法可以节约存储空间 。
如下图所示为一个稀疏矩阵,我们应该怎么样存储呢?
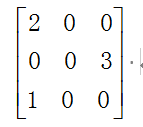
若对其进行压缩存储,我们可以将一个非零数组元素的三元看成一个单位存入一维数组,具体如下所示。比如(1,1,1)代表第一行第一列的元素值为1。注意,这里我们只存储非零值。

具体代码如下:
#include<stdio.h>
#include <stdlib.h>
#include <time.h>
#define NUMBER 3
//三元组结构体
typedef struct {
//行标r,列标c
int r,c;
//元素值
int data;
}triple;
//矩阵的结构表示
typedef struct {
//存储该矩阵中所有非0元素的三元组
triple data[NUMBER];
//row和column分别记录矩阵的行数和列数,num记录矩阵中所有的非0元素的个数
int row,column,num;
}TSMatrix;
//输出存储的稀疏矩阵
void print(TSMatrix M);
int main() {
int i;
srand((unsigned)time(NULL));
TSMatrix M;
M.row=3;
M.column=3;
M.num=3;
//初始化矩阵
for(i=0;i<M.num;i++){
//随机数范围[1,3]
M.data[i].r=rand()%M.num+1;
M.data[i].c=rand()%M.num+1;
M.data[i].data=rand()%10;
}
print(M);
return 0;
}
void print(TSMatrix M){
for(int i=1;i<=M.row;i++){
for(int j=1;j<=M.column;j++){
int value =0;
for(int k=0;k<M.num;k++){
//遍历时的r,c行列值和实际存储row,column行列值的比较,相同的话就说明有非零元素,打印存储的非0值
if(i == M.data[k].r && j == M.data[k].c){
printf("%d ",M.data[k].data);
value =1;
break;
}
}
if(value == 0)
printf("0 ");
}
printf("
");
}
}
行逻辑链接的顺序表
使用三元组顺序表存储稀疏矩阵,我们每次访问其中一个元素都要遍历整个矩阵,效率比较低。我们可以使用一个一维数组来存储每行第一个非零元素在一维数组中的位置,这样就可以提升访问效率。这样的表就叫做行逻辑链接的顺序表。
下图为一个稀疏矩阵,当使用行逻辑链接的顺序表对其进行压缩存储时,需要做以下两个工作:

1.将矩阵中的非 0 元素采用三元组的形式存储到一维数组 data 中:

2.使用数组 rpos 记录矩阵中每行第一个非 0 元素在一维数组中的存储位置。
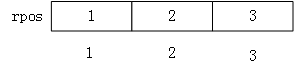
通过以上两步操作,即实现了使用行逻辑链接的顺序表存储稀疏矩阵。
此时,如果想从行逻辑链接的顺序表中提取元素,则可以借助 rpos 数组提高遍历数组的效率。
例如,提取图 1 稀疏矩阵中的元素 2 的过程如下:
由 rpos 数组可知,第一行首个非 0 元素位于data[1],因此在遍历此行时,可以直接从第 data[1] 的位置开始,一直遍历到下一行首个非 0 元素所在的位置(data[3])之前;
同样遍历第二行时,由 rpos 数组可知,此行首个非 0 元素位于 data[3],因此可以直接从第 data[3] 开始,一直遍历到下一行首个非 0 元素所在的位置(data[4])之前;遍历第三行时,由 rpos 数组可知,此行首个非 0 元素位于 data[4],由于这是矩阵的最后一行,因此一直遍历到 rpos 数组结束即可(也就是 data[tu],tu 指的是矩阵非 0 元素的总个数)。
具体代码如下
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXSIZE 12500
#define MAXRC 100
typedef struct
{
//行,列
int r,c;
//元素值
int e;
}Triple;
typedef struct
{
//矩阵中元素的个数
Triple data[MAXSIZE];
//每行第一个非零元素在data数组中的位置
int rpos[MAXRC];
//行数,列数,元素个数
int row,column,number;
}RLSMatrix;
//矩阵的输出函数
void print(RLSMatrix M){
for(int i=1;i<=M.row;i++){
for(int j=1;j<=M.column;j++){
int value=0;
if(i+1 <=M.row){
for(int k=M.rpos[i];k<M.rpos[i+1];k++){
if(i == M.data[k].r && j == M.data[k].c){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}else{
for(int k=M.rpos[i];k<=M.number;k++){
if(i == M.data[k].r && j == M.data[k].c){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}
}
printf("
");
}
}
int main()
{
int i;
//srand((unsigned)time(NULL));
RLSMatrix M;
//矩阵的大小
M.number = 4;
M.row = 3;
M.column = 4;
//每一行首个非零元素在一维数组中的位置
M.rpos[1] = 1;
M.rpos[2] = 3;
M.rpos[3] = 4;
M.data[1].e = 3;
M.data[1].r = 1;
M.data[1].c = 2;
M.data[2].e = 5;
M.data[2].r = 1;
M.data[2].c = 4;
M.data[3].e = 1;
M.data[3].r = 2;
M.data[3].c = 3;
M.data[4].e = 2;
M.data[4].r = 3;
M.data[4].c = 1;
//输出矩阵
print(M);
return 0;
}
十字链表法
关于十字链表法,具体可看下图。我们把矩阵的每一行每一列分别看成一个链表,然后将每一行和每一列的链表的第一个元素存放在一个数组中。这个数组就叫行链表的头指针数组,列链表的头指针数组。当我们访问矩阵的时候,就可以从行/列头指针数组中取出对应的指针,就可以访问这一行或者这一列的元素了。

