1. elasticsearch 命令的基本格式
RESTful接口URL的格式:
http://localhost:9200/<index>/<type>/[<id>]
其中index、type是必须提供的。id是可选的,不提供es会自动生成。index、type将信息进行分层,利于管理。index可以理解为数据库;type理解为数据表;id相当于数据库表中记录的主键,是唯一的。
注:在url网址后面加"?pretty",会让返回结果以工整的方式展示出来,适用所有操作数据类的url。"?"表示引出条件,"pretty"是条件内容。
2. elasticsearch基本的增删改
2.1 elasticSearch增加
向store索引中添加一些书籍
|
1
2
3
4
5
6
7
8
9
|
curl -H "Content-Type: application/json" -XPUT 'http://192.168.187.201:9200/store/books/1?pretty' -d '{ "title": "Elasticsearch: The Definitive Guide", "name" : { "first" : "Zachary", "last" : "Tong" }, "publish_date":"2015-02-06", "price":"49.99"}' |
注:curl是linux下的http请求,-H "Content-Type: application/json"需要添加,否则会报错{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}
加"pretty"

不加"pretty"

加"pretty"与不加"pretty"的区别就是返回结果工整与不工整的差别,其他操作类似。为了使返回结果工整,以下操作都在url后添加"pretty"
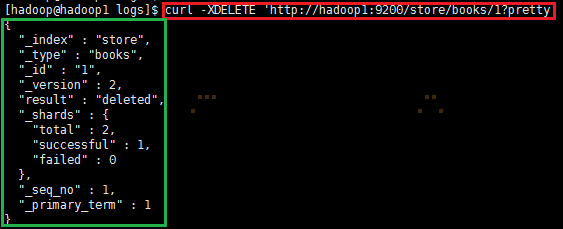
2.2 elasticSearch删除
删除一个文档
|
1
|
curl -XDELETE 'http://hadoop1:9200/store/books/1?pretty' |
2.3 elasticSearch更新(改)
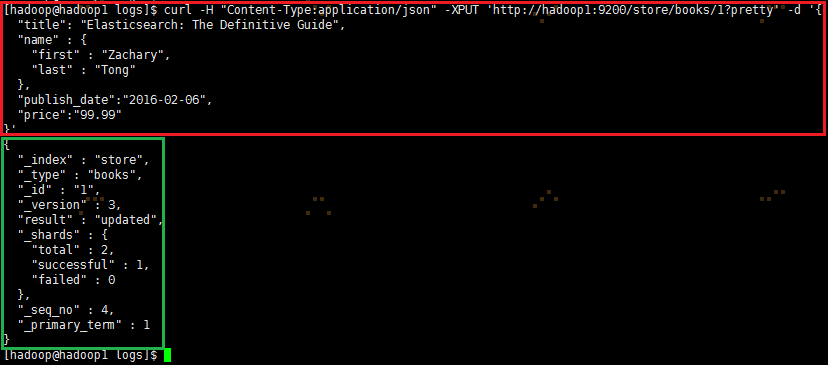
①可以通过覆盖的方式更新
|
1
2
3
4
5
6
7
8
9
|
curl -H "Content-Type:application/json" -XPUT 'http://hadoop1:9200/store/books/1?pretty' -d '{ "title": "Elasticsearch: The Definitive Guide", "name" : { "first" : "Zachary", "last" : "Tong" }, "publish_date":"2016-02-06", "price":"99.99"}' |
