virtqueue 是 Guest操作系统内存的一部分,用作Guest和Host的数据传输缓存。
Host可以在Userspace实现(QEMU),也可以在内核态实现(vHost)。
比如,物理网卡收到发往虚拟机的数据包后,将其转发到对应的TAP设备。Qemu中TAP设备分为后端驱动和TAP设备关联,负责处理TAP设备的数据包;前端设备,负责将数据传送至虚拟机。具体是数据包到来,Qemu调用tap_send函数,将网络数据报通过e1000_receive函数写入网卡的缓存区,然后通过pci_dma_write将数据包拷贝至虚拟机对应的内存中。然后中断注入给虚拟机。虚拟机读取中断后引发VM-Exit,停止VM进程执行,进入root操作状态。KVM要根据KVM_EXIT_REASON判断原因。对于IO请求,其标志为KVM_EXIT_IO。因为kvm无法处理此操作,需要重新回到qemu的用户态,调用kvm_handle_io进行处理。
(gdb) bt #0 blk_aio_prwv (blk=0x558eef183e40, offset=0, bytes=0, iobuf=0x0, co_entry=0x558eedce7a28 <blk_aio_flush_entry>, flags=0, cb=0x558eedaad47c <ide_flush_cb>, opaque=0x558eefc24730) at block/block-backend.c:1360 #1 0x0000558eedce7ab1 in blk_aio_flush (blk=0x558eef183e40, cb=0x558eedaad47c <ide_flush_cb>, opaque=0x558eefc24730) at block/block-backend.c:1503 #2 0x0000558eedaad5da in ide_flush_cache (s=0x558eefc24730) at hw/ide/core.c:1088 #3 0x0000558eedaae5b3 in cmd_flush_cache (s=0x558eefc24730, cmd=231 '347') at hw/ide/core.c:1554 #4 0x0000558eedaaf8c5 in ide_exec_cmd (bus=0x558eefc246b0, val=231) at hw/ide/core.c:2085 #5 0x0000558eedaaddef in ide_ioport_write (opaque=0x558eefc246b0, addr=503, val=231) at hw/ide/core.c:1294 #6 0x0000558eed85cd3f in portio_write (opaque=0x558eefcbff30, addr=7, data=231, size=1) at /home/leon/qemu-4.2.0/ioport.c:201 #7 0x0000558eed861fbc in memory_region_write_accessor (mr=0x558eefcbff30, addr=7, value=0x7fa0e9cbb818, size=1, shift=0, mask=255, attrs=...) at /home/leon/qemu-4.2.0/memory.c:483 #8 0x0000558eed8621a6 in access_with_adjusted_size (addr=7, value=0x7fa0e9cbb818, size=1, access_size_min=1, access_size_max=4, access_fn=0x558eed861efc <memory_region_write_accessor>, mr=0x558eefcbff30, attrs=...) at /home/leon/qemu-4.2.0/memory.c:544 #9 0x0000558eed8650d7 in memory_region_dispatch_write (mr=0x558eefcbff30, addr=7, data=231, op=MO_8, attrs=...) at /home/leon/qemu-4.2.0/memory.c:1475 #10 0x0000558eed803386 in flatview_write_continue (fv=0x7fa0e410c970, addr=503, attrs=..., buf=0x7fa0f86ac000 "347200354�36", len=1, addr1=7, l=1, mr=0x558eefcbff30) at /home/leon/qemu-4.2.0/exec.c:3129 #11 0x0000558eed8034cb in flatview_write (fv=0x7fa0e410c970, addr=503, attrs=..., buf=0x7fa0f86ac000 "347200354�36", len=1) at /home/leon/qemu-4.2.0/exec.c:3169 #12 0x0000558eed803818 in address_space_write (as=0x558eee7a4b60 <address_space_io>, addr=503, attrs=..., buf=0x7fa0f86ac000 "347200354�36", len=1) at /home/leon/qemu-4.2.0/exec.c:3259 #13 0x0000558eed803885 in address_space_rw (as=0x558eee7a4b60 <address_space_io>, addr=503, attrs=..., buf=0x7fa0f86ac000 "347200354�36", len=1, is_write=true) at /home/leon/qemu-4.2.0/exec.c:3269 #14 0x0000558eed87cf9f in kvm_handle_io (port=503, attrs=..., data=0x7fa0f86ac000, direction=1, size=1, count=1) at /home/leon/qemu-4.2.0/accel/kvm/kvm-all.c:2104 #15 0x0000558eed87d737 in kvm_cpu_exec (cpu=0x558eef1b29b0) at /home/leon/qemu-4.2.0/accel/kvm/kvm-all.c:2350 #16 0x0000558eed853017 in qemu_kvm_cpu_thread_fn (arg=0x558eef1b29b0) at /home/leon/qemu-4.2.0/cpus.c:1318 #17 0x0000558eeddc042b in qemu_thread_start (args=0x558eef1da7e0) at util/qemu-thread-posix.c:519 #18 0x00007fa0f5a2a4a4 in start_thread () from /lib/x86_64-linux-gnu/libpthread.so.0 #19 0x00007fa0f576cd0f in clone () from /lib/x86_64-linux-gnu/libc.so.6
