CMS实现原理
简介
学习过JAVA语言的堆CMS这款垃圾收集器都不会陌生,CMS曾经号称是并发度最高的垃圾收集器。CMS是一款只能应用于老年代收集的垃圾收集器。CMS为了支持与应用线程同时工作(垃圾收集的时候,业务线程同时工作,修改对象),重载了写屏障(赋值引用对象被修改的时候,将其压入标记栈)代码。在并发标记阶段修改的对象必须重新标记使得所有的对象都被标记了。
垃圾收集器可以简化内存分配和增强鲁棒性,但是早期不被程序员所接受,很大一部原因是性能问题。开发者不接收自动垃圾回收,只有两方面的原因:吞吐量和延迟。计算能力的增加被内存需求增加所抵消了。
分代收集可以较好解决吞吐量和延迟的问题?如何解决呢?将整个堆划分成两部分,新生代和老年代。
- 新生代的特性:
- 存储新创建的对象
- 大部分对象都是一些朝生夕死的对象,每次收集可以释放大部分的空间
- 通常空间也是相对较小,所以收集较快,不用担心延迟问题
- 老年代的特性
- 新生代对象经过多次收集还存活,会晋升到老年代中
- 尽管老年代空间较大,总会有填满的时候,最终会填满,需要进行回收
- 对老年的收集同样存在吞吐量和延迟的问题,分代设计不能解决这个问题
CMS充分利用分代收集系统的优势,致力于减少最糟糕的情形下垃圾回收的停顿时间,它在大部分的情形下可以和业务线程同时运行,只有极少情况下会挂起业务线程。
并行&&并发
- 并行:在GC中并行表示多条GC线程并行工作,但此时用户线程处于等待状态,在单核CPU中,并行GC效率较低
- 并发:用户线程和GC线程同时执行
CMS执行的几个阶段
cms是一个并发的三色算法,该算法使用写屏障,将变更的对象保持为灰色。cms在三色算法的基础上做了一些创新,牺牲了完全并发以获得更高的吞吐量, 它允许在堆根节点变更时不需要保证三色的不变,对根节点(栈,寄存器,全局变量)的更新比堆中的更新通常更频繁。该算法在处理根节点时,会短暂的挂起应用线程,该算法假设在一个堆中对象的变更频率较低的基础之上,否则,在重新标记阶段需要扫描大量的脏对象,导致较长的停顿时间。虽然某些程序会打破我们的假设,但是,Boehm et al.的报告中显示在实践中这项技术运行良好,尤其是在交互式的应用中。主要由4阶段组成:
- 初始标记阶段
挂起应用线程,标记系统中由根节点对象直接可达的对象 - 并发标记阶段
恢复应用线程,同时标记所有可达的对象。这个阶段不能保证在结束的时候能标记完所有的可达对象,因为应用线程在运行,可能会导致部分引用的变更,导致一些活对象不可达。为了解决这个问题,该算法会通过某种方式跟变更的对象的引用保持联系。 - 重新标记阶段
再一次挂起应用线程,将并发标记阶段更新过得对象当做根对象再一次扫描标记所有可达的对象,在这个过程可能会导致浮动垃圾(垃圾对象被错误标记了),在下一次垃圾回收的时候被回收。 - 并发清除阶段
再一次恢复应用线程,并发清除整个堆,释放没有被标记的对象空间。这个阶段必须注意,不能释放新创建的对象空间。
CMS执行的一个示例

该示例取自一篇牛逼的论文,解释我们的场景完全足够。整个堆内存有4页,包含了7个对象。在初始标记阶段,4页都标记为clean,对象a是从根直接可达的,所以将其标记为活对象。
1a处于并发标记的过程中,对象b,c,e都被标记为活对象。在这个时候,对象g应用d被删除了,对象b引用c修改为引用d.因为g和b发生了变更,所以第1页和第3页被标记为脏页。
1c表示在并发标记结束时的样子。很明显,标记还不完整,因为b的引用对象d还没有被标记。在重新标记阶段才会被标记:在这个阶段所有的脏页会重新扫描,d会被标记上。
1d表示就是重新标记后的状态,这时候标记就结束了。下一个阶段就是并发清除了,最终f会被回收。
