-
kafaka初识
-
产生的背景:
- 问题:
- 两个模块A、B .A生产消息,B消费消息,当A的速度 大于B的速度,A模块产生的数据的阻塞,有剩余,对数据得处理有一定的影响。
- 解决方案:
- 新加模块C 。a发数据c,C将数据发给B。
 速度
速度
- 定义:
- 分布式的消息订阅系统。
- 优点:高可扩展,高容错,分布式。
- 缺点:复杂,消息错乱,重复消息。
- 分布式,可分区,可复制的
- 分布式的消息订阅系统。
- 使用地方:
- 消息系统,日志收集系统。实时的,可以做元数据的监控,
- 任何脱离业务的框架都是耍流氓
- 多了一个组件,复杂,
- 消息的路路径长,时间长,
- 可靠性重复性矛盾,
- 上游无法知道下游的执行结果,这一点是致命的。 登陆页面,不可以用该功能。调用实时的依赖执行结果的场景,最好使用调用而不用mq.
- 使用的场景,数据驱动的任务依赖。上游不关心下游的执行结果。
- 使用mq最好的解决的方案是实现上下级的解耦。
- 不适合的场景,上游实时关注下游的执行结果。
- 他的网址:
- kafka.apache.org /082/docomentaton.html kafaka当前最好使用0.8
- kakaf基本术语

- Message :消息 :offset,key,value,timestamp
- Broker:代理:物理储在的一个进程。一台服务器,可以部署多个,一般一个。
- topic : 他是一个主题,是一个消息类型,是一个消息类型。
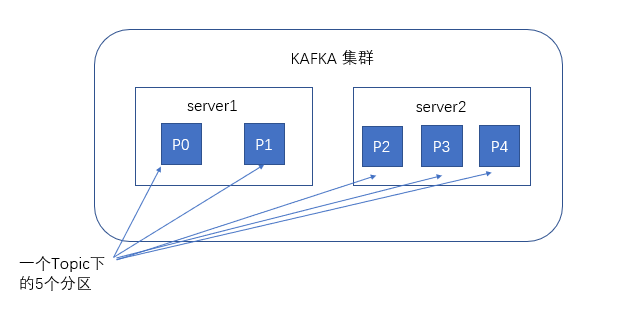
- Partation:一个topic包含多个分区,produce发送数据到topic的数据根据key的不同发送到不同的partition,分区特点:1.kafaka时间排序,2 数据不可变动
- producter:生产者,在发送消息之前会对消息分配,及topic,
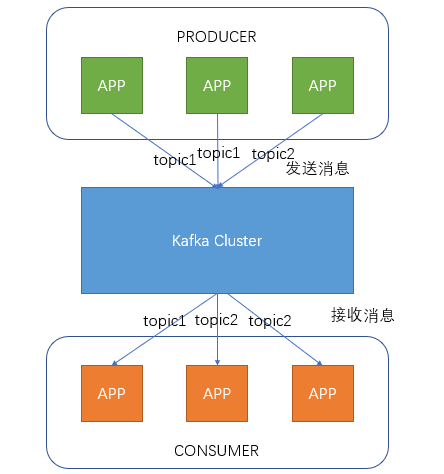
- consumer:消费者
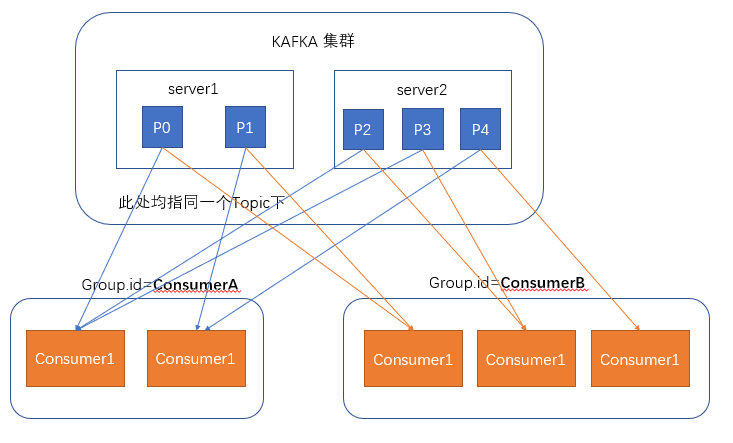
- consumergroup:消费者组
 kafka 1.0.1可以作为消息系统,还可以作为流式数据的处理和存储平台。支持流式的处理。可以存储数据。可以将kafka持久到外部,从外部都进来,zhici在已有的基础上新增了两个功能:
kafka 1.0.1可以作为消息系统,还可以作为流式数据的处理和存储平台。支持流式的处理。可以存储数据。可以将kafka持久到外部,从外部都进来,zhici在已有的基础上新增了两个功能:- Streams、流式的处理
- Connector、可以将数据持久化,