转发请注明原创地址 http://www.cnblogs.com/dongxiao-yang/p/7463693.html
kafka新版consumer所有的group管理工作在服务端都由GroupCoordinator这个新角色来处理,最近测试发现consumer在reblance过程中会有各种各样的等待行为,于是研究下相关源码,GroupCoordinator是broker服务端处理consumer各种group相关请求的管理类。本次源码研究版本是0.10.2.0
首先贴一下huxihx在Kafka消费组(consumer group)画过的一个流程图
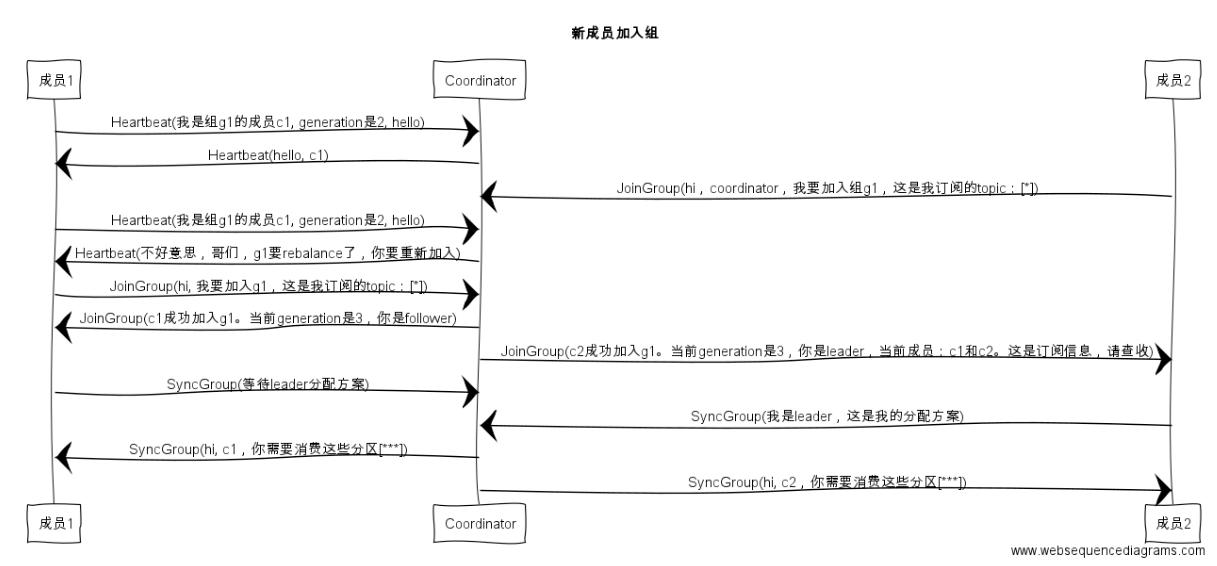
这个图以及下面的几个流程图非常清晰的表明了当一个consumer(无论是新初始化的实例还是各种情况重新reblance的已有客户端)试图加入一个group的第一步都是先发送一个JoinGoupRequest到Coordinator,这个请求里具体包含了什么信息可以从AbstractCoordinator这个类的源代码找到
/**
* Join the group and return the assignment for the next generation. This function handles both
* JoinGroup and SyncGroup, delegating to {@link #performAssignment(String, String, Map)} if
* elected leader by the coordinator.
