一、硬布线控制器基本思想
把控制不仅看作为产生专门固定时序控制信号的逻辑电路。而此逻辑电路以使用最少元件和取得最高操作速度为设计目标,一旦控制部件构成后,除非重新设计和物理上对他重新布线,否则要想增加新的控制功能是不可能的。
这种逻辑电路是一种由门电路和触发器构成的复杂树形逻辑网络,故称之为硬布线控制器。

二、流水CPU
一个指令流水线过程段
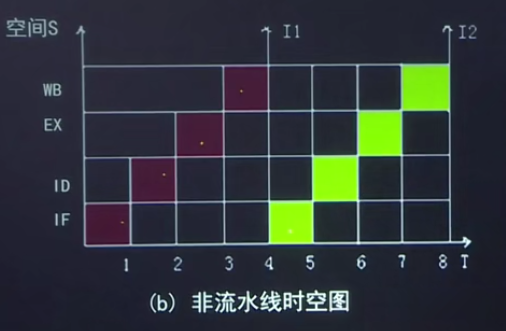

一个指令m部,每一步一个时钟周期,一共n个指令
非流水线;m*n*T
标量流水线 mT+(n-1)T
2.流水线分类
1)使用级别不同:部件功能级、处理机级、处理机间
2)功能不同:单功能、多功能
3)连接方式:动态 静态
4)是否有反馈:线性流水、非线性流水
3、流水线中的主要问题也就是影响流水线的因素
1)资源相关


IF和MEN都需要操作存储器发生冲突
解决方案:
- 一是第I4条指令停顿一拍后再启动,而是增设一共存储器,将指令和数据分别存放在两个存储器中
- 前一指令访存时,后一指令暂停一个时钟周期
2)数据相关

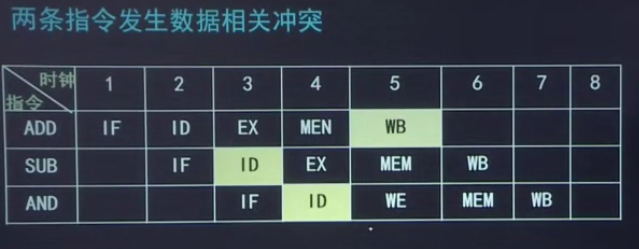
解决办法:
- 在流水CPU的运算器中设置若干运算结果缓冲寄存器,暂时保留运算结果,以便于后继指令直接使用,这称为向前或定向传送技术。
- 将遇到数据相关的指令及其后续指令都暂停一个至几个时钟周期,直到数据相关问题消失
- 通过编译器对数据相关的指令编译优化,调整指令顺序。
3)控制相关(跳转指令)

解决办法:

- 提高转移方向的猜准率
- 加快和提前形成条件码
例一:

R1未写完就要读 写后读

第三条需要操作存储器比较慢 读后写

乘法比加减慢很多 写后写相关

流水线的性能指标:吞吐率 加速比 效率
1)吞吐率:单位时间内流水线所完成的任务数量TP=n/Tk n是任务数 Tk是处理完成n个任务所用的时间
2)加速比:不使用流水线和使用流水线所用时间之比S=T0/Tk T0不使用流水线的执行时间 Tk使用流水线的执行时间 S最大可取到k (流水线的段数)
3)流水线的效率:E=n个任务占用k时空区有效面积/n个任务所用的时间 与k个流水段所围成的时空区总面积 最高为1
4、流水线的多发技术
1)超标量技术
每个时钟周期内可并发多条独立指令配置多个功能部件,不能调整指令的执行顺序,通过编译优化技术,把可并行执行的指令搭配起来。

2)超流水线技术
在一个时钟周期内再分段(3段)
在同一个时钟周期内一个功能部件使用多次(3次)
不能调整指令的执行顺序
3)超长指令字技术
由编译程序挖掘出指令间潜在的并行性
将多条能并行操作的指令组合成一条具有多个操作码字段的超长指令字(可达几百位)

题1:

周期统一且必须能时间足够完成每一个所以是90ns
题2:

题2:

吞吐率:单位之间执行多少条指令
1.03*10的九次方时钟周期 m=4 n=100
4+(100-1)=103 100条指令需要103个时钟周期
一条指令需要1.03个时钟周期
每秒有1.03*10的九次方个时钟周期 一条指令需要1.03个时钟周期 相除得1*10的九次方条指令
题4、