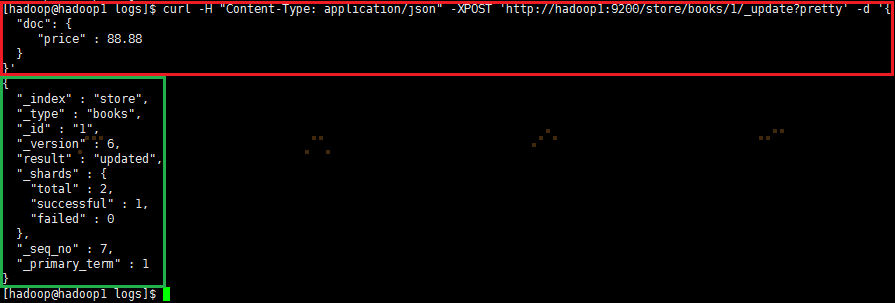
② 通过_update API的方式单独更新你想要更新的
|
1
2
3
4
5
|
curl -H "Content-Type: application/json" -XPOST 'http://hadoop1:9200/store/books/1/_update?pretty' -d '{ "doc": { "price" : 88.88 }}' |
3. elasticSearch查询
elasticSearch查询分三种,一是浏览器查询,二是curl查询,三是请求体查询GET或POS。
注:采用_search的模糊查询(包括bool过滤查询、 嵌套查询、range范围过滤查询等等),url可以不必指定type,只用指定index查询就行,具体例子看"2.1.4 elasticSearch查询 ③query基本匹配查询"节点的具体查询实例
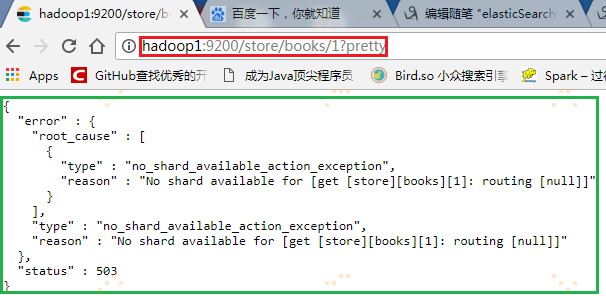
3.1 浏览器查询
通过浏览器IP+网址查询
|
1
|
http://hadoop1:9200/store/books/1?pretty |
3.2 在linux通过curl的方式查询
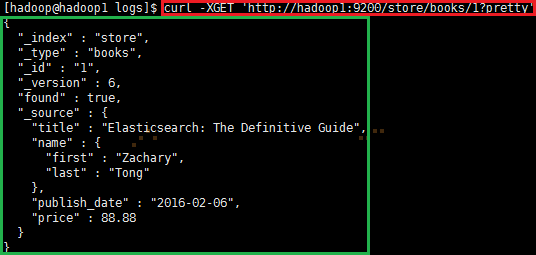
3.2.1 通过ID获得文档信息
|
1
|
curl -XGET 'http://hadoop1:9200/store/books/1?pretty' |
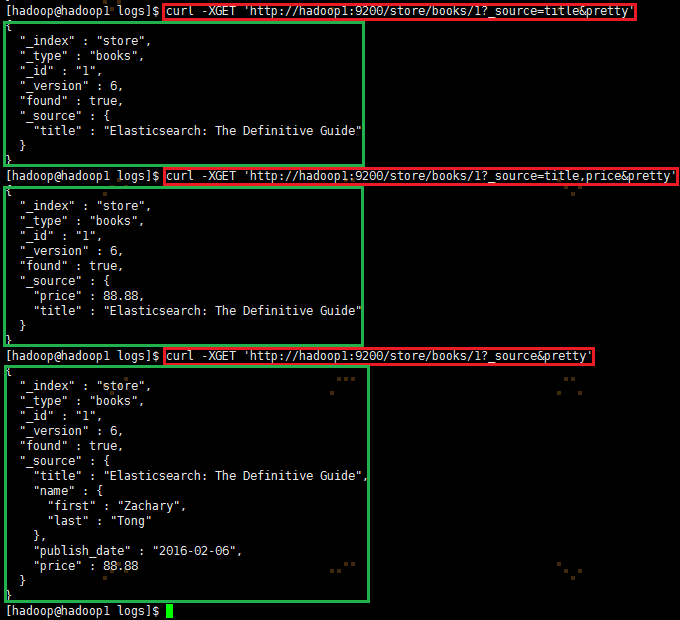
3.2.2 通过_source获取指定的字段
|
1
2
3
|
curl -XGET 'http://hadoop1:9200/store/books/1?_source=title&pretty'curl -XGET 'http://hadoop1:9200/store/books/1?_source=title,price&pretty'curl -XGET 'http://hadoop1:9200/store/books/1?_source&pretty' |
3.2.3 query基本匹配查询
查询数据前,可以批量导入1000条数据集到elasticsearch里,具体参考"4 elasticSearch批处理命令 4.1 导入数据集"节点,以便数据查询方便。
① "q=*"表示匹配索引中所有的数据,一般默认只返回前10条数据。
|
1
2
3
4
5
6
7
|
