YbtOJ:冲刺 NOIP2020 模拟赛 Day10
区间均值
题目
给定一个长度为n的序列a,求a中有多少个区间,满足区间和在[L,R]范围内,输出"满足条件的区间数量" 和 "区间总数量"的最简比,若比值为0或1,直接输出0或1即可

样例
样例输入 1
4 2 3
3 1 2 4
样例输出 1
7/10
样例输入 2
4 1 4
3 1 2 4
样例输出 2
1
思路
以L为例,题目要求的是和在$ [L,R] $内的区间,那么我们可以考虑用总情况,减去不合法的情况,得到答案,以<L为例,化简原等式得:
区间和> R的情况同理:
我们用前缀和维护(a_i-L)和(a_i-R) ,原问题转化为求两个前缀和数组中"逆序对"和"顺序对"的数量
关于逆序对,用树状数组可以(O(n log n)) 实现(具体资料请上网查阅)
另外,需要注意的是,仅仅求逆序对和顺序对的数量是不够的,需要在读入的时候加入两条语句(下面第5第6行的两个if):
for(int i = 1 ; i <= n ; i++) {
int tmp = read();
sum1[i] = sum1[i - 1] + tmp - l;
sum2[i] = sum2[i - 1] + tmp - r;
if(sum1[i] < 0)++ans;//这两行
if(sum2[i] > 0)++ans;//
}
如果要知道原因,就要对上面的思路了解得足够透彻.我们求逆序对和顺序对的时候(下面仅以逆序对为例,顺序对同理),仅仅针对下标[1,n]的sum数组,但是却忽略了逆序对(i-1,j)是(sum_j - sum_i)的贡献也就是说,我们忽略了sum的最初值:0
下面举个例子;
5 2 3//数据
19 16 9 17 17
//依次为离散化前的sum1,sum2
17 31 38 53 68
16 29 35 49 63
//依次为离散化后的sum1,sum2
1 2 3 4 5
1 2 3 4 5
很显然,不论如何选区间,和都是不在[2,3]范围内的,或者说,和都是大于R的,所以,答案一定为0.但是放到程序里面(没有上面两个语句)就发现有问题,不说sum1是肯定不会产生贡献的,sum2的顺序对数量为10,但是确实没有算错,但是理论上两者的贡献加起来应该为15(所有的区间均不合法).这说明我们肯定漏了什么东西,现在我问你,以下区间所对应的顺序对是什么:[1,1],[1,2],[1,3],[1,4],[1,5],这就是我们漏掉的5个顺序对,可以直接加到sum数组里面考虑,也可以像上面那样直接计入答案
题解说一半不说一半的,搞得我想了一个下午,是我太菜了吗QAQ
最后,不要忘了开long long
代码
正解
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cstring>
#define nn 500010
#define ll long long
//#define int long long
using namespace std;
int read() {
int re = 0 , sig = 1;
char c = getchar();
while(c < '0' || c > '9') {
if(c == '-')sig = -1;
c = getchar();
}
while(c >= '0' && c <= '9')
re = (re << 1) + (re << 3) + c - '0',
c = getchar();
return re * sig;
}
int n , l , r;
struct TreeArray{//树状数组
ll a[nn];