2014年第44题
题5:某带终端的计算机指令系统共有101种操作,采用微程序控制方式,控制存储器中相应最少有(103)个微程序
答:某指令系统中具有n种机器指令,则控制存储器中的微程序数至少有n+2个(增加的1个为公共的取指微程序,1个为对应中断周期的微程序)则控制存储器中的位程序数可以为n+2个
指令周期是从一条指令的启动到下一条指令的启动的时间间隔,而CPU周期是机器周期,是指令执行中每一步操作所需要的时间,不相等。
主存和控存区别:
主存储器:在CPU外 存储指令和数据 由RAM各ROM实现
控制存储器:在CPU内 存放微指令 有ROM实现(由于每一条微指令发出的信号是事先设计好的,不需要改变,g故存放所有控制信号的存储器应为ROM) 按照指令的地址访问
题:
设指令由取指、分析和执行3个子部件完成;并且每个子部件的时间均为Δt。若采用度为4的超标量流水线处理机,连续执行12条指令,共需花费()Δt。
A.3
B.5
C.9
D.14
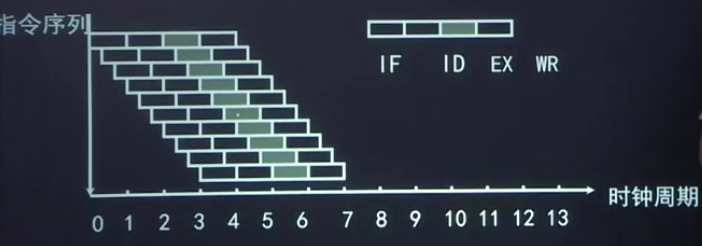
指令由取指、分析和执行3个子部件完成,n=3,且每个子部件的时间均为止Δt。若采用常规标量单流水线处理机(即该处理机的度m=1),连续执行12条(k=-12)指令的时空图如图2-12所示。执行这12条指令所需的总时间为:Tk=(k+3-1)Δt=(12+3)Δt=14Δt。 
若采用度为4(m=4)的超标量流水线处理机,连续执行上述12条(k=12)指令的时空图如图2-13所示。

由图可知,执行这12条指令所需的总时间只需要5Δt。
题:

答:每个功能段的 时间设定为取指 分析和执行部分的最长时间为2ns,第一条指令在第5ns时执行完毕,其余的99条指令每隔2ns执行完一条,所以100条指令全部执行完毕所需时间为5+99*2=203ns
控制器和执行器的组成:
控制器:指令寄存器 程序计数器 操作控制器
执行器:运算器 存储器 外围设备
tip:
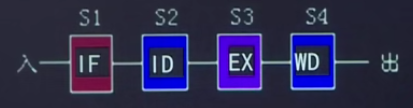
五阶段流水线可以分为取指IF 译码/取数ID 执行EXC 存储器读MEM 写回Write Back数字系统中,各个子系统通过数据总线连接形成的数据传输路径称为数据通路,包括程序计数器 算术逻辑运算部件 通用寄存器组 取指部件等 不包含控制器
CPU的主频是1.03GHz,也就是说每秒有1.03G个时钟周期