* @return A request future which wraps the assignment returned from the group leader
*/
private RequestFuture<ByteBuffer> sendJoinGroupRequest() {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
// send a join group request to the coordinator
log.info("(Re-)joining group {}", groupId);
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
groupId,
this.sessionTimeoutMs,
this.generation.memberId,
protocolType(),
metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs);
log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
return client.send(coordinator, requestBuilder)
.compose(new JoinGroupResponseHandler());
private Generation generation = Generation.NO_GENERATION;
protected static class Generation {
public static final Generation NO_GENERATION = new Generation(
OffsetCommitRequest.DEFAULT_GENERATION_ID,
JoinGroupRequest.UNKNOWN_MEMBER_ID,
null);
public final int generationId;
public final String memberId;
public final String protocol;
public Generation(int generationId, String memberId, String protocol) {
this.generationId = generationId;
this.memberId = memberId;
this.protocol = protocol;
}
}
上述可以看出sendJoinGroupRequest里面包含了groupid,sesseionTimeout,membeid,rebalancetimeout等几个属性,如果是新初始化的consumer程序generation属性默认为NO_GENERATION,memberid就是JoinGroupRequest.UNKNOWN_MEMBER_ID
然后是server处理sendJoinGroupRequest的代码,请求被转交到了GroupCoordinator类里的handleJoinGroup方法,该方法在校验了部分参数和group状态的合法性后将具体工作放到了doJoinGroup方法里。
private def doJoinGroup(group: GroupMetadata,
memberId: String,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
group synchronized {
if (!group.is(Empty) && (group.protocolType != Some(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) {
// if the new member does not support the group protocol, reject it
responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL.code))
} else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) {
// if the member trying to register with a un-recognized id, send the response to let
// it reset its member id and retry
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
group.currentState match {
case Dead =>
// if the group is marked as dead, it means some other thread has just removed the group
// from the coordinator metadata; this is likely that the group has migrated to some other
// coordinator OR the group is in a transient unstable phase. Let the member retry
// joining without the specified member id,
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
case PreparingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
case AwaitingSync =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
if (member.matches(protocols)) {
// member is joining with the same metadata (which could be because it failed to
// receive the initial JoinGroup response), so just return current group information
// for the current generation.
responseCallback(JoinGroupResult(
members = if (memberId == group.leaderId) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
} else {
// member has changed metadata, so force a rebalance
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
}
case Empty | Stable =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
if (memberId == group.leaderId || !member.matches(protocols)) {
// force a rebalance if a member has changed metadata or if the leader sends JoinGroup.
// The latter allows the leader to trigger rebalances for changes affecting assignment
// which do not affect the member metadata (such as topic metadata changes for the consumer)
updateMemberAndRebalance(group, member, protocols, responseCallback)
} else {
// for followers with no actual change to their metadata, just return group information
// for the current generation which will allow them to issue SyncGroup
responseCallback(JoinGroupResult(
members = Map.empty,
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
}
}
}
if (group.is(PreparingRebalance))
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
}
GroupMetadata对象是一个有PreparingRebalance,AwaitingSync,Stable,Dead,Empty几种状态的状态机,在服务端用于表示当前管理group的状态。
一 第一批consumer加入group
1 由上文可知,新初始化的consumer刚开始的memberid都是JoinGroupRequest.UNKNOWN_MEMBER_ID,所有新成员都进入addMemberAndRebalance方法初始化一个member对象并add进group列表内部,只有一个加入的member才能进入maybePrepareRebalance的同步代码块内调用prepareReblacne方法
