import random
import urllib
from urllib import request
import os
#########################################################
# 参数设置
wsp = 'DouziOOXX'
# 打开连接
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
# print(url)
return html
def get_page(url):
# 打开链接
html = url_open(url).decode('utf-8')
# 查找 current-comment-page
a = html.find('current-comment-page') + 23
b = html.find(']', a) # 从a开始,找到第一个 ], 返回索引
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg', a, a + 255)
if b != -1: # 找到一个 jpg
img_addrs.append(html[a+9 : b+4]) # 加入列表
else: # 到不到, 移动b的位置
b = a + 9
a = html.find('img src=', b) # 在b之后开始,再找img src
# for each in img_addrs:
# print(each)
return img_addrs
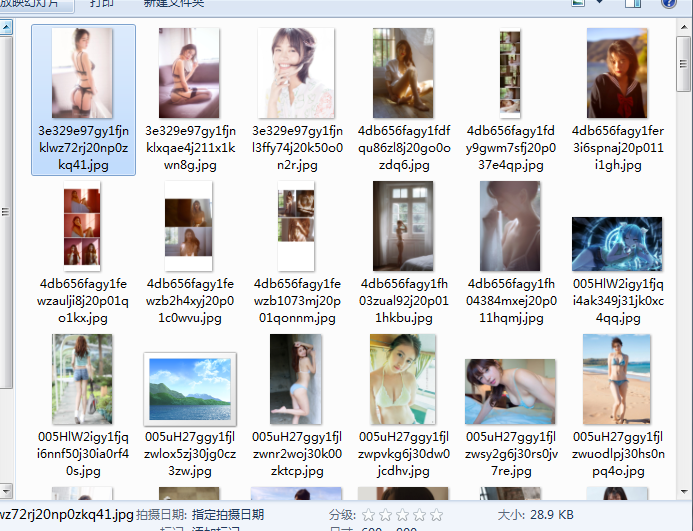
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
# print('http:' + each)
with open(filename, 'wb') as f:
img = url_open('http:' + each)
f.write(img)
def download_mm(folder = wsp, pages = 10):
os.mkdir(folder)
# 切换到工作目录
os.chdir(folder)
url = "http://jandan.net/ooxx/"
# 获得页面的地址
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
# 打开这个地址
page_url = url + "page-" + str(page_num)
# 获取图片地址, 保存为一个列表
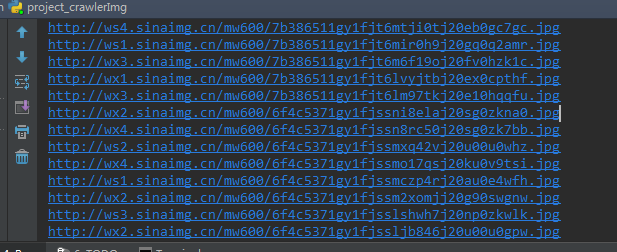
img_addrs = find_imgs(page_url)
# 保存到图片到指定文件夹
save_imgs(folder, img_addrs)
if __name__=='__main__':
download_mm()