自己做了一个简单的爬虫,目标是爬取网页上的图片。
爬虫实现的核心思想是一个广度优先搜索的过程。首先设定一个源网页作为搜索的起始点,然后下载其中所包含的图片,再将源网页中包含的链接加入搜索队列中,完成对源网页的浏览。接下来不停地取出搜索队列中的队首元素,下载其中的图片并将其中的链接加入队列中,完成后将该元素出队,即可实现爬虫在网页间的跳转。
主要的过程可以大致描述成这个样子:
q.push(s);
while (!q.empty())
{
v=q.front();
q.pop();
GetImg(v);
GetUrl(v);
}
搞清楚了主要框架,接下来就是具体实现的问题了。比较重要的有三个点,第一是如何获得网页的源码,第二是如何寻找网页里的图片和链接,第三是如何下载指定的图片。
获取网页的源代码可以用HINTERNET来实现。
寻找图片和链接就比较容易了,图片的前面会有<img,链接前面会有<a href=”,顺藤摸瓜就好了。当然这个判断并不完全可靠,不过我对html的格式就知道这么多了,暂且先这么写着。
下载指定的图片可以用URLDownloadToFile函数实现。
写程序的过程中遇到的几个困扰:
1.有的函数要求字符串是_TCHAR,而这个字符串在别处使用时又需要是char。
解决办法:
char转_TCHAR
MultiByteToWideChar(CP_ACP, 0, char字符串, -1, (LPWSTR)_TCHAR字符串, 长度);
_TCHAR转char
WideCharToMultiByte(CP_ACP, 0, (LPWSTR)_TCHAR字符串, -1, char字符串, 长度, NULL, NULL);
2.内存使用。
在保存取出的图片和链接的url时,我使用的时char [1024],结果一直蜜汁崩溃。反复运行多次后才发现原来有的url特别的长,超过了这个1024。于是,我把长度设置成了2048,并且加上长度超过2000时自动过掉这个点的限制才解决了这个问题。
这个程序之前的版本中,字符串都是用字符指针配合new,malloc等来定义的,指针用的时候总是心慌慌,怕一不小心就内存爆炸,干脆改成了全局数组变量。
介绍一下我的程序吧:
ShowMemoryInfo显示本程序内存使用情况,跟功能没太大关系,调试的时候用的。
GetPageBuf获得网页的源代码,保存在pageBuf里
GetImg下载当前网页里的图片
ImgExist判断图片是否下载成功
GetHref获得当前网页里的链接并加入队列
BFS搜索
源网页选取的是http://www.baidu.com/
下载的图片保存在img文件夹下。
运行时的详细信息输出在ExecLog.txt中。
MAX_NUDE_NUM为总的搜索的网页数。
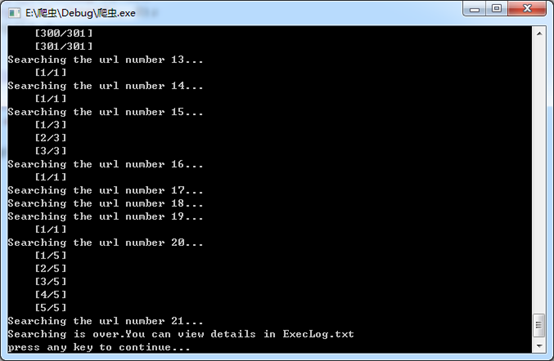
运行结果:
程序:


#include "stdafx.h"
#define MAX_NODE_NUM 20
#pragma comment(lib, "urlmon.lib")//Download
#pragma comment(lib, "Wininet.lib")//Web page
#pragma comment(lib,"psapi.lib")//Memory
#include <string>
#include <iostream>
#include <fstream>
#include <vector>
#include <time.h>
#include <queue>
#include <windows.h>//Web page
#include <wininet.h>//
#include <tchar.h>
#include <urlmon.h>//Download
#include <psapi.h>//Memory
using namespace std;
queue<_TCHAR *> q;
vector<_TCHAR *> imgList;
vector<_TCHAR *> fileName;
char pageBufMemory[5000000];
_TCHAR hrefMemory[5000000];
_TCHAR * currentHrefPtr = hrefMemory;
_TCHAR imgMemory[5000000];
_TCHAR * currentImgPtr = imgMemory;
_TCHAR fileNameMemory[5000000];
_TCHAR * currentFNPtr = fileNameMemory;
char imgSrc[2048];
char href[2048];
char imgFile[2048];
//Show the Memory that is used
void ShowMemoryInfo() {
HANDLE handle = GetCurrentProcess();
PROCESS_MEMORY_COUNTERS pmc;
GetProcessMemoryInfo(handle, &pmc, sizeof(pmc));
cout << "内存使用:"
<< pmc.WorkingSetSize / 1000
<< "K/"
<< pmc.PeakWorkingSetSize / 1000
<< "K + "
<< pmc.PagefileUsage / 1000
<< "K/"
<< pmc.PeakPagefileUsage / 1000
<< "K"
<< endl;
}
//The Detail when program executing
FILE * execLog;
errno_t errExecLog = fopen_s(&execLog, "ExecLog.txt", "w");
