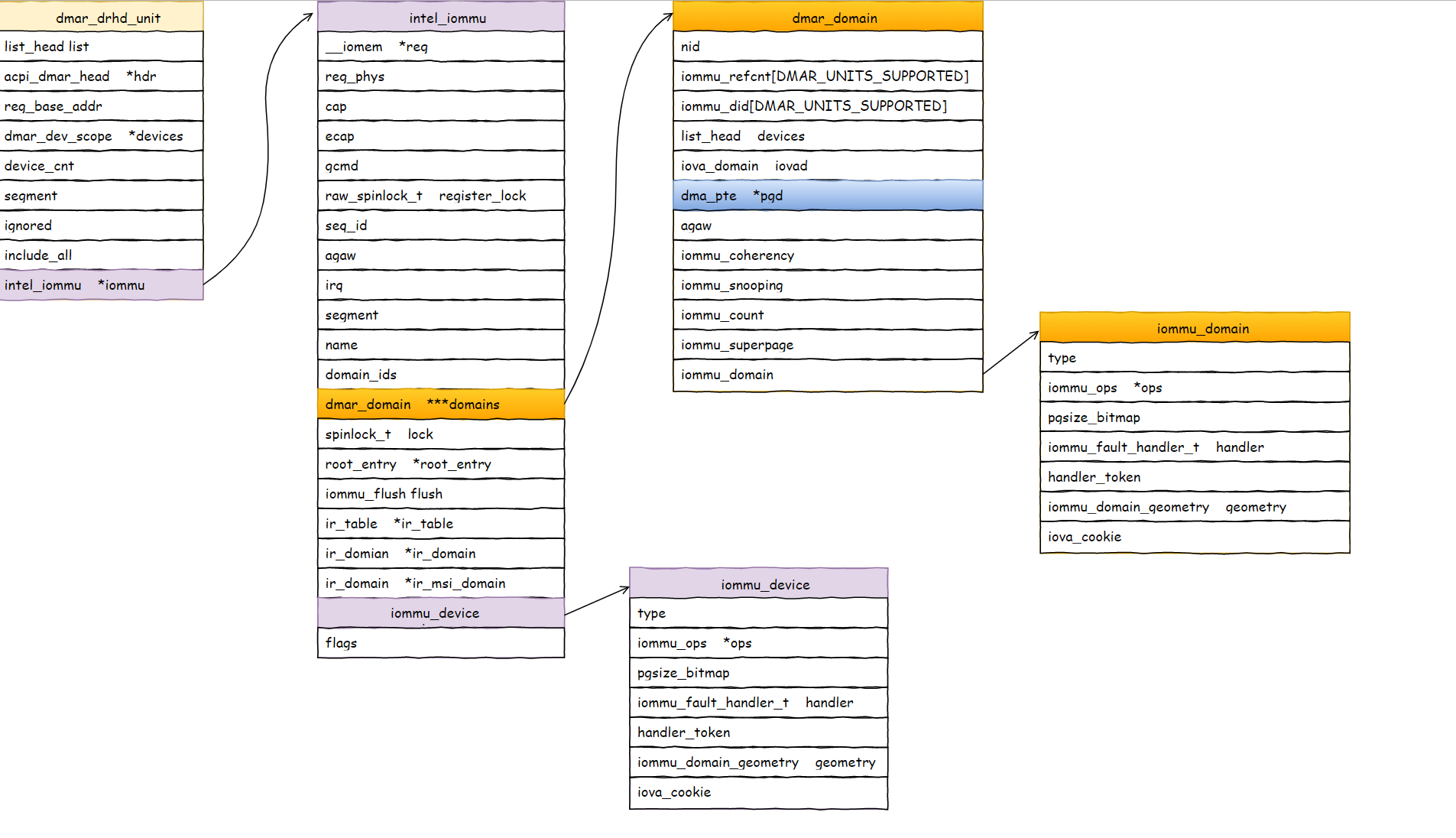
话说,盘古开天的时候,设备访问内存(DMA)就只接受物理地址,所以CPU要把一个地址告诉设备,就只能给物理地址。但设备的地址长度还比CPU的总线长度短,所以只能分配低地址来给设备用。所以CPU这边的接口就只有dma=dma_alloc(dev, size),分配了物理地址,然后映射为内核的va,然后把pa作为dma地址,CPU提供给设备,设备访问这个dma地址,就得到内存里面的那个数据了。
后来设备做强了,虽然地址总线不长,但可以带一个页表,把它能访问的有限长度的dma地址转换为和物理空间一样长的物理地址。这样就有了dma=dma_map(dev, va)。这样,其实我们对同一个物理地址就有三个地址的概念了:CPU看到的地址va,设备看到的地址dma,和总线看到的pa。
设备带个页表,这不就是mmu吗?于是,通用的iommu的概念(硬件上)就被发明了。所以dma_map(dev, va),在有iommu的设备上,就变成了对iommu的通用页表操作。iova=iommu_alloc(), iommu_map(domain, iova, pa);
这里我们发现了两个新概念,一个是iova,这个很好理解,就是原来的dma地址了(io的va嘛),另一个是domain,这本质是一个页表,为什么要把这个页表独立封装出来,这个我们很快会看到的。
我这个需要提醒一句,iommu用的页表,和mmu用的页表,不是同一个页表,为了容易区分,我们把前者叫做iopt,后者叫pt。两者都可以翻译虚拟地址为物理地址,物理地址是一样的,都是pa,而对于va,前者我们叫iova,后者我们叫va。
又到了后来,人们需要支持虚拟化,提出了VFIO的概念,需要在用户进程中直接访问设备,那我们就要支持在用户态直接发起DMA操作了,用户态发起DMA,它自己在分配iova,直接设置下来,要求iommu就用这个iova,那我内核对这个设备做dma_map,也要分配iova。这两者冲突怎么解决呢?