curl 'hadoop1:9200/bank/_search?q=*&pretty'#等价于:curl -H "Content-Type:applicatin/json" -XPOST 'localhost:9200/bank/_search?pretty' -d '{ "query": { "match_all": {} }}' |
② 匹配所有数据,但只返回1个
|
1
2
3
4
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match_all": {}}, "size": 1}' |
注:如果size不指定,则默认返回10条数据。
③ 返回从11到20的数据(索引下标从0开始)
|
1
2
3
4
5
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {“match_all”: {}}, "from": 10, "size": 10} |
④ 匹配所有的索引中的数据,按照balance字段降序排序,并且返回前10条(如果不指定size,默认最多返回10条)
|
1
2
3
4
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match_all": {}}, "sort": {"balance":{"order": "desc"}}}' |
⑤ 返回特定的字段(account_number balance) ,与②通过_source获取指定的字段类似
|
1
2
3
4
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match_all": {}}, "_source": ["account_number", "balance"]}' |
⑥ 返回account_humber为20的数据
|
1
2
3
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match": {"account_number":20}}}' |
⑦ 返回address中包含mill的所有数据
|
1
2
3
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match":{"address": "mill"}}}' |
⑧ 返回地址中包含mill或者lane的所有数据
|
1
2
3
|
curl -H "Content_Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ “query": {"match": {"address": "mill lane"}}}' |
⑨ 与第8不同,多匹配(match_phrase是短语匹配),返回地址中包含短语"mill lane"的所有数据
|
1
2
3