private def addMemberAndRebalance(rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
clientId: String,
clientHost: String,
protocolType: String,
protocols: List[(String, Array[Byte])],
group: GroupMetadata,
callback: JoinCallback) = {
// use the client-id with a random id suffix as the member-id
val memberId = clientId + "-" + group.generateMemberIdSuffix
val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs,
sessionTimeoutMs, protocolType, protocols)
member.awaitingJoinCallback = callback
group.add(member)
maybePrepareRebalance(group)
member
}
private def maybePrepareRebalance(group: GroupMetadata) {
group synchronized {
if (group.canRebalance)
prepareRebalance(group)
}
}
prepareReblacne会把group的状态由上述的empty转变为PreparingRebalance,后续的客户端会判断PreparingRebalance同样进入addMemberAndRebalance,这样即使第一个member退出maybePrepareRebalance的synchronized代码块,剩余的member会发现group.canRebalacne返回的都是false直接略过
private def prepareRebalance(group: GroupMetadata) {
// if any members are awaiting sync, cancel their request and have them rejoin
if (group.is(AwaitingSync))
resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)
group.transitionTo(PreparingRebalance)
info("Preparing to restabilize group %s with old generation %s".format(group.groupId, group.generationId))
val rebalanceTimeout = group.rebalanceTimeoutMs
val delayedRebalance = new DelayedJoin(this, group, rebalanceTimeout)
val groupKey = GroupKey(group.groupId)
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}
上述代码里生成了一个DelayJoin,DelayJoin是kafka内部一种有超时时间的Timer.task的实现,会在两种情况下根据情况执行对应操作,一是timeout超时,另一种是满足某种条件后由程序主动运行并注销定时任务,注意这里放的时间是rebalanceTimeout而不是sessiontimeout。
我们看一下joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))和joinPurgatory.checkAndComplete(GroupKey(group.groupId))这两个方法的调用链路。
joinPurgatory.tryCompleteElseWatch->DelayedJoin.safeTryComplete->DelayedJoin.tryComplete->coordinator.tryCompleteJoin
joinPurgatory.checkAndComplete->DelayedOperation.checkAndComplete->DelayedJoin.safeTryComplete->DelayedJoin.tryComplete->coordinator.tryCompleteJoin
所以无论是第一个member结束prepareReblacne还是后续的member在doJoinGroup代码的最后都是去调用一下coordinator.tryCompleteJoin这个方法尝试完成joinGroup的等待
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = {
group synchronized {
if (group.notYetRejoinedMembers.isEmpty)
forceComplete()
else false
}
}
def notYetRejoinedMembers = members.values.filter(_.awaitingJoinCallback == null).toList
tryCompleteJoin的判断逻辑非常简单,GroupMetadata内部缓存的所有member都有对应的注册连接上来(addMemberAndRebalance方法里的member.awaitingJoinCallback = callback会给member的awaitingJoinCallback赋予一个值,值为null的就是有之前的member没有加入进来),如果notYetRejoinedMembers的列表为空,那么客户端就齐了,可以进行reblance分配,如果一直不齐,那么会等到rebalanceTimeout过期后触发强制reblance。
二 heartbeat和session timeout
在reblance过程中可以从下列源码看到heartbeat的delay时间设置的是session.timeout,如果一个旧的consumer死掉后在这个时间内持续没有心跳,那么服务端onMemberFailure会把group内对应的memberid删除并重试一下joinPurgatory.checkAndComplete,如果前次删除后notYetRejoinedMembers变为空后那么joingroup的等待也结束了。
/**
* Complete existing DelayedHeartbeats for the given member and schedule the next one
*/
private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) {
// complete current heartbeat expectation
member.latestHeartbeat = time.milliseconds()
val memberKey = MemberKey(member.groupId, member.memberId)
heartbeatPurgatory.checkAndComplete(memberKey)
// reschedule the next heartbeat expiration deadline
val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs
val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs)
heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey))
}
def onExpireHeartbeat(group: GroupMetadata, member: MemberMetadata, heartbeatDeadline: Long) {
group synchronized {
if (!shouldKeepMemberAlive(member, heartbeatDeadline))
onMemberFailure(group, member)
}
}
private def onMemberFailure(group: GroupMetadata, member: MemberMetadata) {
trace("Member %s in group %s has failed".format(member.memberId, group.groupId))
group.remove(member.memberId)
group.currentState match {
case Dead | Empty =>
case Stable | AwaitingSync => maybePrepareRebalance(group)
case PreparingRebalance => joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
结论,个人在测试过程中发现重启consumer中会有的部分卡顿大部分应该是由于这个notYetRejoinedMembers的列表由于上一次的关掉的consumer的session没有到期造成非空引起的等待。
参考文档
1 http://blog.csdn.net/zhanglh046/article/details/72833073
2 http://www.cnblogs.com/huxi2b/p/6223228.html