#define lowbit(_) (_ & (-_))
inline void clear() {
memset(a , 0 , sizeof(a));
}
inline void update(int i , int pos) {
for( ; i <= n ; i += lowbit(i))
a[i] += pos;
}
inline ll GetSum(int i) {
ll sum = 0;
for( ; i > 0 ; i -= lowbit(i))
sum += a[i];
return sum;
}
}tra;
ll gcd(ll a , ll b) {
return b == 0 ? a : gcd(b , a % b);
}
int sum1[nn] , sum2[nn];
struct node {
int id , dat;
}tmp[nn];
bool cmp(node a , node b) {return a.dat < b.dat;}
void lsh(int *st) {//离散化
for(int i = 1 ; i <= n ; i++) {
tmp[i].id = i , tmp[i].dat = st[i];
}
sort(tmp + 1 , tmp + n + 1 , cmp);
int cnt = 0;
for(int i = 1 ; i <= n ; i++) {
if(tmp[i].dat != tmp[i - 1].dat || i == 1)++cnt;
st[tmp[i].id] = cnt;
}
return;
}
signed main() {
freopen("sequence.in" , "r" , stdin);
freopen("sequence.out" , "w" , stdout);
ll ans = 0;
n = read() , l = read() , r = read();
for(int i = 1 ; i <= n ; i++) {
int tmp = read();
sum1[i] = sum1[i - 1] + tmp - l;
sum2[i] = sum2[i - 1] + tmp - r;
if(sum1[i] < 0)++ans;
if(sum2[i] > 0)++ans;
}
lsh(sum1); lsh(sum2);
for(int i = n ; i > 0 ; i--) {//逆序对
ans += tra.GetSum(sum1[i] - 1);
tra.update(sum1[i] , 1);
}
tra.clear();
for(int i = 1 ; i <= n ; i++) {//顺序对
tra.update(sum2[i] , 1);
ans += tra.GetSum(sum2[i] - 1);
}
ll tot = 1ll * n * (n + 1ll) / 2;
ans = tot - ans;
if(ans == 0)puts("0");
else if(ans == tot) puts("1");
else {
ll g = gcd(ans , tot);
printf("%lld/%lld" , ans / g , tot / g);
}
return 0;
}
暴力
#include <iostream>
#define nn 500010
#define rr register
using namespace std;
int read() {
int re = 0 , sig = 1;
char c = getchar();
while(c < '0' || c > '9') {