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": {"match_phrase": {"address": "mill lane"}}}' |
3.2.4 bool过滤查询,可以做组合过滤查询、嵌套查询等
SELECT * FROM books WHERE (price = 35.99 OR price = 99.99) AND (publish_date != "2016-02-06")
类似的,Elasticsearch也有 and, or, not这样的组合条件的查询方式,格式如下:
|
1
2
3
4
5
6
7
8
|
{ ”bool“ : { "filter": [], "must" : [], "should": [], "must_not": [] }} |
说明:
filter:过滤
must:条件必须满足,相当于and
should:条件可以满足也可以不满足,相当于or
must_not:条件不需要满足,相当于not
3.2.4.1 filter查询
①filter指定单个值
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# SELECT * FROM books WHERE price = 35.99# filtered 查询价格是35.99的curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{ "query" : { "bool" : { "must" : { "match_all" : {} }, "filter" : { "term" : { "price" : 35.99 } } } }}' |
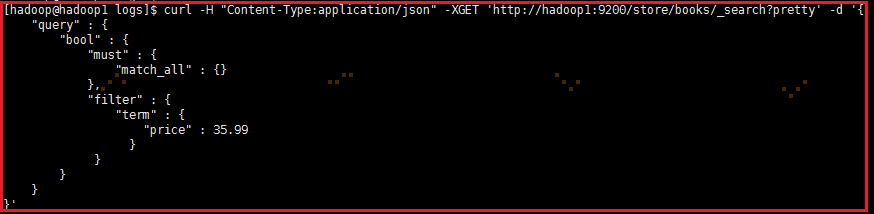
注:带有key-value键值对的都需要加 -H “Content-Type: application/json”
②filter指定多个值
|
1
2
3
4
5
6
7
8
9
10
11
|
curl -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{ "query" : { "bool" : { "filter" : { "terms" : { "price" : [35.99, 99.99] } } } }}' |

3.2.4.2 must、should、must_not查询
①must、should、must_not与term结合使用:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{ "query" : { "bool" : { "should" : [ { "term" : {"price" : 35.99}}, { "term" : {"price" : 99.99}} ], "must_not" : { "term" : {"publish_date" : "2016-06-06"} } } }}' |
