- 什么是MAPREDUCE :
- MapReduce 八个字的核心的思想分而治之,
- Mapreduce简单的工作原理:
- mapredue 有maptask、reducetask组成
- 一个切片一个mapreduce,
- reduceTask 的默认是一个,可以设置多个
- 设置过程job.setNumReduceTask(3);
- reduce 分区规则:
- 根据可以的(value.hashcode()%reduce_num) 得到分区号。
- 好处:同一个key发给同一个reduce ,最后所有的reduce合并就会得到最终结果。
- 在同一个map_reduce阶段,一个过程仅可出现一次。
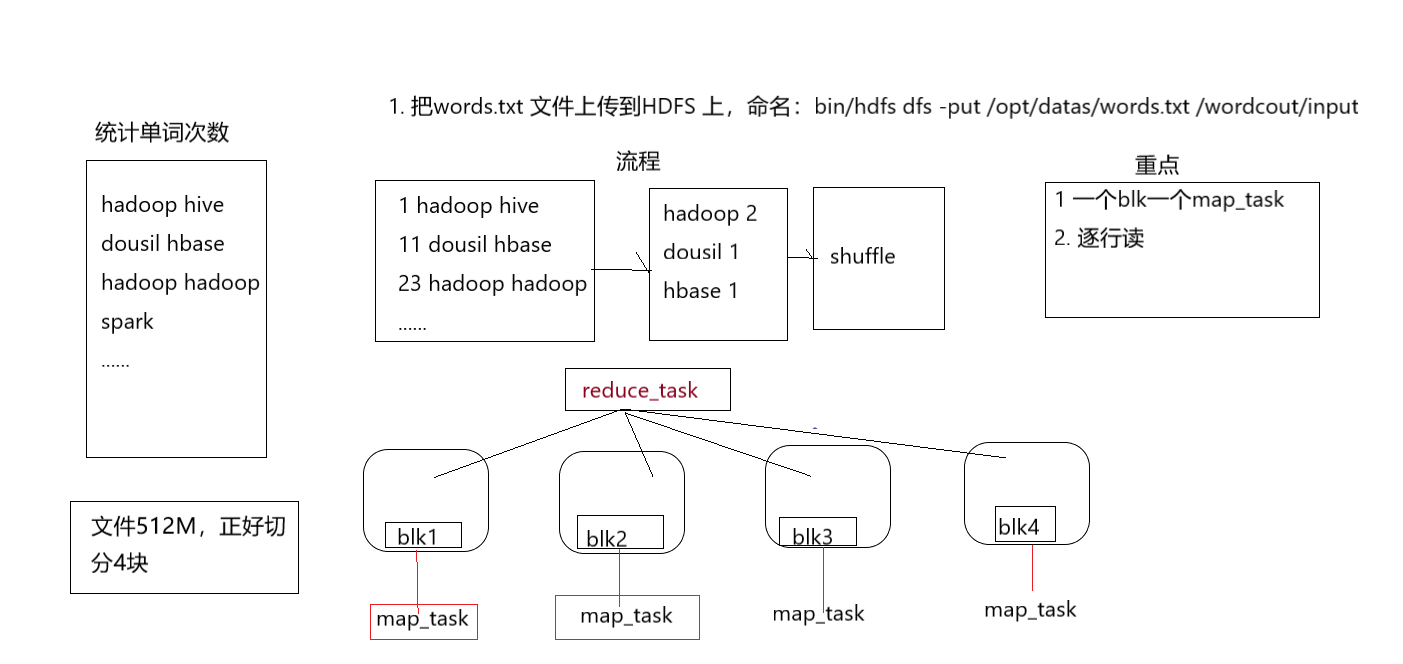
- 创建一个简单的MapReduce程序。
- 重写map方法
public class MyMap extends Mapper<LongWritable, Text,Text,IntWritable>{
private Text outputKey = null;
private IntWritable outputValue = null;
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
outputKey = new Text();
outputValue = new IntWritable(1);
for(String word:words){
outputKey.set(word);
context.write(outputKey,outputValue);
}
}
}
重写reducer方法
package com.dousil.hadoop.demo.MyReduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count =0;
for(IntWritable value:values){
count +=value.get();
}
context.write(key,new IntWritable(count));
}
}
- 组装代码package com.dousil.hadoop.demo.MyWordCounter
import com.dousil.hadoop.demo.MyMap.MyMap;
import com.dousil.hadoop.demo.MyReduce.MyReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileOutputStream;
import java.io.IOException;
public class MyWordCounter {
public static void main(String args[]) throws IOException {
Configuration conf = new Configuration() ;
Job job = Job.getInstance(conf);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//设置自己Mapper类
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce类
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//job提交到yarn去运行
boolean result =false;
try{
result = job.waitForCompletion(true);//true,和false控制台是否打印调试信息
}catch(Exception e){
e.printStackTrace();
}
System.out.println(result);
}
}