//Get the source code of web page
bool GetPageBuf(_TCHAR * url, char * & pageBuf, int & byteLen) {
/*FILE * debuging;
errno_t errDebug = fopen_s(&debuging, "debuging.txt", "w");*/
byteLen = 0;
HINTERNET hSession = InternetOpen(_T("UrlTest"), INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
if (hSession != NULL) {
HINTERNET hHttp = InternetOpenUrl(hSession, url, NULL, 0, INTERNET_FLAG_DONT_CACHE, 0);
if (hHttp != NULL) {
char Temp[1024];
DWORD recv = 0;
do {
InternetReadFile(hHttp, Temp, 1023, &recv);
for (int i = 0; i < recv; i++) {
pageBuf[byteLen++] = Temp[i];
}
Temp[recv] = '�';
//printf("%s
",Temp);
} while (recv > 0);
pageBuf[byteLen] = '�';
InternetCloseHandle(hHttp);
hHttp = NULL;
} else {
fprintf(execLog, " Failed.
");
return false;
}
InternetCloseHandle(hSession);
hSession = NULL;
} else {
fprintf(execLog, " Failed.
");
return false;
}
return true;
}
//Check whether the downloading process is successful
bool ImgExist(_TCHAR * FN, int iTextLen) {
WideCharToMultiByte(CP_ACP, 0, (LPWSTR)FN, -1, imgFile, iTextLen, NULL, NULL);
FILE * imgCheck;
errno_t errImgCheck = fopen_s(&imgCheck, imgFile, "r");
if (errImgCheck) {
return false;
} else {
return true;
}
}
//Download the imagines
void GetImg(char * pageBuf) {
//Init
imgList.clear();
fileName.clear();
//Get img source
char * pos = strstr(pageBuf, "<img");
while (pos != NULL) {
char * left = strstr(pos, "src="");
if (left != NULL) {
left += 5;
} else {
pos = strstr(pos + 1, "<img");
continue;
}
char * right = strstr(left, """);
if (right != NULL) {
right -= 1;
} else {
pos = strstr(pos + 1, "<img");
continue;
}
if ((left > right) || (right - left > 2000)) {
pos = strstr(pos + 1, "<img");
continue;
}
int srcByte = 0;
for (char * i = left; i <= right; i++) {
imgSrc[srcByte++] = (*i);
}
imgSrc[srcByte] = '�';
//Add "https:" if they are not exist
if (strstr(imgSrc, "https:") == NULL && strstr(imgSrc, "http:") == NULL) {
for (int i = srcByte + 6; i > 5; i--) {
imgSrc[i] = imgSrc[i - 6];
}
imgSrc[0] = 'h';
imgSrc[1] = 't';
imgSrc[2] = 't';
imgSrc[3] = 'p';
imgSrc[4] = 's';
imgSrc[5] = ':';
srcByte += 6;
}
//printf("%s
", imgSrc);
_TCHAR * pwText = currentImgPtr;
MultiByteToWideChar(CP_ACP, 0, imgSrc, -1, (LPWSTR)pwText, srcByte + 1);
imgList.push_back(pwText);
currentImgPtr += srcByte + 5;
if (currentImgPtr - imgMemory > 4990000) {
currentImgPtr = imgMemory;
}
int nameBegin = 0;
for (int i = srcByte - 1; i > 5; i--) {
if (imgSrc[i] == '/') {
nameBegin = i + 1;
break;
}
}
//Add "./img/" to the file name.
