一、入门
1、简介
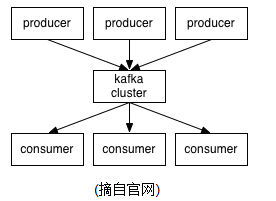
Kafka是一种分布式的,基于发布/订阅的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
2、Topics/logs
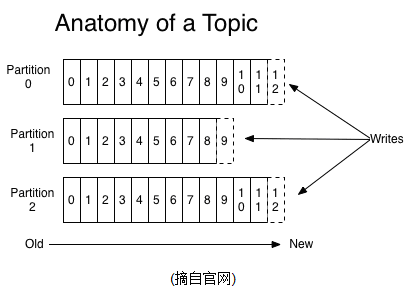
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值..(offset将会保存在zookeeper中,参见下文)
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
3、Distribution
一个Topic的多个partitions,被分布在kafka集群中的多个server上();每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
Consumers
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.

Guarantees
1) 发送到partitions中的消息将会按照它接收的顺序追加到日志中
2) 对于消费者而言,它们消费消息的顺序和日志中消息顺序一致.
3) 如果Topic的"replicationfactor"为N,那么允许N-1个kafka实例失效.
- Producer
负责发布消息到Kafka broker - Consumer
消费消息。每个consumer属于一个特定的consuer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
Broker
物理概念,指服务于Kafka集群的一个服务器(node)。集群包含一个或多个服务器。
topic
用于保证Producer以及Consumer能够通过该标示进行对接。每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。
partition
Topic的一个子概念,一个topic可具有多个partition,但Partition一定属于一个topic。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
值得注意的是:
- 在实现上都是以每个Partition为基本实现单元的。
- 消费时,每个消费线程最多只能使用一个partition。
- 一个topic中partition的数量,就是每个user group中消费该topic的最大并行度数量。
User group
为了便于实现MQ中的多播,重复消费等引入的概念。如果ConsumerA以及ConsumerB同在一个UserGroup,那么ConsumerA消费的数据ConsumerB就无法消费了。
即:所有usergroup中的consumer使用一套offset。
Offset
Offset专指Partition以及User Group而言,记录某个user group在某个partiton中当前已经消费到达的位置。
总结
Kafka使用了Topic以及Partition的概念。其中Partition隶属于Topic,即topic1可以具有多个partition。而Partition则是Consumer消费的基本单元,即topic1有几个partition,那么最多就可以有多少个consumer同时在一个User Group里消费这个topic。而Offset则是记录了UserGroup在每个partiton中的偏移值。