if(c == '-')sig = -1;
c = getchar();
}
while(c >= '0' && c <= '9')
re = (re << 1) + (re << 3) + c - '0',
c = getchar();
return re * sig;
}
int n , l , r;
int a[nn];
int gcd(int a , int b) {
return b == 0 ? a : gcd(b , a % b);
}
int main() {
// freopen("sequence.in" , "r" , stdin);
// freopen("sequence.out" , "w" , stdout);
n = read() , l = read() , r = read();
for(rr int i = 1 ; i <= n ; i++)
a[i] = read();
rr int good = 0 , cnt = 0;
for(rr int i = 1 ; i <= n ; ++i) {
rr int sum = 0;
rr int len = 0;
for(rr int j = i ; j <= n ; ++j) {
++len;
sum += a[j];
if(l * len <= sum && sum <= r * len)
++good;
++cnt;
}
}
if(good == cnt || good == 0) {
printf("%d" , good == cnt ? 1 : 0);
return 0;
}
int g = gcd(good , cnt);
printf("%d/%d" , good / g , cnt / g);
return 0;
}
数据生成
#include <bits/stdc++.h>
#define ll long long
using namespace std;
ll random(ll r , ll l = 1) {
return l == r ? l : (ll)rand() * rand() % (r - l + 1) + l;
}
int main() {
unsigned seed;
cin >> seed;
seed *= time(0);
srand(seed);
int n = random(10000);
int l = random(100) , r = random(100);
if(l > r)swap(l , r);
printf("%d %d %d
" , n , l , r);
for(int i = 1 ; i <= n ; i++)
printf("%d " , random(150));
return 0;
}
最优路线
题目
给定一张n个点,m条边的有向图,每个点,每条边都有其权值,定义一条路径的最大权值为:路径上最大的点权×最大的边权
输出一个矩阵,i行j列表示i点到j点的最小路径权值
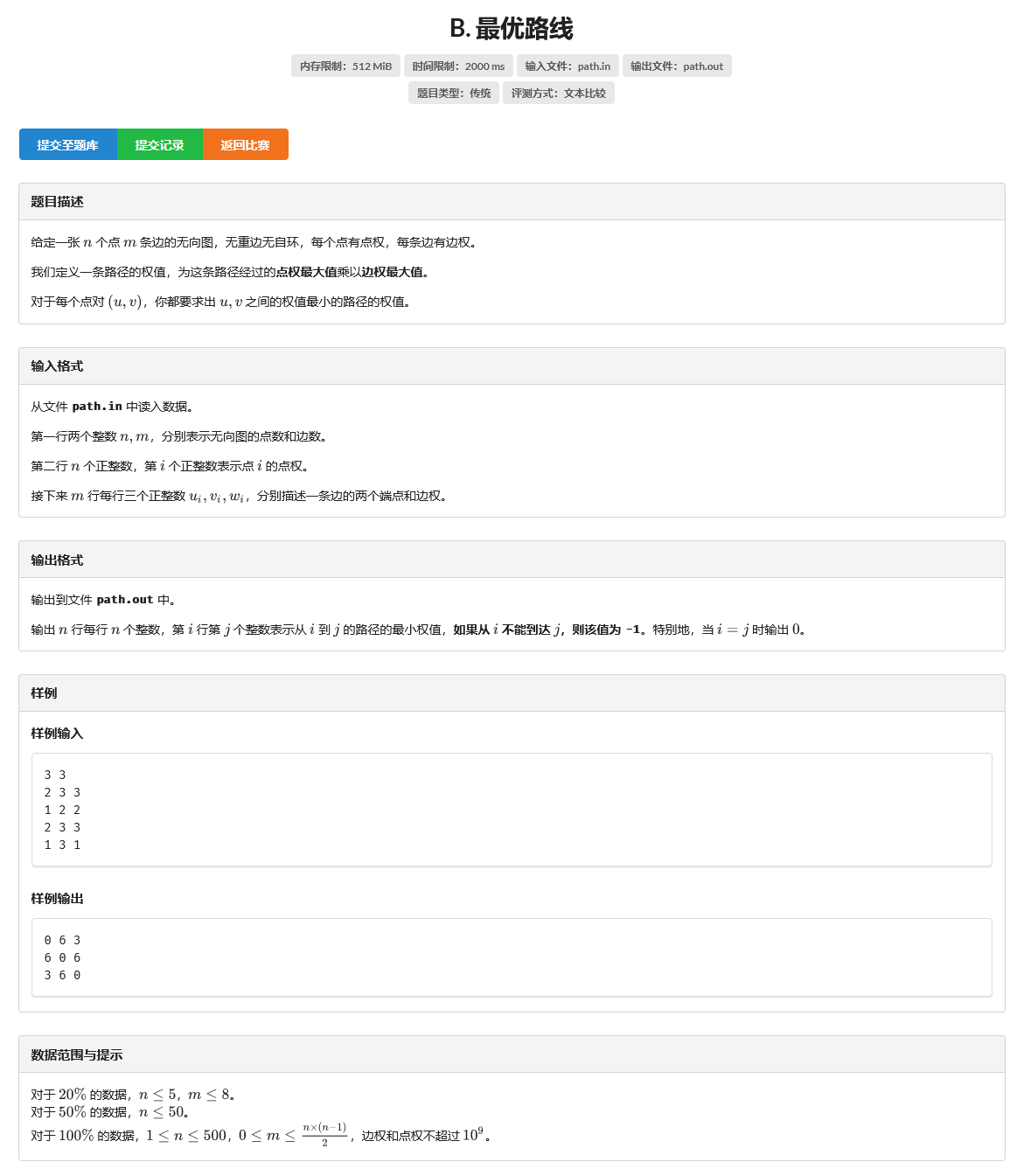
思路
不难想到floyd,但是告诉你,直接套入floyd的情况下,即使考虑了long long并且#define int long long只有20分(80%WA,0%TLE)
原因就出在第一层枚举的顺序,下面我们体验一下顺序的重要性:

图中绿色为边权,黑色为点权,蓝色为点的序号,红色为边试想从3到4的路径,最小权值为86*41=3526(3->1->4),但是从1到4的路径中,最小权值为12*58=696,也就是说i->k->j的路径中,"k->j"这一段并不一定是k到j的路径中权值最小的,那难道floyd就是错误的?
