1. requests库安装
推荐使用anaconda,自带
2. requests使用
import requests r = requests.get("http://www.baidu.com") print(r.status_code) r.encoding = 'utf-8' print(r.text)

2.1 Requests库的get()方法
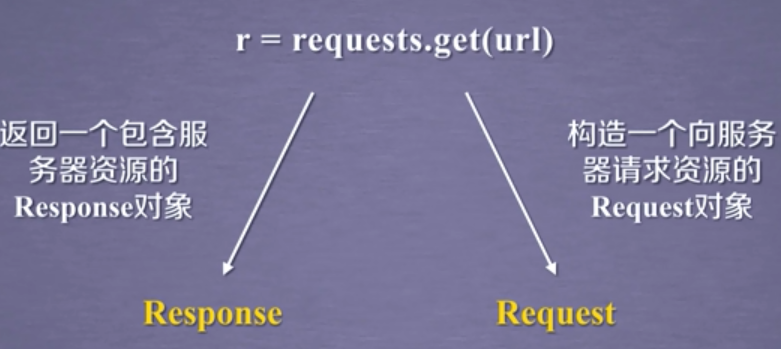



2.2 Response对象
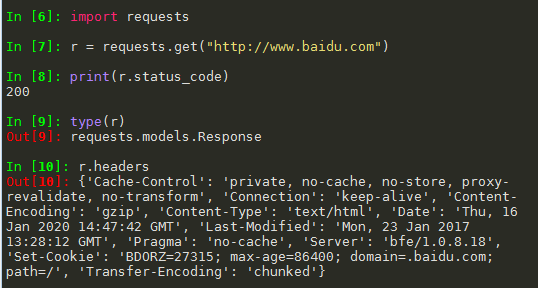
(1)判断请求是否成功
assert response.status_code == 200



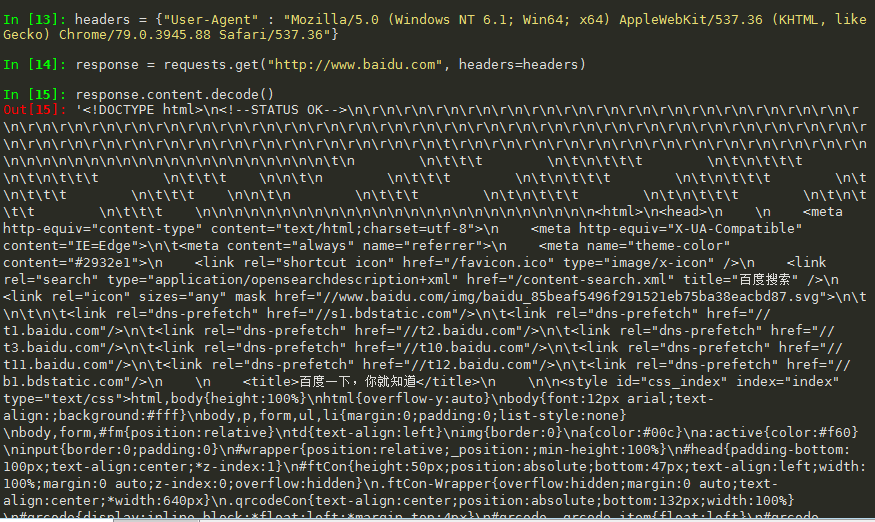
2.3 requests模块发送带headers的请求
(1)如果没有模拟浏览器,对方服务器只会返回一小部分内容
(2)为了模拟浏览器,所以需要发送带header请求

2.4 requests发送带参数的请求

(1)url编码格式
https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3Dpython&logid=8596791949931086675&signature=aa5a72defcf92845bdcdac2e55e0aab3×tamp=1579276087
解码:
https://www.baidu.com/s?wd=python&logid=8596791949931086675&signature=aa5a72defcf92845bdcdac2e55e0aab3×tamp=1579276087
(2)字符串格式化另一种方式
import requests headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"} ps = {"wd":"python"} url_tmp = "https://www.baidu.com/s?wd={}".format("python") r = requests.get(url=url_tmp, headers=headers) print(r.status_code) print(r.request.url)
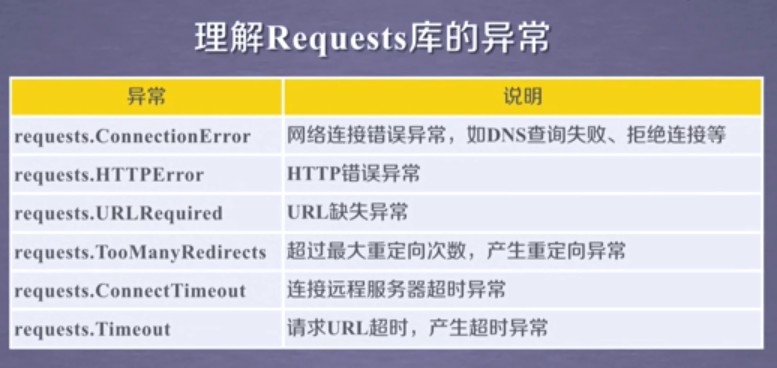
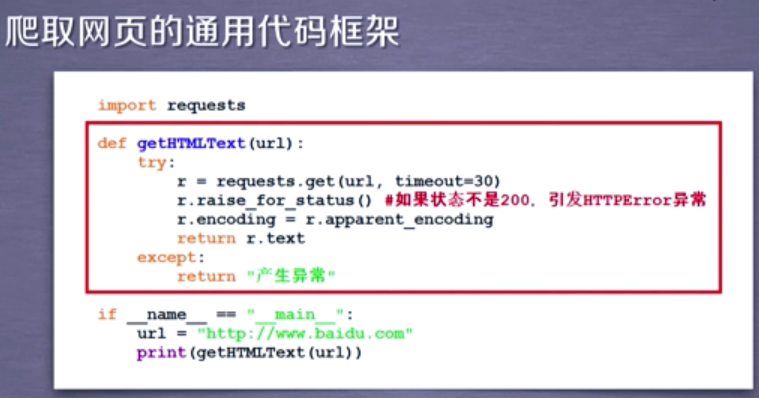
3. 通用代码框架