在回收的时候,虽然c现在是不可达的对象,但它被标记了,所以不会被回收,它会在下一次垃圾回收的时候会被回收。
CMS收集的设计决策
内存分配
有如下的集中方式,CMS选择了空闲列表的方式。
- 标记压缩:
- 压缩之后,内存分配更有效
- 压缩之后,需要更新指针指向的地址,但是在并发场景下更新指针是非常困难的
- 空闲列表
- 两个空闲列表保存,一大一小,小对象一个list,大对象一个list
老年代到新生代的扫描
某些场景下,分代收集器需要跟踪老年代到新生代的引用。CMS使用卡表的方式来解决这个问题。
- 扫描整个老年代:
- 采用这种方式,新生代回收基本等于扫描整个堆空间
- card table:
- 将整个堆分割成若干个子区域,每一个区域作为一个card, 当该区域的对象有更新时,通过写屏障将包含该对象的card标记为dirty(即该区域被修改过)。
- 虚拟内存保护技术可以将页标记为脏页,也能实现这个目的,但是使用card table的方式有一些优势:
- 开销小
- 粒度更细:虚拟内存保护技术使用页大小为单位,会导致标记为脏页的对象远远超过更新过得对象数,通常最小是4KB, 而CMS中card table可以是512M
- 更精确的类型信息:虚拟内存保护技术不区分更新的是什么数据,card table可以精确控制引用对象变更才标记为脏页,前者会导致更多的脏页
根扫描
标记对象使用额外的bitmap来存储,没有直接存储在对象头中。避免并发过程中,影响对象头的访问。对对象的扫描需要一个额外的数据结构来存储将要被扫描的对象,队列或者栈来存储。
- 最小化停顿时间
直接将所有可达的对象放置在这个数据结构中,在垃圾收集器中,内存是稀缺资源,对内存的使用需要谨慎。根对象包含有栈、寄存器、全局变量,此外还包含并发标记阶段未被发生变更的对象,这将会导致该数据结构占用的内存特别大,所以不能使用这种方式。 - 最小化内存开销
由根直接可达的对象放置在该数据结构中,这会将所有对象的扫描都当做根扫描的一部分,不适合并发的场景。 - 前两种方式的妥协方案
根直接可达的对象放置在该数据结构中,同时使用bitmap来标记已经被扫描过得对象- 执行过程
- 引用在cur前面,仅标记,不用推到栈中,将在后面的扫描被访问
- 引用在cur后面,标记同时将其压入栈中
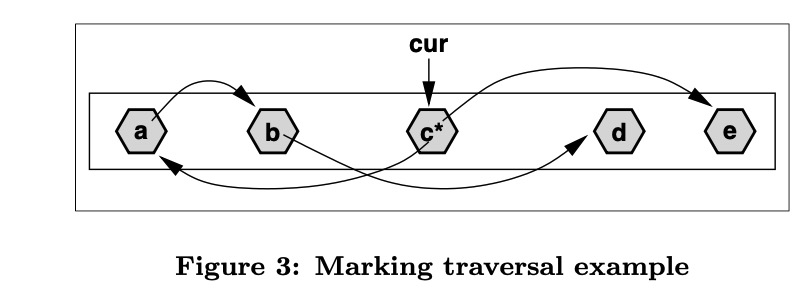
上图中,e仅仅被标记,a被标记和压入栈中。
- 执行过程
并发清除
随着堆内存分配和回收,内存块的大小会逐渐变小,清除回收之后,需要堆内存块进行合并操作。在非并发的场景,可以直接将所有的空闲列表的空间直接重建就能实现。
在并发收集器中,回收的同时也在做内存分配,这个加排它锁可以解决。
垃圾收集执行的伪代码:
initFrac = (1 - heapOccupancyFrac) * allocBeforeCycleFrac;
while (TRUE) {
sleep(SLEEP_INTERVAL);
if (generationOccupancy() > initFrac) {
/* 1st stop-the-world phase */
initialMarkingPause();
concurrentMarkingPhase();
concurrentPreCleaningPhase();
if (markedPercentage() < 98%) {
/* 2nd stop-the-world phase */
finalMarkingPause();
if (markedPercentage() < 98%)
concurrentSweepingPhase();
}
}
}