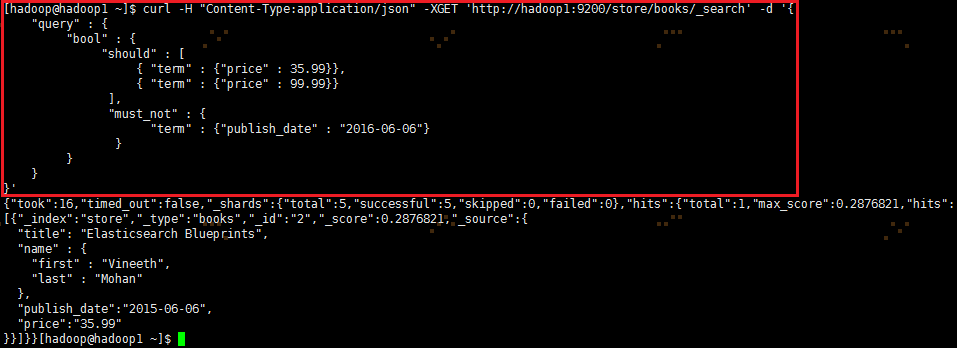
②must、should、must_not与match结合使用
bool表示查询列表中只要有任何一个为真则认为匹配:
|
1
2
3
4
5
6
7
8
9
10
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": { "bool": { "must_not": [ {"match": {"address": "mill"}}, {"match": {"address": "lane"}} ] } }}' |
返回age年龄大于40岁、state不是ID的所有数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": { "bool": { "must": [ {"match": {"age": "40"}} ], "must_not": [ {"match": {"state": "ID"}} ] } }}' |
3.2.4.3 bool嵌套查询
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 嵌套查询# SELECT * FROM books WHERE price = 35.99 OR ( publish_date = "2016-02-06" AND price = 99.99 )curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{ "query" : { "bool" : { "should" : [ { "term" : {"price" : 35.99 }}, { "bool" : { "must" : [ { "term" : {"publish_date" : "2016-06-06"}}, { "term" : {"price" : 99.99}} ] } } ] } }}' |
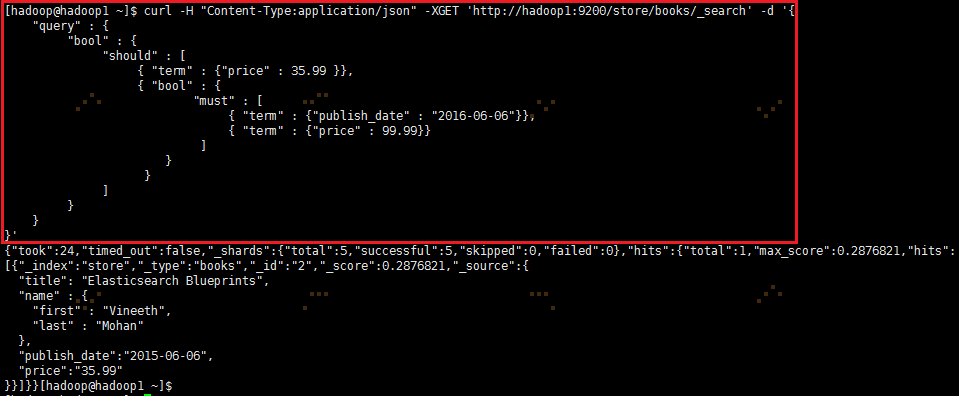
3.2.4.4 filter的range范围过滤查询
第一个示例,查找price价钱大于20的数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# SELECT * FROM books WHERE price >= 20 AND price < 100# gt : > 大于# lt : < 小于# gte : >= 大于等于# lte : <= 小于等于curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{ "query" : { "bool" : { "filter" : { "range" : { "price" : { "gt" : 20.0, "boost" : 4.0 } } } } }}' |