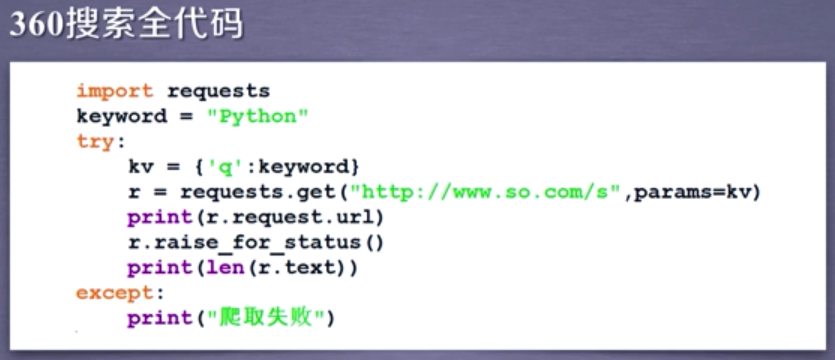
4. 几个例子

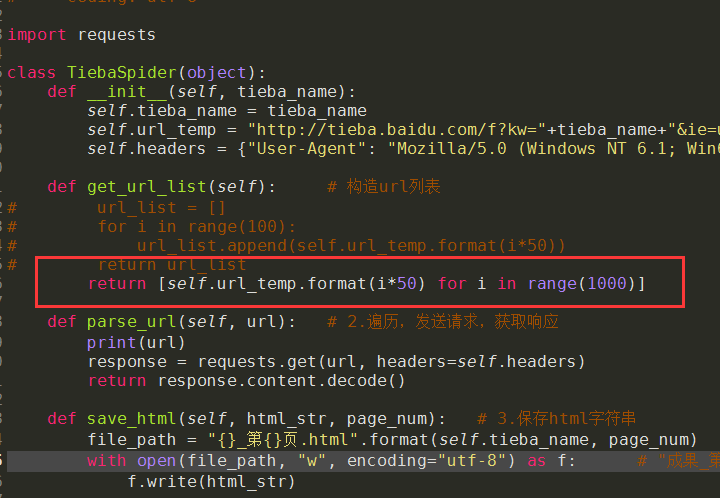
5. 实例:贴吧爬虫
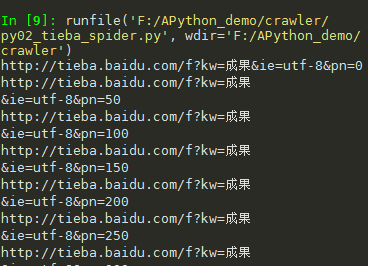
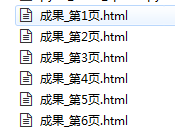
# -*- coding: utf-8 -*- import requests class TiebaSpider(object): def __init__(self, tieba_name): self.tieba_name = tieba_name self.url_temp = "http://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}" self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"} def get_url_list(self): # 构造url列表 url_list = [] for i in range(100): url_list.append(self.url_temp.format(i*50)) return url_list def parse_url(self, url): # 2.遍历,发送请求,获取响应 print(url) response = requests.get(url, headers=self.headers) return response.content.decode() def save_html(self, html_str, page_num): # 3.保存html字符串 file_path = "{}_第{}页.html".format(self.tieba_name, page_num) with open(file_path, "w", encoding="utf-8") as f: # "成果_第1页.html" f.write(html_str) def run(self): # 实现主要逻辑 # 1.构造url列表 url_list = self.get_url_list() # 2.遍历,发送请求,获取响应 for url in url_list: html_str = self.parse_url(url) # 3.保存 page_num = url_list.index(url) + 1 # 页码数 self.save_html(html_str, page_num) if __name__ == '__main__': tieba_spider = TiebaSpider("成果") tieba_spider.run()

(1)补充:列表推导式

扁平胜于嵌套