dma_map还可以避开用户态请求过的va空间,用户态的请求没法避开内核的dma_map的呀。
VFIO这样解决:默认情况下,iommu上会绑定一个default_domain,它具有IOMMU_DOMAIN_DMA属性,原来怎么弄就怎么弄,这时你可以调用dma_map()。但如果你要用VFIO,你就要先detach原来的驱动,改用VFIO的驱动,VFIO就给你换一个domain,这个domain的属性是IOMMU_DOMAIN_UNMANAGED,之后你爱用哪个iova就用那个iova,你自己保证不会冲突就好,VFIO通过iommu_map(domain, iova, pa)来执行这种映射。
等你从VFIO上detach,把你的domain删除了,这个iommu就会恢复原来的default_domain,这样你就可以继续用你的dma API了。
这种情况下,你必须给你的设备选一种应用模式,非此即彼。
很多设备,比如GPU,没有用VFIO,也会自行创建unmanaged的domain,自己管理映射,这个就变成一个通用的接口了。
好了,这个是Linux内核的现状(截止到4.20)。如果基于这个现状,我们要同时让用户态和内核态都可以做mapping的话,唯一的手段是使用unmanaged模式,然后va都从用户态分配(比如通过mmap),然后统一用iommu_map完成这个映射。
但实际上,Linux的这个框架,已经落后于硬件的发展了。因为现在大部分IOMMU,都支持多进程访问。比如我有两个进程同时从用户态访问设备,他们自己管理iova,这样,他们给iommu提供的iova就可能是冲突的。所以,IOMMU硬件同时支持多张iopt,用进程的id作为下标(对于PCIE设备来说,就是pasid了)。
这样,我们可以让内核使用pasid=0的iopt,每个用户进程用pasid=xxx的iopt,这样就互相不会冲突了。
为了支持这样的应用模式,ARM的Jean Philipse做了一套补丁,为domain增加pasid支持。他的方法是domain上可以bind多个pasid,bind的时候给你分配一个io_mm,然后你用iommu_sva_map()带上这个io_mm来做mapping。
这种情况下,你不再需要和dma api隔离了,因为他会自动用pasid=0(实际硬件不一定是这样的接口,这只是比喻)的iopt来做dma api,用其他pasid来做用户态。这时你也不再需要unmanaged的domain了。你继续用dma的domain,然后bind一个pasid上去即可。
但Jean这个补丁上传的时候正好遇到Intel的Scalable Virtual IO的补丁在上传,Intel要用这个特性来实现更轻量级的VFIO。原来的VFIO,是整个设备共享给用户态的,有了pasid这个概念,我可以基于pasid分配资源,基于pasid共享给用户态。但Jean的补丁要求使用的时候就要bind一个pasid上来。但VFIO是要分配完设备,等有进程用这个设备的时候才能提供pasid。
为了解决这个问题,Jean又加了一个aux domain的概念,你可以给一个iommu创建一个primary domain,和多个aux domain。那些aux domain可以晚点再绑定pasid上来。
后面这个变化,和前面的接口是兼容的,对我们来说都一样,我们只要有pasid用就可以了。
一些关键词:
- DMAR - DMA重映射
- DRHD - DMA重映射硬件单元定义
- RMRR - 预留内存区域报告结构
- ZLR - 从PCI设备读取零长度
- IOVA - IO虚拟地址。
基本的东西
ACPI枚举并列出平台中的不同DMA引擎,以及PCI设备与DMA引擎控制它们之间的设备范围关系。
什么是RMRR?
