Transformer模型(文本分类仅用到Encoder部分):
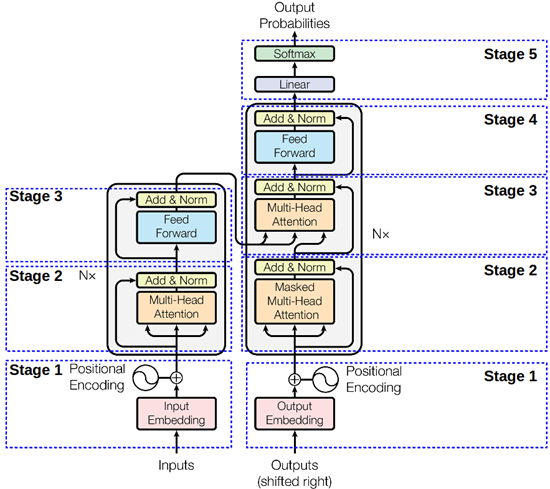

1. 数据预处理
和上一个博客https://www.cnblogs.com/douzujun/p/13511237.html中的数据和预处理都一致。
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
from torchtext import data
import math
import time
from torch.autograd import Variable
import copy
import random
SEED = 126
BATCH_SIZE = 128
EMBEDDING_DIM = 100 # 词向量维度
LEARNING_RATE = 1e-3 # 学习率
# 设置device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
# 两个Field对象定义字段的处理方法(文本字段、标签字段)
TEXT = data.Field(tokenize=lambda x: x.split(), batch_first=True, lower=True) # 是否Batch_first. 默认值: False.
LABEL = data.LabelField(dtype=torch.float)
# get_dataset: 返回Dataset所需的 text 和 label
def get_dataset(corpus_path, text_field, label_field):
fields = [('text', text_field), ('label', label_field)] # torchtext文本配对关系
examples = []
with open(corpus_path) as f:
li = []
while True:
content = f.readline().replace('
', '')
if not content: # 为空行,表示取完一次数据(一次的数据保存在li中)
if not li:
break
label = li[0][10]
text = li[1][6:-7]
examples.append(data.Example.fromlist([text, label], fields=fields))
li = []
else:
li.append(content)
return examples, fields
# 得到构建Dataset所需的examples 和 fields
train_examples, train_fileds = get_dataset('./corpus/trains.txt', TEXT, LABEL)
dev_examples, dev_fields = get_dataset('./corpus/dev.txt', TEXT, LABEL)
test_examples, test_fields = get_dataset('./corpus/tests.txt', TEXT, LABEL)
# 构建Dataset数据集
train_data = data.Dataset(train_examples, train_fileds)
dev_data = data.Dataset(dev_examples, dev_fields)
test_data = data.Dataset(test_examples, test_fields)
# for t in test_data:
# print(t.text, t.label)
print('len of train data:', len(train_data)) # 1000
print('len of dev data:', len(dev_data)) # 200
print('len of test data:', len(test_data)) # 300
# 创建vocabulary
TEXT.build_vocab(train_data, max_size=5000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
print(len(TEXT.vocab)) # 3287
print(TEXT.vocab.itos[:12]) # ['<unk>', '<pad>', 'the', 'and', 'a', 'to', 'is', 'was', 'i', 'of', 'for', 'in']
print(TEXT.vocab.stoi['love']) # 129
# print(TEXT.vocab.stoi) # defaultdict {'<unk>': 0, '<pad>': 1, ....}
# 创建iterators, 每个iteration都会返回一个batch的example
train_iterator, dev_iterator, test_iterator = data.BucketIterator.splits(
(train_data, dev_data, test_data),
batch_size=BATCH_SIZE,
device=device,
sort = False)
len of train data: 1000
len of dev data: 200
len of test data: 300
3287
['<unk>', '<pad>', 'the', 'and', 'a', 'to', 'is', 'was', 'i', 'of', 'for', 'in']
129
2. 定义模型
2.1 Embedding
class InputEmbeddings(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(InputEmbeddings, self).__init__()
self.embedding_dim = embedding_dim
self.embed = nn.Embedding(vocab_size, embedding_dim)
def forward(self, x):
return self.embed(x) * math.sqrt(self.embedding_dim)
2.2 PositionalEncoding

class PositionalEncoding(nn.Module):
def __init__(self, embedding_dim, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, embedding_dim)
position = torch.arange(0., max_len).unsqueeze(1) # [max_len, 1], 位置编码
div_term = torch.exp(torch.arange(0., embedding_dim, 2) * -(math.log(10000.0) / embedding_dim))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 增加维度
print(pe.shape)
self.register_buffer('pe', pe) # 内存中定一个常量,模型保存和加载的时候,可以写入和读出
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) # Embedding + PositionalEncoding
return self.dropout(x)
2.3 MultiHeadAttention
self-attention-->建立一个全连接的网络结构
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def attention(query, key, value, mask=None, dropout=None): # q,k,v: [batch, h, seq_len, d_k]
d_k = query.size(-1) # query的维度