vhost
http://martinbj2008.github.io/2015/05/21/2015-05-21-vhost-net-study/
以guest VM发送一个报文为例
file: drivers/net/virtio_net.c > .ndo_start_xmi> > > > start_xmit, > > static netdev_tx_t start_xmit(struct sk_buff *skb, struct net_device *dev) > > > er> > xmit_skb(sq, skb); > > > > return virtqueue_add_outbuf(sq->vq, sq->sg, num_sg, skb, GFP_ATOMIC); > > > > > return virtqueue_add(vq, &sg, num, 1, 0, data, gfp); > > > virtqueue_kick(sq->vq); > > > > virtqueue_notify(vq); > > > > > vq->notify(_vq) > > > > > > iowrite16(vq->index, (void __iomem *)vq->priv);
前端驱动最终guest vm因io操作造成vm exit. host vm 调用vmx_handle_exit
vmx_handle_exit-->kvm_vmx_exit_handlers[exit_reason]-->handle_io-->kvm_fast_pio_out-->emulator_pio_out_emulated-->emulator_pio_in_out-->kernel_pio-->kvm_io_bus_write-->kvm_iodevice_write(dev->ops->write)-->ioeventfd_write-->eventfd_signal-->wake_up_locked_poll-->__wake_up_locked_key-->__wake_up_common-->vhost_poll_wakeup-->vhost_poll_queue-->vhost_work_queue-->wake_up_process
long vhost_vring_ioctl(struct vhost_dev *d, int ioctl, void __user *argp) { struct file *eventfp, *filep = NULL; bool pollstart = false, pollstop = false; struct eventfd_ctx *ctx = NULL; u32 __user *idxp = argp; struct vhost_virtqueue *vq; struct vhost_vring_state s; struct vhost_vring_file f; struct vhost_vring_addr a; u32 idx; long r; r = get_user(idx, idxp); if (r < 0) return r; if (idx >= d->nvqs) return -ENOBUFS; vq = d->vqs[idx]; mutex_lock(&vq->mutex); switch (ioctl) { case VHOST_SET_VRING_NUM: /* Resizing ring with an active backend? * You don't want to do that. */ if (vq->private_data) { r = -EBUSY; break; } if (copy_from_user(&s, argp, sizeof s)) { r = -EFAULT; break; } if (!s.num || s.num > 0xffff || (s.num & (s.num - 1))) { r = -EINVAL; break; } vq->num = s.num; break; case VHOST_SET_VRING_BASE: /* Moving base with an active backend? * You don't want to do that. */ if (vq->private_data) { r = -EBUSY; break; } if (copy_from_user(&s, argp, sizeof s)) { r = -EFAULT; break; } if (s.num > 0xffff) { r = -EINVAL; break; } vq->last_avail_idx = s.num; /* Forget the cached index value. */ vq->avail_idx = vq->last_avail_idx; break; case VHOST_GET_VRING_BASE: s.index = idx; s.num = vq->last_avail_idx; if (copy_to_user(argp, &s, sizeof s)) r = -EFAULT; break; case VHOST_SET_VRING_ADDR: if (copy_from_user(&a, argp, sizeof a)) { r = -EFAULT; break; } if (a.flags & ~(0x1 << VHOST_VRING_F_LOG)) { r = -EOPNOTSUPP; break; } /* For 32bit, verify that the top 32bits of the user data are set to zero. */ if ((u64)(unsigned long)a.desc_user_addr != a.desc_user_addr || (u64)(unsigned long)a.used_user_addr != a.used_user_addr || (u64)(unsigned long)a.avail_user_addr != a.avail_user_addr) { r = -EFAULT; break; } if ((a.avail_user_addr & (sizeof *vq->avail->ring - 1)) || (a.used_user_addr & (sizeof *vq->used->ring - 1)) || (a.log_guest_addr & (sizeof *vq->used->ring - 1))) { r = -EINVAL; break; } /* We only verify access here if