注:boost:设置boost查询的值,默认1.0

第二个示例,使用布尔查询返回balance在20000到30000之间的所有数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "query": { "bool": { "must": {"match_all": {}}, "filter": { "range": { "balance": { "gte": 20000, "lte": 30000 } } } } }}' |
3.2.4 elasticSearch聚合查询
第一个示例,将所有的数据按照state分组(group),然后按照分组记录数从大到小排序(默认降序),返回前十条(默认)
|
1
2
3
4
5
6
7
8
9
10
|
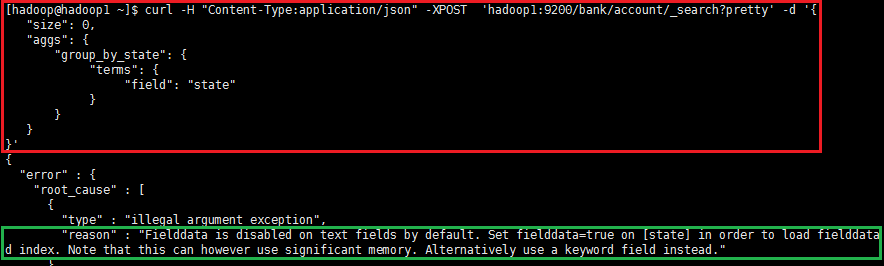
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state" } } }}' |
可能遇到的问题:elasticsearch 进行排序的时候,我们一般都会排序数字、日期,而文本排序则会报错:Fielddata is disabled on text fields by default. Set fielddata=true on [state] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.如:
解决方案:5.x后对排序,聚合这些操作,用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,官方解释在此fielddata。聚合前执行如下操作,用以开启fielddata:
|
1
2
3
4
5
6
7
8
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_mapping/account?pretty' -d '{"properties": { "state": { "type": "text", "fielddata": true } } }' |
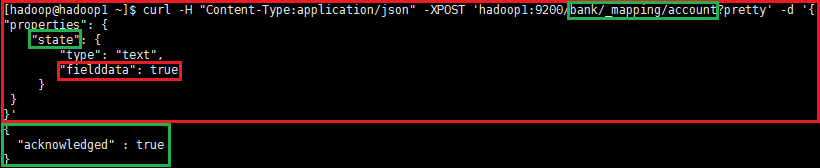
说明:bank为index,_mapping为映射,account为type,这三个要素为必须,”state“为聚合"group_by_state"操作的对象字段
聚合查询成功示例:
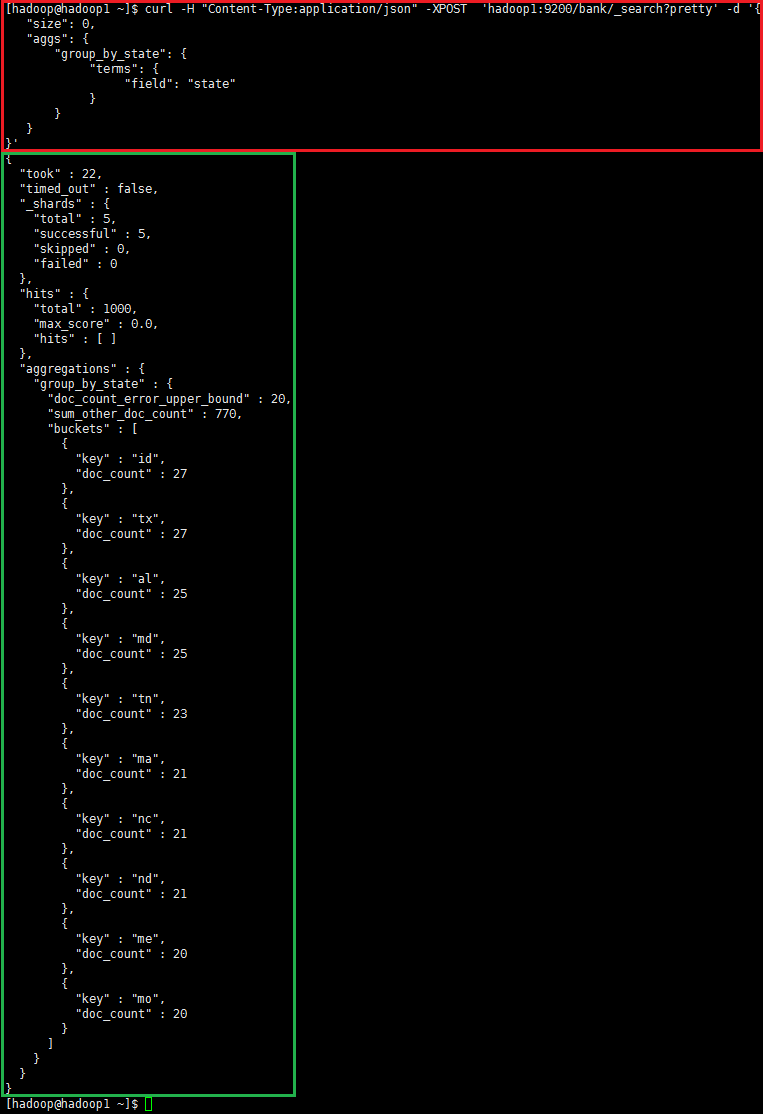
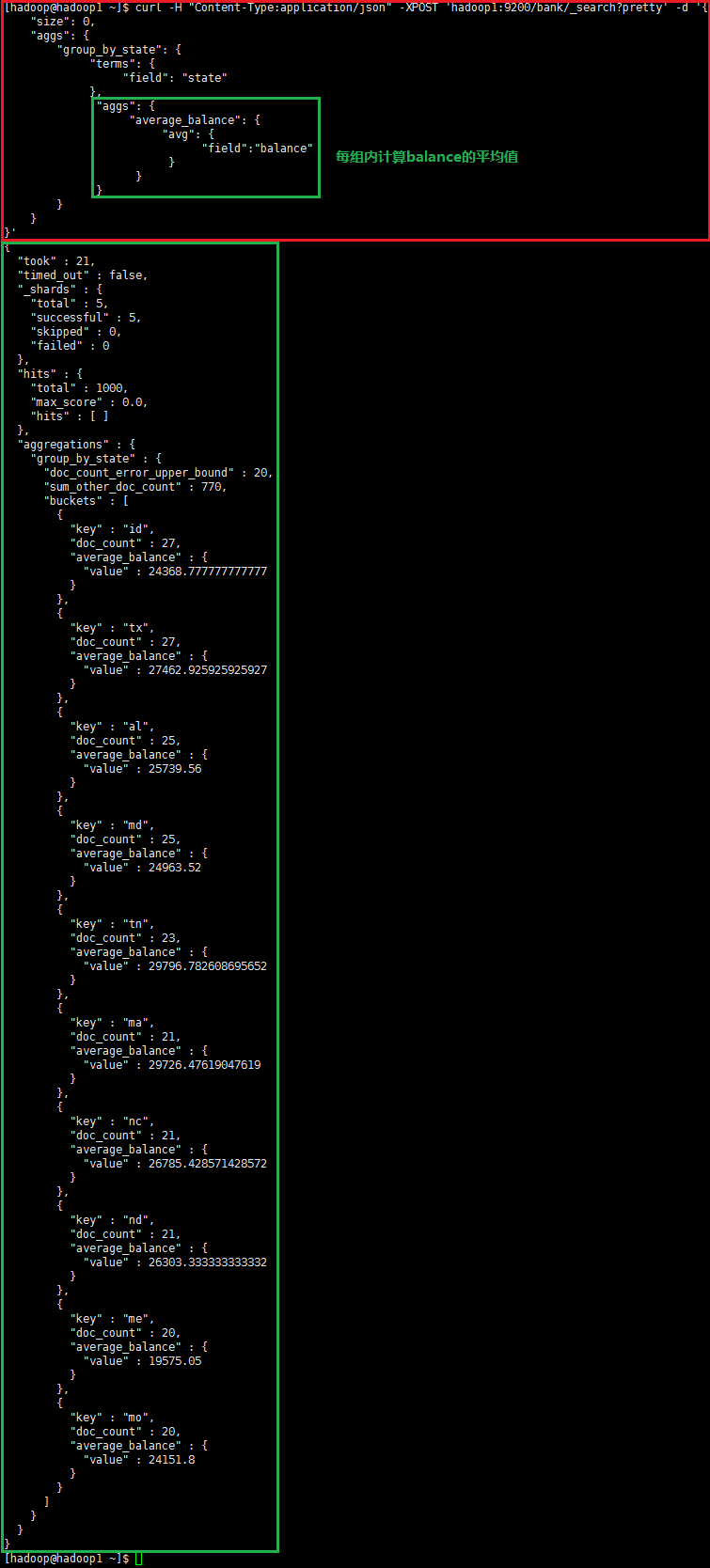