imgSrc[--nameBegin] = '/';
imgSrc[--nameBegin] = 'g';
imgSrc[--nameBegin] = 'm';
imgSrc[--nameBegin] = 'i';
imgSrc[--nameBegin] = '/';
imgSrc[--nameBegin] = '.';
pwText = currentFNPtr;
MultiByteToWideChar(CP_ACP, 0, imgSrc + nameBegin, -1, (LPWSTR)pwText, srcByte - nameBegin + 1);
fileName.push_back(pwText);
currentFNPtr += srcByte - nameBegin + 5;
if (currentFNPtr - fileNameMemory > 4990000) {
currentFNPtr = fileNameMemory;
}
pos = strstr(pos + 1, "<img");
}
if (imgList.size() == 0) {
fprintf(execLog, " No Imagine Found.
");
}
//Download imgs in the list
for (int i = 0; i < imgList.size(); i++) {
fwprintf_s(execLog, _T(" %s
"), imgList[i]);
URLDownloadToFile(NULL, imgList[i], fileName[i], NULL, NULL);
if (ImgExist(fileName[i], wcslen(fileName[i]) + 1)) {
fprintf(execLog, " OK.
");
} else {
fprintf(execLog, " Failed.
");
}
printf(" [%d/%d]
", i + 1, imgList.size());
}
imgList.clear();
currentImgPtr = imgMemory;
fileName.clear();
currentFNPtr = fileNameMemory;
}
void GetHref(char * pageBuf) {
//fprintf(debuging, "%s
", pageBuf);
char * pos = strstr(pageBuf, "<a href="");
while (pos != NULL) {
//printf(" Queue Length:>%d
", q.size());
char * left = pos + 9;
char * right = strstr(left, """);
if (right != NULL) {
right--;
} else {
pos = strstr(pos + 1, "<a href="");
continue;
}
if ((left > right) || (right - left > 2000)) {
pos = strstr(pos + 1, "<a href="");
continue;
}
//printf(" Left:%X Right:%X
", left, right);
int hrefByte = 0;
for (char * i = left; i <= right; i++) {
href[hrefByte++] = (*i);
}
href[hrefByte] = '�';
//printf(" Href String Got
");
_TCHAR * pwText = currentHrefPtr;
fprintf(execLog, " %s
", href);
MultiByteToWideChar(CP_ACP, 0, href, -1, (LPWSTR)pwText, hrefByte + 1);
//printf(" Memory Used:>%d
", currentHrefPtr - hrefMemory);
q.push(pwText);
currentHrefPtr += hrefByte + 5;
if (currentHrefPtr - hrefMemory > 4990000) {
currentHrefPtr = hrefMemory;
}
pos = strstr(pos + 1, "<a href="");
}
}
void BFS() {
int limit = 0;
while (!q.empty()) {
if (limit++ > MAX_NODE_NUM) break;
//ShowMemoryInfo();
printf("Searching the url number %d...
", limit);
_TCHAR * url = q.front();
fwprintf_s(execLog, _T("URL>:%s
"), url);
q.pop();
int byteLen;
char * pageBuf = pageBufMemory;
if (GetPageBuf(url, pageBuf, byteLen) == false) {
continue;
}
fprintf(execLog, " Imagines on this page>:
");
GetImg(pageBuf);
fprintf(execLog, " Hrefs on this page>:
");
GetHref(pageBuf);
}
}
int main() {
CreateDirectory(_T("./img"), 0);
CreateDirectory(_T("./html"), 0);
while (!q.empty()) {
q.pop();
}
q.push(_T("http://www.baidu.com/"));
BFS();
printf("Searching is over.You can view details in ExecLog.txt
");
printf("press any key to continue...