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # 打分机制 [batch, h, seq_len, seq_len]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # mask==0的内容填充-1e9, 使计算softmax时概率接近0
p_atten = F.softmax(scores, dim = -1) # 对最后一个维度归一化得分, [batch, h, seq_len, seq_len]
if dropout is not None:
p_atten = dropout(p_atten)
return torch.matmul(p_atten, value), p_atten # [batch, h, seq_len, d_k]
# 建立一个全连接的网络结构
class MultiHeadedAttention(nn.Module):
def __init__(self, h, embedding_dim, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert embedding_dim % h == 0
self.d_k = embedding_dim // h # 将 embedding_dim 分割成 h份 后的维度
self.h = h # h 指的是 head数量
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
self.dropout = nn.Dropout(p = dropout)
def forward(self, query, key, value, mask = None): # q,k,v: [batch, seq_len, embedding_dim]
if mask is not None:
mask = mask.unsqueeze(1) # [batch, seq_len, 1]
nbatches = query.size(0)
# 1. Do all the linear projections(线性预测) in batch from embeddding_dim => h x d_k
# [batch, seq_len, h, d_k] -> [batch, h, seq_len, d_k]
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2. Apply attention on all the projected vectors in batch.
# atten:[batch, h, seq_len, d_k], p_atten: [batch, h, seq_len, seq_len]
attn, p_atten = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3. "Concat" using a view and apply a final linear.
# [batch, h, seq_len, d_k]->[batch, seq_len, embedding_dim]
attn = attn.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](attn)
2.4 MyTransformerModel
class MyTransformerModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, p_drop, h, output_size):
super(MyTransformerModel, self).__init__()
self.drop = nn.Dropout(p_drop)
# Embeddings,
self.embeddings = InputEmbeddings(vocab_size=vocab_size, embedding_dim=embedding_dim)
# H: [e_x1 + p_1, e_x2 + p_2, ....]
self.position = PositionalEncoding(embedding_dim, p_drop)
# Multi-Head Attention
self.atten = MultiHeadedAttention(h, embedding_dim) # self-attention-->建立一个全连接的网络结构
# 层归一化(LayerNorm)
self.norm = nn.LayerNorm(embedding_dim)
# Feed Forward
self.linear = nn.Linear(embedding_dim, output_size)
# 初始化参数
self.init_weights()
def init_weights(self):
init_range = 0.1
self.linear.bias.data.zero_()
self.linear.weight.data.uniform_(-init_range, init_range)
def forward(self, inputs, mask): # 维度均为: [batch, seq_len]
embeded = self.embeddings(inputs) # 1. InputEmbedding [batch, seq_len, embedding_dim]
# print(embeded.shape) # torch.Size([36, 104, 100])
embeded = self.position(embeded) # 2. PosionalEncoding [batch, seq_len, embedding_dim]
# print(embeded.shape) # torch.Size([36, 104, 100])
mask = mask.unsqueeze(2) # [batch, seq_len, 1]
# 3.1 MultiHeadedAttention [batch, seq_len. embedding_dim]
inp_atten = self.atten(embeded, embeded, embeded, mask)
# 3.2 LayerNorm [batch, seq_len, embedding_dim]
inp_atten = self.norm(inp_atten + embeded)
# print(inp_atten.shape) # torch.Size([36, 104, 100])
# 4. Masked, [batch, seq_len, embedding_dim]
inp_atten = inp_atten * mask # torch.Size([36, 104, 100])
# print(inp_atten.sum(1).shape, mask.sum(1).shape) # [batch, emb_dim], [batch, 1]
b_avg = inp_atten.sum(1) / (mask.sum(1) + 1e-5) # [batch, embedding_dim]
return self.linear(b_avg).squeeze() # [batch, 1] -> [batch]
使用模型,使用预训练过的embedding来替换随机初始化,定义优化器、损失函数。
model = MyTransformerModel(len(TEXT.vocab), EMBEDDING_DIM, p_drop=0.5, h=2, output_size=1)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape) #torch.Size([3287, 100])
model.embeddings.embed.weight.data.copy_(pretrained_embedding) #embeddings是MyTransformerModel的参数, embed是InputEmbedding的参数
print('embedding layer inited.')