第二个示例,将所有的数据按照state分组(group),降序排序,计算每组balance的平均值并返回(默认)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{ "size": 0, "aggs": { "group_by_state": { "terms": { "field": "state" }, "aggs": { "average_balance": { "avg": { "field":"balance" } } } } }}' |
4. elasticSearch批处理命令
4.1 导入数据集
你可以点击这里下载示例数据集:accounts.json
导入示例数据集:
|
1
2
|
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/account/_bulk?pretty' --data-binary "@accounts.json"curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/account/_bulk?pretty' --data-binary "@/home/hadoop/accounts.json" |
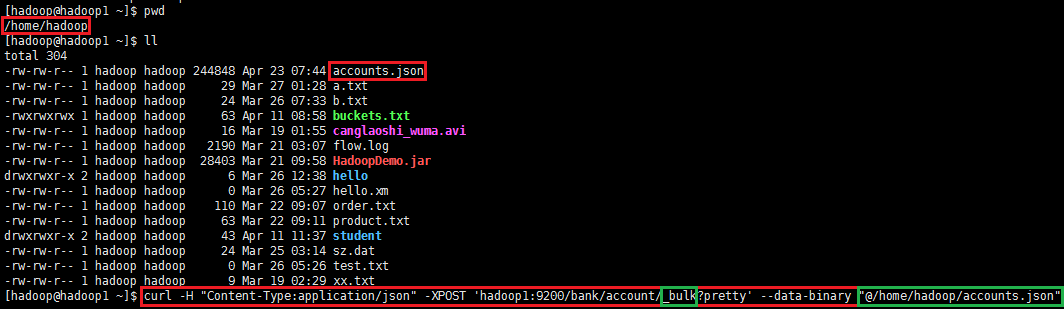
注:_bulk表示批量处理,"@accounts.json"或者"@/home/hadoop/accounts.json"可以用相对路径或者绝对路径表示。
查看accounts.json导入情况,使用 curl 'hadoop1:9200/_cat/indices?v'

可以看到已经成功导入1000条数据记录
4.2 批量创建索引
5. elasticSearch其他常用命令
注:url后面的"v"表示 verbose 的意思,这样可以更可读(有表头,有对齐),如果不加v,不会显示表头
5.1. 查看所有index索引,输入命令 curl 'hadoop1:9200/_cat/indices?v'

说明:index:索引为store,pri:5个私有的分片,rep:1个副本,docs.count:store索引里面有2个文档(即里面有2条数据记录),docs.deleted:删除了0条记录,store.size:数据存储总大小(包括副本),pri.store.size:分片数据存储的大小。
不加v,不会显示表头,可读性差

5.2. 检测集群是否健康,确保9200端口号可用 curl 'hadoop1:9200/_cat/health?v'

5.3. 获取集群的节点列表 curl 'hadoop1:9200/_cat/nodes?v'

转载自https://www.cnblogs.com/swordfall/p/8923087.html