BIOS控制一些设备,例如USB设备执行PS2仿真。用于这些设备的存储区域在e820映射中标记为保留。当我们打开DMA转换时,DMA到这些区域将失败。因此,BIOS使用RMRR指定这些区域以及需要访问这些区域的设备。 OS希望为这些区域设置单位映射,以便这些设备访问这些区域。
IOVA是如何产生的?
表现良好的驱动程序在向需要执行DMA的设备发送命令之前调用pci_map _ *()调用。完成DMA并且不再需要映射后,设备将执行pci_unmap _ *()调用以取消映射该区域。
Intel IOMMU驱动程序为每个域分配一个虚拟地址。每个PCIE设备都有自己的域(因此保护)。 p2p网桥下的设备与p2p网桥下的所有设备共享虚拟地址(due to transaction id aliasing for p2p bridges)。
IOVA生成非常通用。我们使用与vmalloc()相同的技术,但这些不是全局地址空间,而是针对每个域分开。不同的DMA引擎可以支持不同数量的域。
我们还为每个映射分配了保护页面,因此我们可以尝试捕获可能发生的任何溢出。
硬件结构
先看下一个典型的X86物理服务器视图:

在多路服务器上我们可以有多个DMAR Unit(这里可以直接理解为多个IOMMU硬件), 每个DMAR会负责处理其下挂载设备的DMA请求进行地址翻译。例如上图中, PCIE Root Port (dev:fun) (14:0)下面挂载的所有设备的DMA请求由DMAR #1负责处理, PCIE Root Port (dev:fun) (14:1)下面挂载的所有设备的DMA请求由DMAR #2负责处理, 而DMAR #3下挂载的是一个Root-Complex集成设备[29:0],这个设备的DMA请求被DMAR #3承包, DMAR #4的情况比较复杂,它负责处理Root-Complex集成设备[30:0]以及I/OxAPIC设备的DMA请求。这些和IOMMU相关的硬件拓扑信息需要BIOS通过ACPI表呈现给OS,这样OS才能正确驱动IOMMU硬件工作。