");
getchar();
fclose(execLog);
return 0;
}
小应用:从百度贴吧中的一个帖子里复制所有楼主发布的帖子。这个帖子是一片小说,作者一共写了七千多层楼,二百多页,两百多万字,相当长。
首先观察一下第一页的链接http://tieba.baidu.com/p/1437645079?see_lz=1&pn=1。see_lz=1表示只看楼主,pn=1表示第一页。在只看楼主下一共有249页,生成这些链接并下载相应的网页源码。
观察一下下载下来的源代码:
<div class="d_post_content_main "> <div class="p_content "> <div class="save_face_bg_hidden save_face_bg_0"><a class="save_face_card"></a></div> <cc> <div id="post_content_17639511636" class="d_post_content j_d_post_content "> 楔子<br><br>今天,你我在此。<br>场上气氛凝重。<br>场下人群喧嚣。你曾说过,梦想是<a href="http://jump.bdimg.com/safecheck/index?url=x+Z5mMbGPAsY/M/Q/im9DR3tEqEFWbC4Yzg89xsWivSnkz8P5zvqN5/v625sTx+5K4qTjgNeQuFPhkSMA4BCOOm/fZdF8lDP40ePTcjE3P+qplBjQfoaAUcXEGciUgz5qwnKKPMGk5jpQvKxddxfueUoh3lWq6Zx+A8KOpldseBtVFHRVKAtRFZmEBVHjGgoMDxm7iZ2BjQ=" class="ps_cb" target="_blank" onclick="$.stats.track(0, 'nlp_ps_word',{obj_name:'人人'});$.stats.track('Pb_content_wordner','ps_callback_statics')">人人</a>都能拥有的奢侈品。<br>好巧,我也这么认为。<br>你曾说过,人生,有无数个拐点。当两个人的拐点相遇,这两个人的人生便同归一路。<br>你的拐点断裂,延伸到我的拐点,理直气壮地让我沦陷。<br>你曾说过,我是个傻囘瓜。<br>的确,我傻得无可救药。当我的手划过鼠标和键盘,当年圣诞节的情景历历在目。<br>你我的赌约,每一次我都是胜者。<br>当我每次都是得意满满时,你总是微笑。微笑没有花般灿烂,却比圣剑和<a href="http://jump.bdimg.com/safecheck/index?url=x+Z5mMbGPAsY/M/Q/im9DR3tEqEFWbC4Yzg89xsWivSo2JkWIwEzDCI5FEvaSJG6ZInIi4k8KEu5449mWp1SxBADVCHPuUFSTGH+WZuV+ecUBG6CY6mAz/Zq1mzxbFxzBMeEaX9WBGHGL+KXSMo7CVDerlUfdpYhOgzWMoTVjrYkPlFM8hYANPRufykqnY0qdj2oeHoEzTI=" class="ps_cb" target="_blank" onclick="$.stats.track(0, 'nlp_ps_word',{obj_name:'狂战斧'});$.stats.track('Pb_content_wordner','ps_callback_statics')">狂战斧</a>更能拯救世界。<br>后来我才明白,你也喜欢我志得意满的表情,你喜欢的。<br>喜欢到,宁愿让我赢。你说,你是我的Angel,会永远守护我。塔下的TP,永远第一个为我亮起。<br>我说,Demon love Angel,我们,一起守护我们的家。<br>你说,无论如何,恶魔与天使,还是不能在一起的……<br>我愿做一名恶魔,以鼠标和键盘为武器,攻陷那些壁垒城池,无关沉沦与升华,我要将我的天使抢回!今天,我要依旧赢!<br>……</div><br> </cc> <br> <div class="user-hide-post-down" style="display: none;"></div> </div> <a class="l_post_anchor" name="17639511636l"></a><div class="core_reply j_lzl_wrapper"><div class="core_reply_tail clearfix"><div class="j_lzl_r p_reply" data-field='{"pid":17639511636,"total_num":122}'><a href="#" class="lzl_link_unfold" style="display:none;">回复(122)</a><span class="lzl_link_fold" style="display:">收起回复</span></div><div class="post-tail-wrap"><span class="j_jb_ele"><a href="#" onclick="window.open('http://tieba.baidu.com/complaint/info?type=0&cid=0&tid=1437645079&pid=17639511636','newwindow', 'height=900, width=800, toolbar =no, menubar=no, scrollbars=yes, resizable=yes, location=no, status=no');return false;" class="tail-info" data-checkun="un">举报<i class="icon-jubao pb_list_triangle_down"></i></a>|<span class="super_jubao" style="display:none;"><a href="#" onclick="window.open('http://tieba.baidu.com/complaint/info?type=1&cid=0&tid=1437645079&pid=17639511636','newwindow', 'height=900, width=800, toolbar =no, menubar=no, scrollbars=yes, resizable=yes, location=no, status=no');return false;">侵权举报</a><a href="#" onclick="window.open('http://tieba.baidu.com/complaint/info?type=2&cid=0&tid=1437645079&pid=17639511636','newwindow', 'height=900, width=800, toolbar =no, menubar=no, scrollbars=yes, resizable=yes, location=no, status=no');return false;">有害信息举报</a></span></span><span class="tail-info">3楼</span><span
