引用计数
python中垃圾回收的基本机制是引用计数,程序运行中内存地址的引用是可以被监控和记录的,垃圾回收机制没隔一段时间就会扫描一次内存中的引用,当一个内存空间引用增加一次,python解释器对该内存地址的引用计数就会+1,同样,当引用释放一次,对该内存地址的引用计数就会-1,当解释器检测到某个内存地址的引用为0时,意味着已经没有变量能指向并访问该内存地址了,此时垃圾回收机制就会释放掉该内存地址供其他需求引用。
循环引用
但是仅仅通过引用计数来回收内存是远远不够的,我们来看下面的例子:
ls1 = [222]
ls2 = [333]
ls1.append(ls2)
ls2.append(ls1)
print(ls1)
print(ls2)
此时会打印出什么结果呢?
# 执行结果>>> [222, [333, [...]]] [333, [222, [...]]]
此时得到的是无限循环的列表.....
那么如果我们此时干掉ls1和ls2呢?
del ls1
del ls2
这时候ls1和ls2分别指向的地址会被回收吗?
答案是:不会!
来看下图:
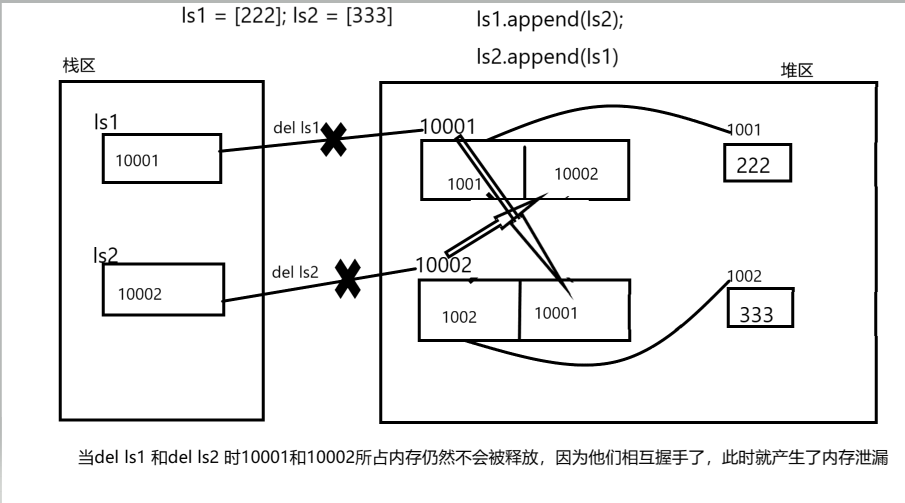
通过上图我们可以看出,地址为10001的内存第二个空间存放了10002,地址10002内存的第二个空间存放了10001,此时它们相互牵手构成循环引用,且已经不能被任何其他变量引用,它们的引用计数都为1已经不能再减少,内存泄漏由此开始....
标记删除
为了解决循环引用产生的内存泄漏的问题,python诞生了标记删除,原理如下:
在程序运行时,python默认在堆区创建两块一样大小的空间,程序只在其中一块空间运行,当当前程序运行的内存使用达到一定阈值时,python会标记所有有引用的空间(简单理解为插旗子),并将其复制一份到另外那块空余的空间,此时将所有引用全部指向复制后的内存空间中对应的地址,然后全部释放掉原程序运行的空间,以此达到释放被泄漏的内存的目的
分代回收
为了提高垃圾回收效率,避免过多浪费cpu资源,python引入了分代回收,请看原理图:
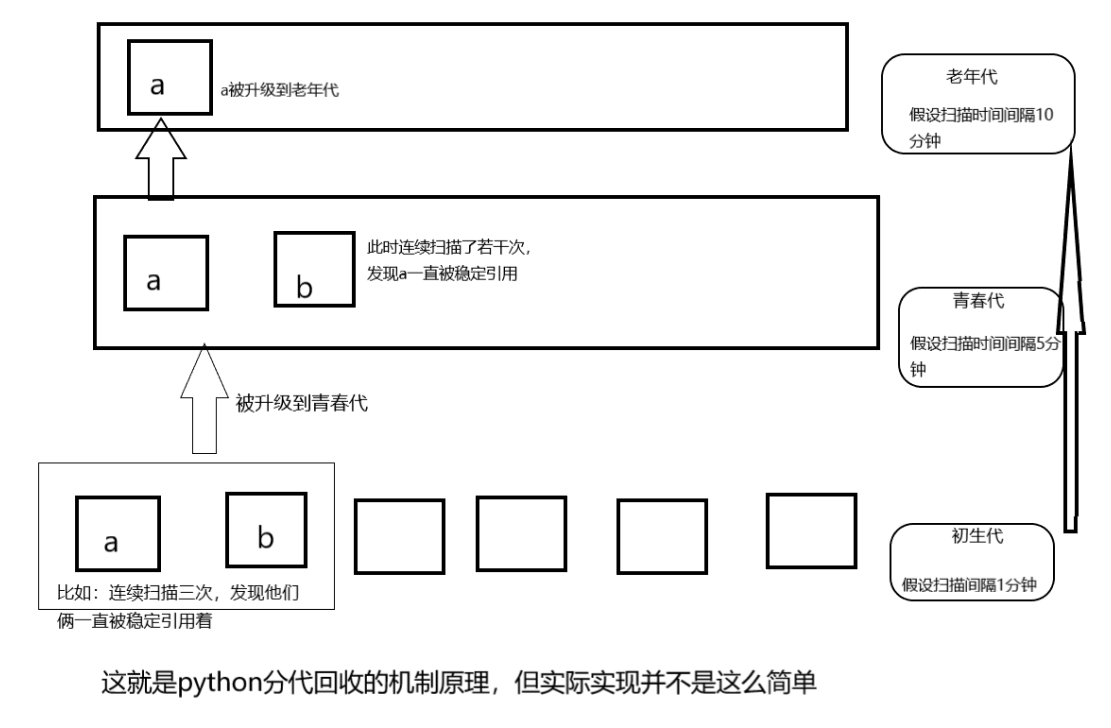
python利用分代回收实现了减少对不必要实时监控的一些全局变量重复扫描,以此达到尽可能少的占用cpu资源、提高执行效率的目的。
到此python垃圾回收机制就总结完了~