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=0.001)
criteon = nn.BCEWithLogitsLoss()
pretrained_embedding: torch.Size([3287, 100])
embedding layer inited.
3. 训练、评估函数
常规套路:计算准确率、训练函数、评估函数、打印模型表现、用保存的模型参数预测测试数据。
#计算准确率
def binary_acc(preds, y):
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
#训练函数
def train(model, iterator, optimizer, criteon):
avg_loss = []
avg_acc = []
model.train() #表示进入训练模式
for i, batch in enumerate(iterator):
mask = 1 - (batch.text == TEXT.vocab.stoi['<pad>']).float() #[batch, seq_len]增加了这句,其他都一样
pred = model(batch.text, mask)
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item() #计算每个batch的准确率
avg_loss.append(loss.item())
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_acc = np.array(avg_acc).mean()
avg_loss = np.array(avg_loss).mean()
return avg_loss, avg_acc
#评估函数
def evaluate(model, iterator, criteon):
avg_loss = []
avg_acc = []
model.eval() #表示进入测试模式
with torch.no_grad():
for batch in iterator:
mask = 1 - (batch.text == TEXT.vocab.stoi['<pad>']).float()
pred = model(batch.text, mask)
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_loss.append(loss.item())
avg_acc.append(acc)
avg_loss = np.array(avg_loss).mean()
avg_acc = np.array(avg_acc).mean()
return avg_loss, avg_acc
#训练模型,并打印模型的表现
best_valid_acc = float('-inf')
for epoch in range(30):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criteon)
dev_loss, dev_acc = evaluate(model, dev_iterator, criteon)
end_time = time.time()
epoch_mins, epoch_secs = divmod(end_time - start_time, 60)
if dev_acc > best_valid_acc: #只要模型效果变好,就保存
best_valid_acc = dev_acc
torch.save(model.state_dict(), 'wordavg-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs:.2f}s')
print(f' Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f' Val. Loss: {dev_loss:.3f} | Val. Acc: {dev_acc*100:.2f}%')
#用保存的模型参数预测数据
model.load_state_dict(torch.load("wordavg-model.pt"))
test_loss, test_acc = evaluate(model, test_iterator, criteon)
print(f'Test. Loss: {test_loss:.3f} | Test. Acc: {test_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0.0m 3.05s
Train Loss: 0.695 | Train Acc: 51.55%
Val. Loss: 0.685 | Val. Acc: 51.35%
Epoch: 02 | Epoch Time: 0.0m 2.70s
Train Loss: 0.672 | Train Acc: 58.59%
Val. Loss: 0.641 | Val. Acc: 63.93%
Epoch: 03 | Epoch Time: 0.0m 2.82s
Train Loss: 0.642 | Train Acc: 66.61%
Val. Loss: 0.628 | Val. Acc: 64.32%
Epoch: 04 | Epoch Time: 0.0m 2.88s
Train Loss: 0.620 | Train Acc: 66.31%
Val. Loss: 0.600 | Val. Acc: 68.19%
Epoch: 05 | Epoch Time: 0.0m 3.17s
Train Loss: 0.579 | Train Acc: 71.15%
Val. Loss: 0.672 | Val. Acc: 61.63%
Epoch: 06 | Epoch Time: 0.0m 3.11s
Train Loss: 0.574 | Train Acc: 71.91%
Val. Loss: 0.578 | Val. Acc: 70.53%