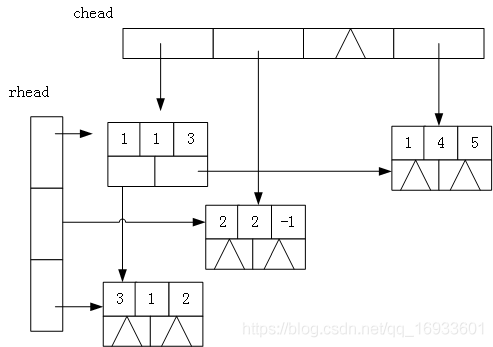
链表中节点的结构应如下图。所以,除了定义三元组的行,列,数值外,我们还需要定义指向行的指针,指向列的指针。最后还需要定义一个存放行/列链表头结点的数组专门存放各行各列的头结点。具体代码如下。

typedef struct CLNode
{
//矩阵三元组i代表行 j代表列 e代表当前位置的数据
int r, c, data;
//指针域 行指针 列指针
struct CLNode *prow, *pcolumn;
}CLNode, *CLink;
typedef struct
{
//行和列链表头数组 CLink rhead[] 这样写也可以。写成指针是为了方便动态分配内存
CLink *rhead, *chead;
//矩阵的行数,列数和非零元的个数
int rows, columns, num;
}CrossList;
下面我们将要根据用户输入的行数,列数,非零元素的值,来创建矩阵。
//注意检查用户的输入
do {
flag = 1;
printf("输入矩阵的行数、列数和非0元素个数:");
scanf("%d%d%d",&m,&n,&t);
if (m<0 || n<0 || t<0 || t>m*n)
flag = 0;
}while (!flag);
M.rows = m;
M.columns = n;
M.num = t;
用户输入合法的情况下我们要创建并初始化存放行列链表头的数组。
//因为下标从1开始,所以头结点指针多分配一个内存
if (!(M.rhead = (CLink*)malloc((m + 1) * sizeof(CLink))) || !(M.chead = (CLink*)malloc((n + 1) * sizeof(CLink))))
{
printf("初始化矩阵失败
");
exit(0);
}
// 初始化行头指针向量;各行链表为空链表
for (r = 1; r <= m; r++)
{
M.rhead[r] = NULL;
}
// 初始化列头指针向量;各列链表为空链表
for (c = 1; c <= n; c++)
{
M.chead[c] = NULL;
}
存放行列链表头的数组准备好了,接下来我们就要创建数据节点了。根据用户输入的行号,列好,数值创建节点。这里同样要检查用户的输入。
for (scanf("%d%d%d", &r,&c,&data); ((r<=0)||(c<=0)); scanf("%d%d%d", &r,&c,&data))
{
if (!(p = (CLNode*)malloc(sizeof(CLNode))))
{
printf("初始化三元组失败");
exit(0);
}
p->r = r;
p->c = c;
p->data= data;
}
当创建好一个节点之后,我们就要放到行或者列的正确的位置。根据输入的行号列号确定插入的位置。那么应该怎样去插入?分两种情况
1、当这一行中没有结点的时候,那么我们直接插入
2、当这一行中有结点的时候我们插入到正确的位置
对于第一个问题,因为之前已经对头结点数组进行了初始化NULL,所以直接根据NULL==M->rhead[i]就可以判断一行中有没有节点。
对于第二个问题,当行中有节点的时候,无非是插入到某个节点之前或者某个节点之后。什么时候插入到节点前?什么时候插入到节点后呢?
1.插入节点前:当我们要插入的节点的列号小于已经存在的节点的列号,这个时候就要插入到这个节点之前了。
2.插入节点后:当我们要插入的节点的列号大于已经存在的节点的列号,这个时候就要插入到这个节点之后了。
对于第一种情况,代码如下。
//p为准备插入的节点,要插入到M.rhead[r]之前。
if (NULL == M.rhead[r] || M.rhead[r]->c> c)
{
p->prow = M.rhead[r];
//M.rhead[r]要始终指向行的第一个节点
M.rhead[r] = p;
}
对于第二种情况,我们要插入的节点插入到已有节点的后面,那么,已有将要插入节点的列号必定大于已有节点的列号。我们只要找到一个节点比我们将要插入节点的列号大的节点就好,然后插入到这个节点的前面。如果现有的结点没有一个结点列号是大于要插入的节点的列号的,那么我们就应该插入到最后一个结点之后!
//我们要找到一个比q节点大的节点。在这个节点之前插入
for (q = M.rhead[r]; (q->prow) && q->prow->c < c; q = q->prow);
p->prow = q->prow;
q->prow = p;
对于列的插入同样如此,就不一一分析了,下面给出具体代码。
//链接到列的指定位置
if (NULL == M.chead[c] || M.chead[c]->r> r)
{
p->pcolumn = M.chead[c];
M.chead[c] = p;
}
else
{
for (q = M.chead[c]; (q->pcolumn) && q->pcolumn->r < r; q = q->pcolumn);
p->pcolumn = q->pcolumn;
q->pcolumn = p;
}
打印矩阵
对于十字链表矩阵的打印,我们每次从行/列头结点数组中取出每一行或者每一列的第一个节点依次往下访问就可以了,和普通的链表访问没有区别。如果对链表不熟悉的可以参考这篇文章史上最全单链表的增删改查反转等操作汇总以及5种排序算法(C语言)