关于硬件拓扑信息呈现,这里有几个概念需要了解一下:
-
DRHD: DMA Remapping Hardware Unit Definition 用来描述DMAR Unit(IOMMU)的基本信息
-
RMRR: Reserved Memory Region Reporting 用来描述那些保留的物理地址,这段地址空间不被重映射
-
ATSR: Root Port ATS Capability 仅限于有Device-TLB的情形,Root Port需要向OS报告支持ATS的能力
-
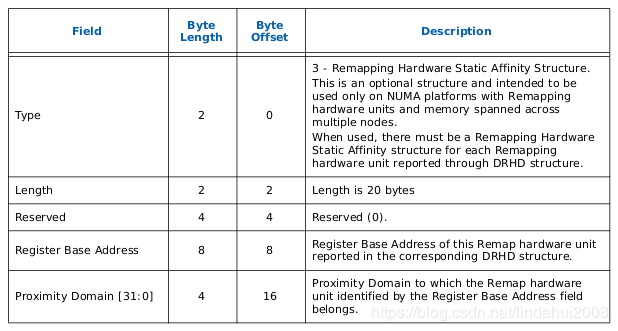
RHSA: Remapping Hardware Static Affinity Remapping亲和性,在有NUMA的系统下可以提升DMA Remapping的性能
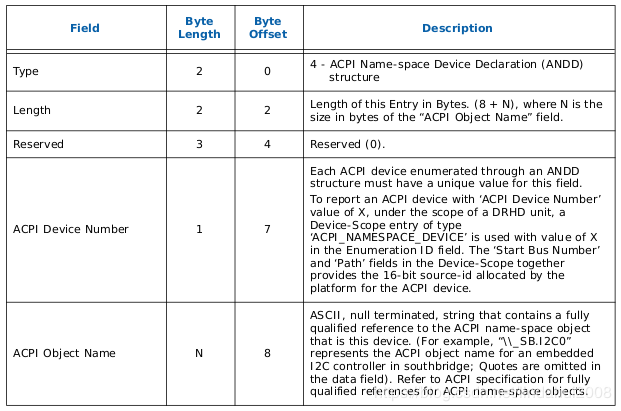
BIOS通过在ACPI表中提供一套DMA Remapping Reporting Structure 信息来表述物理服务器上的IOMMU拓扑信息, 这样OS在加载IOMMU驱动的时候就知道如何建立映射关系了
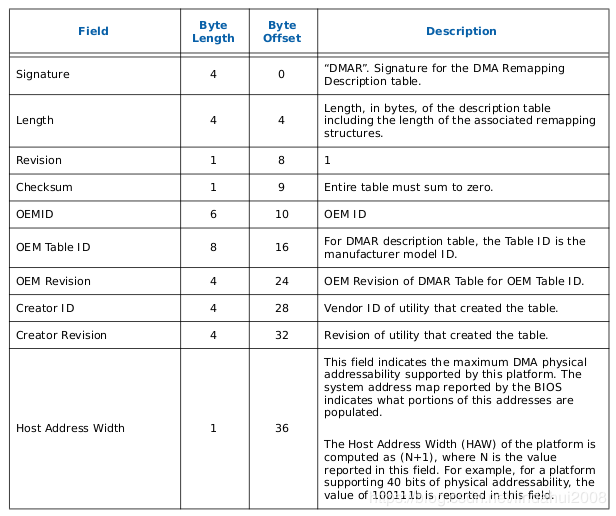
VT-d-----DMAR表组织结构
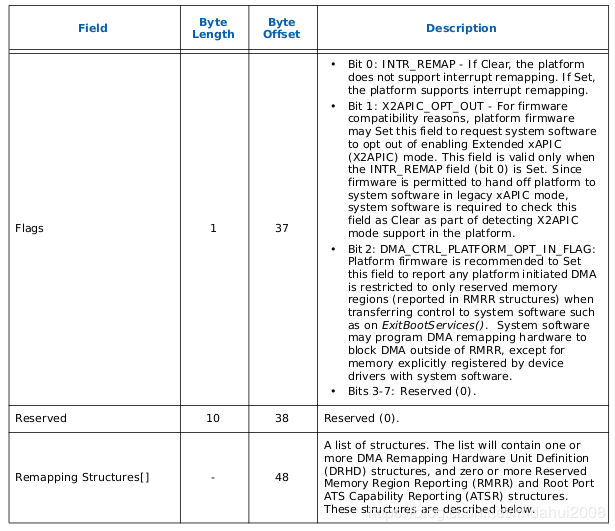
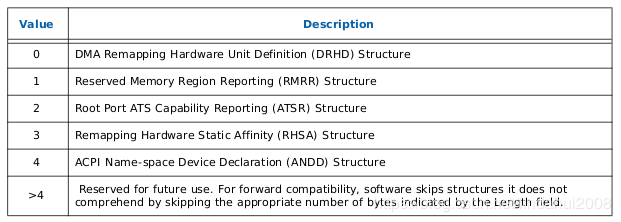
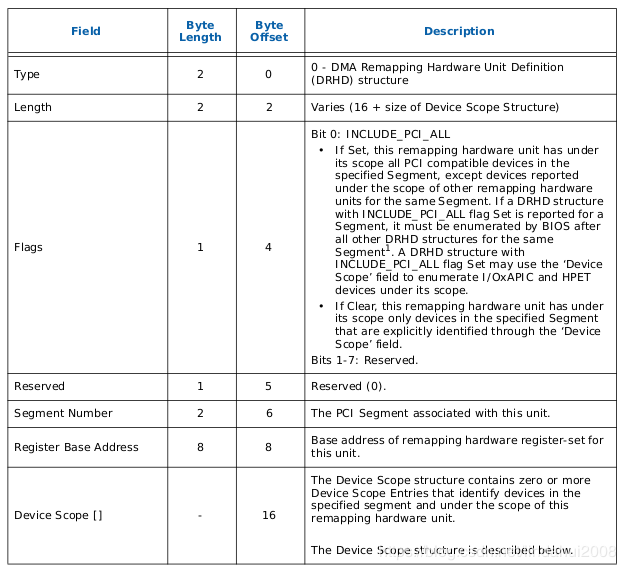
2. RMRR(Reserved Memory Region Reporting)表

3. ATSR(Root Port ATS Capability Reporting)表
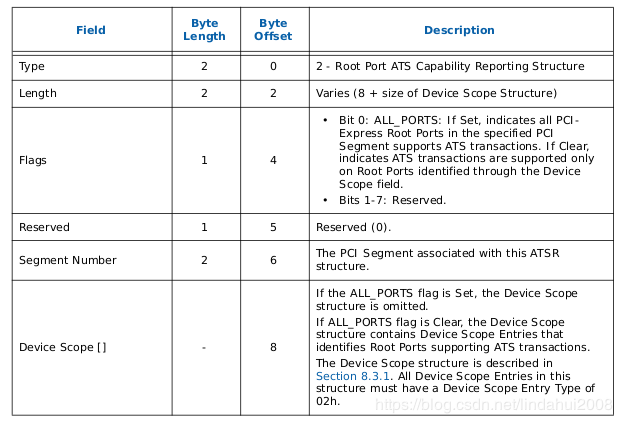
4. RHSA(Remapping Hardware Status Affinity)表