可见正文开始部分是以<div id=post_content_为标志,结束标志则是在那之后的第一个</div>,只需把中间的字符串复制下来即可。
尚有不足的一点是其中很多地方作者写的并不属于正文的题外话都用中文中括号括起来了两个字符分别是0xA1BE和0xA1BF,我虽然写程序的时候过掉了这部分,但执行起来并没有成功,尴尬。
代码:
#include "stdafx.h" #define MAX_NODE_NUM 20 #pragma comment(lib, "urlmon.lib")//Download #pragma comment(lib, "Wininet.lib")//Web page #include <string> #include <iostream> #include <fstream> #include <vector> #include <time.h> #include <queue> #include <windows.h>//Web page #include <wininet.h>// #include <tchar.h> #include <stdio.h> #include <urlmon.h>//Download using namespace std; queue<_TCHAR *> q; char pageBufMemory[5000000]; char * pageBuf; char Text[5000000]; FILE * ofile; errno_t errOfile = fopen_s(&ofile, "DotAer.txt", "w"); //Get the source code of web page bool GetPageBuf(_TCHAR * url, char * & pageBuf, int & byteLen) { /*FILE * debuging; errno_t errDebug = fopen_s(&debuging, "debuging.txt", "w");*/ byteLen = 0; HINTERNET hSession = InternetOpen(_T("UrlTest"), INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0); if (hSession != NULL) { HINTERNET hHttp = InternetOpenUrl(hSession, url, NULL, 0, INTERNET_FLAG_DONT_CACHE, 0); if (hHttp != NULL) { char Temp[1024]; DWORD recv = 0; do { InternetReadFile(hHttp, Temp, 1023, &recv); for (int i = 0; i < recv; i++) { pageBuf[byteLen++] = Temp[i]; } Temp[recv] = '�'; //printf("%s ",Temp); } while (recv > 0); pageBuf[byteLen] = '�'; InternetCloseHandle(hHttp); hHttp = NULL; } else { return false; } InternetCloseHandle(hSession); hSession = NULL; } else { return false; } return true; } void TextAnalyse() { char * left; char * right; left = strstr(pageBuf, "<div id="post_content_"); while (left != NULL) { right = strstr(left, "</div>") + 5; int bra = 0; for (char * i = left; i <= right; i++) { if ((*i) == ' ') { continue; } else if ((*i) == '<' || ((*i) == 0xA1 && (*(i + 1)) == 0xBE)) { bra = 1; if ((*(i + 1) == 'b') && ((*(i + 2) == 'r')) && ((*(i + 3) == '>'))) { fprintf(ofile, " "); } } else if ((*i) == '>' || ((*(i - 1)) == 0xA1 && (*i) == 0xBF)) { bra = 0; } else if (bra == 0) { fprintf(ofile, "%c", *i); } } fprintf(ofile, " "); left = strstr(left + 1, "<div id="post_content_"); } } void ComeToBowl() { FILE * infile; errno_t errInfile = fopen_s(&infile, "List.txt", "r"); char str[2000]; _TCHAR url[1000]; for (int i = 1; i <= 249; i++) { cerr << i << ":"; fscanf(infile, "%s", str); MultiByteToWideChar(CP_ACP, 0, str, -1, (LPWSTR)url, strlen(str) + 1); pageBuf = pageBufMemory; int byteRecv; if (!GetPageBuf(url, pageBuf, byteRecv)) { cerr << "#"; } cerr << endl; TextAnalyse(); } fclose(infile); fclose(ofile); } int main() { ComeToBowl(); return 0; }