Epoch: 07 | Epoch Time: 0.0m 2.78s
Train Loss: 0.525 | Train Acc: 73.71%
Val. Loss: 0.617 | Val. Acc: 68.92%
Epoch: 08 | Epoch Time: 0.0m 2.85s
Train Loss: 0.499 | Train Acc: 77.68%
Val. Loss: 0.535 | Val. Acc: 75.26%
Epoch: 09 | Epoch Time: 0.0m 3.53s
Train Loss: 0.457 | Train Acc: 80.94%
Val. Loss: 0.536 | Val. Acc: 75.74%
Epoch: 10 | Epoch Time: 0.0m 4.77s
Train Loss: 0.423 | Train Acc: 82.97%
Val. Loss: 0.527 | Val. Acc: 73.48%
Epoch: 11 | Epoch Time: 0.0m 3.57s
Train Loss: 0.372 | Train Acc: 85.79%
Val. Loss: 0.624 | Val. Acc: 72.57%
Epoch: 12 | Epoch Time: 0.0m 4.01s
Train Loss: 0.341 | Train Acc: 87.21%
Val. Loss: 0.549 | Val. Acc: 71.79%
Epoch: 13 | Epoch Time: 0.0m 7.35s
Train Loss: 0.334 | Train Acc: 86.67%
Val. Loss: 0.725 | Val. Acc: 66.45%
Epoch: 14 | Epoch Time: 0.0m 3.95s
Train Loss: 0.296 | Train Acc: 90.15%
Val. Loss: 0.559 | Val. Acc: 75.56%
Epoch: 15 | Epoch Time: 0.0m 4.90s
Train Loss: 0.290 | Train Acc: 90.29%
Val. Loss: 0.860 | Val. Acc: 65.89%
Epoch: 16 | Epoch Time: 0.0m 3.09s
Train Loss: 0.272 | Train Acc: 89.90%
Val. Loss: 0.598 | Val. Acc: 71.22%
Epoch: 17 | Epoch Time: 0.0m 4.81s
Train Loss: 0.276 | Train Acc: 90.30%
Val. Loss: 0.871 | Val. Acc: 66.36%
Epoch: 18 | Epoch Time: 0.0m 3.16s
Train Loss: 0.275 | Train Acc: 89.87%
Val. Loss: 0.772 | Val. Acc: 70.40%
Epoch: 19 | Epoch Time: 0.0m 3.18s
Train Loss: 0.251 | Train Acc: 90.88%
Val. Loss: 0.657 | Val. Acc: 72.40%
Epoch: 20 | Epoch Time: 0.0m 3.06s
Train Loss: 0.230 | Train Acc: 91.81%
Val. Loss: 0.720 | Val. Acc: 72.79%
Epoch: 21 | Epoch Time: 0.0m 3.08s
Train Loss: 0.235 | Train Acc: 92.53%
Val. Loss: 0.769 | Val. Acc: 72.79%
Epoch: 22 | Epoch Time: 0.0m 4.40s
Train Loss: 0.238 | Train Acc: 92.29%
Val. Loss: 0.729 | Val. Acc: 77.13%
Epoch: 23 | Epoch Time: 0.0m 5.32s
Train Loss: 0.228 | Train Acc: 91.69%
Val. Loss: 0.678 | Val. Acc: 74.87%
Epoch: 24 | Epoch Time: 0.0m 3.72s
Train Loss: 0.220 | Train Acc: 92.08%
Val. Loss: 0.764 | Val. Acc: 76.82%
Epoch: 25 | Epoch Time: 0.0m 5.54s
Train Loss: 0.206 | Train Acc: 92.35%
Val. Loss: 1.014 | Val. Acc: 71.01%
Epoch: 26 | Epoch Time: 0.0m 3.50s
Train Loss: 0.200 | Train Acc: 93.98%
Val. Loss: 0.955 | Val. Acc: 71.70%
Epoch: 27 | Epoch Time: 0.0m 3.21s
Train Loss: 0.197 | Train Acc: 93.49%
Val. Loss: 0.912 | Val. Acc: 72.87%
Epoch: 28 | Epoch Time: 0.0m 3.96s
Train Loss: 0.185 | Train Acc: 93.19%
Val. Loss: 0.639 | Val. Acc: 78.39%
Epoch: 29 | Epoch Time: 0.0m 3.88s
Train Loss: 0.188 | Train Acc: 94.74%
Val. Loss: 0.778 | Val. Acc: 73.26%
Epoch: 30 | Epoch Time: 0.0m 3.83s
Train Loss: 0.175 | Train Acc: 94.01%
Val. Loss: 0.935 | Val. Acc: 71.40%
Test. Loss: 0.713 | Test. Acc: 78.31%