答:-513原码为1000 0010 0000 0001 B 按位取反 1111 1101 1111 1110 再加1 1111 1101 1111 1111B,即指令执行之前(R1)=FDFFH 右移一位为1111 1110 1111 1111B 所以指向后为(R1)=FEFFH
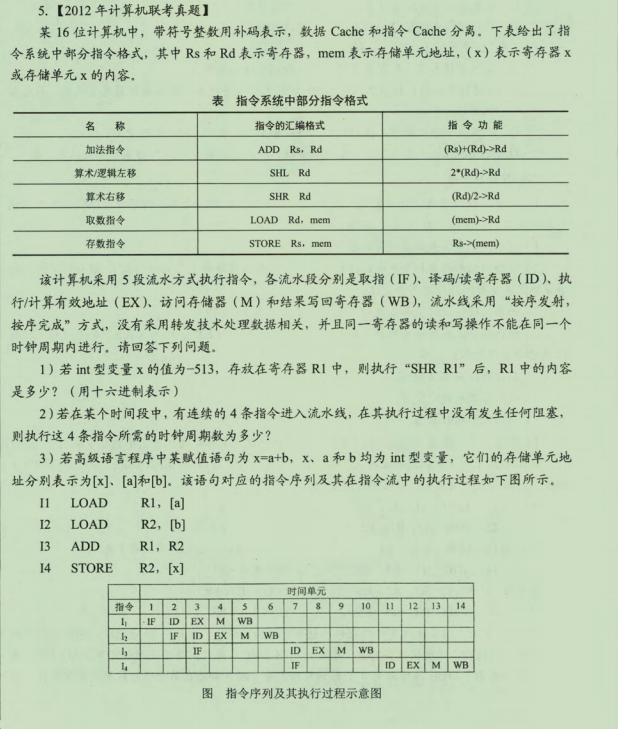
2)每个时钟周期只能由一条指令进入流水线,从第五个周期开始,每个周期都会有一条指令执行完成,所以至少需要4+(5-1)=8个时钟周期
3)I3的ID段被阻塞的原因:因为I3与I1和I2都存在数据相关,需要等到I1和I2将结果写回寄存器后,I3才能读存储区中的内容,所以I3的ID段被阻塞,I4的IF段被阻塞的原因是因为I4的前一条指令I3的ID段被阻塞,所以I4的IF段被阻塞。
4)因为2*x操作有左移和加法两种实现方法,故x=x*2+a对应的指令序列为
| 11 | LOAD | R1,[x] | |
| 12 | LOAD | R2,[a] | |
| 13 | SHL | R1 | ADD R1,R1 |
| 14 | ADD | R1,R2 | |
| 15 | STORE | R2,[x] |
指令周期:
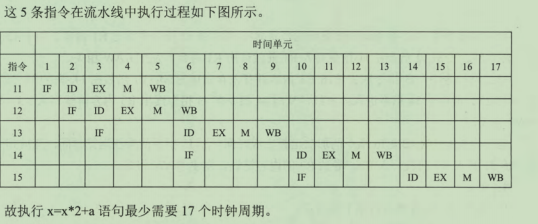
2014年真题:
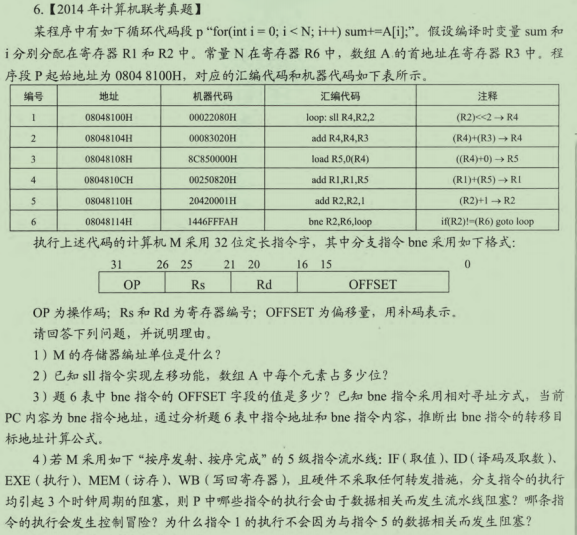
答:计算机M采用32位定长指令字,即一条指令占32位也就是4B,据指令地址可知每条指令的地址差是4个地址单位,也就是4个地址单位占4B。一个地址单位就代表了1B,所以该计算机是按字节编址的。
2)编号为1的指令可以看出sll指令是左移2位也就是间隔4个地址单元,二计算机按照字节编址,所以数组A中的每个元素占4B
3)由表可知,bne指令的机器代码是1446FFFAH,由指令格式可知后2B的内容为OFFSET字段,所以该指令的OFFSET字段内容为FFFAH,(FFFAH=1111 1111 1111 1010H 除符号位外取反1000 0000 0000 0101 再加1 1000 0000 0000 0110=-6),所以用补码表示是-6.
???
当系统执行到bne指令时,PC自动+4,PC的内容就变为08048118H,而跳转的地址是08048100H,两者相差了18H,即24个单位的地址空间(1*16+8=24),所以偏移址的一位即是真实跳转地址的-24/-6=4位,可知bne指令的转义目标地址公式为(PC)+4+OFFSET*4
4)由于数据相关而发生阻塞的指令是第2 3 4 6条,因为第2 3 4 6条指令都与各自前一条指令发生数据相关,第6条会发生控制冒险
当前循环的第五条指令与下次循环的第一条指令虽然数据相关,但是由于第6条指令后有3个时钟周期的阻塞,因而消除了改数据相关。
2014

未看