其实,只要我们按照点的权值,从小到大枚举k即可
代码
AC代码
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#define nn 510
#define ll long long
#define rr register
//#define int long long
#define min_(_,__) (_ < __ ? _ : __)
#define max_(_,__) (_ > __ ? _ : __)
using namespace std;
int read() {
int re = 0 , sig = 1;
char c = getchar();
while(c < '0' || c > '9') {
if(c == '-')sig = -1;
c = getchar();
}
while(c >= '0' && c <= '9')
re = (re << 1) + (re << 3) + c - '0',
c = getchar();
return re * sig;
}
struct node {
ll poi , ed , val;
}dis[nn][nn];
int n , m;
ll w[nn];
void output(ll x) {
if(x < 0) {
putchar('-');
x = -x;
}
if(x >= 10)output(x / 10ll);
putchar(x % 10ll + 48ll);
}
struct node2{
ll w , id;
}dict[nn];
bool cmp(node2 a , node2 b) {
return a.w < b.w;
}
signed main() {
// freopen("path.in" , "r" , stdin);
// freopen("path.out" , "w" , stdout);
n = read(); m = read();
memset(dis , -1 , sizeof(dis));
for(int i = 1 ; i <= n ; i++)
dict[i].w = w[i] = read() , dict[i].id = i;
for(int i = 1 ; i <= m ; i++) {
int u = read() , v = read() , edw = read();
dis[u][v].ed = edw;
dis[u][v].poi = max_(w[u] , w[v]);
dis[u][v].val = dis[u][v].ed * dis[u][v].poi;
dis[v][u] = dis[u][v];
}
sort(dict + 1 , dict + n + 1 , cmp);
for(rr int l = 1 ; l <= n ; ++l) {
int k = dict[l].id;
// k = l;
for(rr int i = 1 ; i <= n ; ++i) {
if(dis[i][k].ed == -1 || i == k) continue;
for(rr int j = i + 1 ; j <= n ; ++j) {
if(dis[i][k].ed == -1 || dis[k][j].ed == -1)continue;
ll edval = max_(dis[i][k].ed , dis[k][j].ed);
ll poival = max_(dis[i][k].poi , dis[k][j].poi);
if(dis[i][j].ed == -1 || (dis[i][j].val > edval * poival))
dis[i][j].val = ((dis[i][j].ed = edval) * (dis[i][j].poi = poival));
dis[j][i] = dis[i][j];
}
}
}
for(rr int i = 1 ; i <= n ; i++) {
for(rr int j = 1 ; j <= n ; j++) {
output(i == j ? 0ll : (dis[i][j].ed == -1 ? -1ll : dis[i][j].val));
putchar(' ');
}
putchar('
');
}
return 0;
}
数据生成
#include <bits/stdc++.h>
#define ll long long
using namespace std;
ll random(ll r , ll l = 1) {
return l == r ? l : (ll)rand() * rand() % (r - l + 1) + l;
}
map<pair<int ,int> , bool> h;
int main() {
unsigned seed;
cin >> seed;
seed *= time(0);
srand(seed);
int n = 5 , m = random(n * (n - 1) / 3 , 0);
printf("%d %d
" , n , m);
for(int i = 1 ; i <= n ; i++)
printf("%lld " , random(1e2));
putchar('
');
for(int i = 1 ; i <= m ; i++) {
int x , y;
do
x = random(n) , y = random(n);
while(h.find(make_pair(x , y)) != h.end() || x == y);
printf("%d %d %lld
" , x , y , random(1e2));
h[make_pair(x , y)] = true;
h[make_pair(y , x)] = true;
}
return 0;
}
连边方案
题解见下一题
弱者对决