void PrintClist(CrossList M)
{
for (int i = 1; i <= M.num; i++)
{
if (NULL != M.chead[i])
{
CLink p = M.chead[i];
while (NULL != p)
{
printf("%d %d %d
",p->r, p->c, p->data);
p = p->pcolumn;
}
}
}
}
完整代码如下:
/*
* @Description: 十字链表存储压缩矩阵
* @Version: V1.0
* @Autor: Carlos
* @Date: 2020-05-26 16:43:48
* @LastEditors: Carlos
* @LastEditTime: 2020-05-28 14:40:19
*/
#include<stdio.h>
#include<stdlib.h>
typedef struct CLNode
{
//矩阵三元组i代表行 j代表列 e代表当前位置的数据
int r, c, data;
//指针域 行指针 列指针
struct CLNode *prow, *pcolumn;
}CLNode, *CLink;
typedef struct
{
//行和列链表头指针
CLink *rhead, *chead;
//矩阵的行数,列数和非零元的个数
int rows, columns, num;
}CrossList;
CrossList InitClist(CrossList M)
{
CLNode *p,*q;
int r,c,data;
int m, n, t;
int flag;
// printf("输入矩阵的行数、列数和非0元素个数:");
// scanf("%d%d%d",&m,&n,&t);
do {
flag = 1;
printf("输入矩阵的行数、列数和非0元素个数:");
scanf("%d%d%d",&m,&n,&t);
if (m<0 || n<0 || t<0 )
flag = 0;
}while (!flag);
M.rows = m;
M.columns = n;
M.num = t;
//因为下标从1开始,所以头结点指针多分配一个内存
if (!(M.rhead = (CLink*)malloc((m + 1) * sizeof(CLink))) || !(M.chead = (CLink*)malloc((n + 1) * sizeof(CLink))))
{
printf("初始化矩阵失败
");
exit(0);
}
// 初始化行头指针向量;各行链表为空链表
for (r = 1; r <= m; r++)
{
M.rhead[r] = NULL;
}
// 初始化列头指针向量;各列链表为空链表
for (c = 1; c <= n; c++)
{
M.chead[c] = NULL;
}
//行数列数不为0
for (scanf("%d%d%d", &r,&c,&data); ((r<=0)||(c<=0)); scanf("%d%d%d", &r,&c,&data))
{
if (!(p = (CLNode*)malloc(sizeof(CLNode))))
{
printf("初始化三元组失败");
exit(0);
}
p->r = r;
p->c = c;
p->data= data;
//链接到行的指定位置。
if (NULL == M.rhead[r] || M.rhead[r]->c> c)
{
p->prow = M.rhead[r];
M.rhead[r] = p;
}
else
{
for (q = M.rhead[r]; (q->prow) && q->prow->c < c; q = q->prow);
p->prow = q->prow;
q->prow = p;
}
//链接到列的指定位置
if (NULL == M.chead[c] || M.chead[c]->r> r)
{
p->pcolumn = M.chead[c];
M.chead[c] = p;
}
else
{
for (q = M.chead[c]; (q->pcolumn) && q->pcolumn->r < r; q = q->pcolumn);
p->pcolumn = q->pcolumn;
q->pcolumn = p;
}
}
return M;
}
void PrintClist(CrossList M)
{
for (int i = 1; i <= M.num; i++)
{
if (NULL != M.chead[i])
{
CLink p = M.chead[i];
while (NULL != p)
{
printf("%d %d %d
",p->r, p->c, p->data);
p = p->pcolumn;
}
}
}
}
int main()
{
CrossList M;
M.rhead = NULL;
M.chead = NULL;
M = InitClist(M);
PrintClist(M);
return 0;
}
文中代码均已测试,有任何意见或者建议均可联系我。欢迎学习交流!
如果觉得写的不错,请点个赞再走,谢谢!
有任何问题,均可通过公告中的二维码联系我