backend is configured. * If it is not, we don't as size might not have been setup. * We will verify when backend is configured. */ if (vq->private_data) { if (!vq_access_ok(d, vq->num, (void __user *)(unsigned long)a.desc_user_addr, (void __user *)(unsigned long)a.avail_user_addr, (void __user *)(unsigned long)a.used_user_addr)) { r = -EINVAL; break; } /* Also validate log access for used ring if enabled. */ if ((a.flags & (0x1 << VHOST_VRING_F_LOG)) && !log_access_ok(vq->log_base, a.log_guest_addr, sizeof *vq->used + vq->num * sizeof *vq->used->ring)) { r = -EINVAL; break; } } vq->log_used = !!(a.flags & (0x1 << VHOST_VRING_F_LOG)); vq->desc = (void __user *)(unsigned long)a.desc_user_addr; vq->avail = (void __user *)(unsigned long)a.avail_user_addr; vq->log_addr = a.log_guest_addr; vq->used = (void __user *)(unsigned long)a.used_user_addr; break; case VHOST_SET_VRING_KICK: if (copy_from_user(&f, argp, sizeof f)) { r = -EFAULT; break; } eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd); if (IS_ERR(eventfp)) { r = PTR_ERR(eventfp); break; } if (eventfp != vq->kick) { pollstop = (filep = vq->kick) != NULL; pollstart = (vq->kick = eventfp) != NULL; } else filep = eventfp; break; case VHOST_SET_VRING_CALL: if (copy_from_user(&f, argp, sizeof f)) { r = -EFAULT; break; } eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd); if (IS_ERR(eventfp)) { r = PTR_ERR(eventfp); break; } if (eventfp != vq->call) { filep = vq->call; ctx = vq->call_ctx; vq->call = eventfp; vq->call_ctx = eventfp ? eventfd_ctx_fileget(eventfp) : NULL; } else filep = eventfp; break; case VHOST_SET_VRING_ERR: if (copy_from_user(&f, argp, sizeof f)) { r = -EFAULT; break; } eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd); if (IS_ERR(eventfp)) { r = PTR_ERR(eventfp); break; } if (eventfp != vq->error) { filep = vq->error; vq->error = eventfp; ctx = vq->error_ctx; vq->error_ctx = eventfp ? eventfd_ctx_fileget(eventfp) : NULL; } else filep = eventfp; break; default: r = -ENOIOCTLCMD; } if (pollstop && vq->handle_kick) vhost_poll_stop(&vq->poll); if (ctx) eventfd_ctx_put(ctx); if (filep) fput(filep); if (pollstart && vq->handle_kick) r = vhost_poll_start(&vq->poll, vq->kick); mutex_unlock(&vq->mutex); if (pollstop && vq->handle_kick) vhost_poll_flush(&vq->poll); return r; }
kvm_handle_io调用cpu_outb, cpu_outw等指令处理IO操作.
Para-virtualization(半虚拟化)
可以认为是一种改进后的仿真模型,由各厂商提供虚拟网卡驱动,并加入Guest OS。vhost driver创建了一个字符设备 /dev/vhost-net,这个设备可以被用户空间打开,并可以被ioctl命令操作。当给一个Qemu进程传递了参数-netdev tap,vhost=on 的时候,QEMU会通过调用几个ioctl命令对这个文件描述符进行一些初始化的工作,然后进行特性的协商,从而宿主机跟客户机的vhost-net driver建立关系。与此同时,kernel中要创建一个kernel thread 用于处理I/O事件和设备的模拟。 kernel代码 drivers/vhost/vhost.c:在vhost_dev_set_owner中,调用了这个函数用于创建worker线程(线程名字为vhost-qemu+进程pid)。这个内核线程被称为"vhost worker thread",该worker thread的任务即为处理virtio的I/O事件。而在Guest中,会打开virtio设备,将virtio的vring映射到host kernel。vhost与kvm的事件通信通过eventfd机制来实现,主要包括两个方向的event,一个是Guest到Vhost方向的kick event,通过ioeventfd承载;另一个是Vhost到Guest方向的call event,通过irqfd承载。
guest_notifier的使用:
- vhost在处理完请求(收到数据包),将buffer放到used ring上面之后,往call fd里面写入;
- 如果成功设置了irqfd,则kvm会直接中断guest。如果没有成功设置,则走以下的路径:
Qemu通过select调用监听到该事件(因为vhost的callfd就是qemu里面对应vq的guest_notifier,它已经被加入到selectablefd列表);
- 调用virtio_pci_guest_notifier_read通知guest;
- guest从used ring上获取相关的数据。
host_notifier的使用:
- Guest中的virtio设备将数据放入avail ring上面后,写发送命令至virtio pci配置空间;
- Qemu截获寄存器的访问,调用注册的kvm_memory_listener中的eventfd_add回调函数kvm_eventfd_add();
- 通过kvm_vm_ioctl(kvm_state, KVM_IOEVENTFD, &kick)进入kvm中;
- kvm唤醒挂载在ioeventfd上vhost worker thread;
- vhost worker thread从avail ring上获取相关数据。

当open/dev/vhost-net设备的时候,会执行vhost-net-open函数,该函数首先为vqueue的收发队列分别设置一个handle_kick函数; static int vhost_net_open(struct inode *inode, struct file *f) { struct vhost_net *n; struct vhost_dev *dev; struct vhost_virtqueue **vqs; int i; n = kvmalloc(sizeof *n, GFP_KERNEL | __GFP_REPEAT); if (!n) return -ENOMEM; vqs = kmalloc(VHOST_NET_VQ_MAX * sizeof(*vqs), GFP_KERNEL); if (!vqs) { kvfree(n); return -ENOMEM; } dev = &n->dev; vqs[VHOST_NET_VQ_TX] = &n->vqs[VHOST_NET_VQ_TX].vq; vqs[VHOST_NET_VQ_RX] = &n->vqs[VHOST_NET_VQ_RX].vq; n->vqs[VHOST_NET_VQ_TX].vq.handle_kick = handle_tx_kick; n->vqs[VHOST_NET_VQ_RX].vq.handle_kick = handle_rx_kick; for (i = 0; i < VHOST_NET_VQ_MAX; i++) { n->vqs[i].ubufs = NULL; n->vqs[i].ubuf_info = NULL; n->vqs[i].upend_idx = 0; n->vqs[i].done_idx = 0; n->vqs[i].vhost_hlen = 0; n->vqs[i].sock_hlen = 0; } vhost_dev_init(dev, vqs, VHOST_NET_VQ_MAX); vhost_poll_init(n->poll + VHOST_NET_VQ_TX, handle_tx_net, POLLOUT, dev); vhost_poll_init(n->poll + VHOST_NET_VQ_RX, handle_rx_net, POLLIN, dev); f->private_data = n; return 0;
然后在执行vhost设备的初始化vhost_dev_init,在该函数里最终调用vhost_work_init将work->fn设置为刚才设置的handle_kick函数。这样,当vhost线程被唤醒的时候就会执行handle_kick函数(handle_tx_kick、handle_rx_kick)。 handle_tx_kick里将消息包从vringbuffer里取出来,调用send_msg发送出去
1、 QEMU/KVM中中断模拟实现框架
https://kernelgo.org/virtio-overview.html
如果对QEMU/KVM中断模拟不熟悉的童鞋, 建议阅读一下这篇文章:QEMU学习笔记-中断。 对于virtio-pci设备,可以通过Cap呈现MSIx给虚拟机,这样在前端驱动加载的时候就会尝试去使能MSIx中断, 后端在这个时候建立起MSIx通道。
前端驱动加载(probe)的过程中,会去初始化virtqueue,这个时候会去申请MSIx中断并注册中断处理函数:
irtnet_probe --> init_vqs --> virtnet_find_vqs --> vi->vdev->config->find_vqs [vp_modern_find_vqs] --> vp_find_vqs --> vp_find_vqs_msix // 为每virtqueue申请一个MSIx中断,通常收发各一个队列 --> vp_request_msix_vectors // 主要的MSIx中断申请逻辑都在这个函数里面 --> pci_alloc_irq_vectors_affinity // 申请MSIx中断描述符(__pci_enable_msix_range) --> request_irq // 注册中断处理函数 // virtio-net网卡至少申请了3个MSIx中断: // 一个是configuration change中断(配置空间发生变化后,QEMU通知前端) // 发送队列1个MSIx中断,接收队列1MSIx中断
1.1 在QEMU/KVM这一侧,开始模拟MSIx中断,具体流程大致如下:
--> virtio_ioport_write --> virtio_set_status --> virtio_net_vhost_status --> vhost_net_start -----------------vhost --> virtio_pci_set_guest_notifiers --> kvm_virtio_pci_vector_use ------------vhost |--> kvm_irqchip_add_msi_route //更新中断路由表 |--> kvm_virtio_pci_irqfd_use //使能MSI中断 --> kvm_irqchip_add_irqfd_notifier_gsi --> kvm_irqchip_assign_irqfd # 申请MSIx中断的时候,会为MSIx分配一个gsi,并为这个gsi绑定一个irqfd,然后调用ioctl KVM_IRQFD注册到内核中。 static int kvm_irqchip_assign_irqfd(KVMState *s, int fd, int rfd, int virq, bool assign) { struct kvm_irqfd irqfd = { .fd = fd, .gsi = virq, .flags = assign ? 0 : KVM_IRQFD_FLAG_DEASSIGN, }; if (rfd != -1) { irqfd.flags |= KVM_IRQFD_FLAG_RESAMPLE; irqfd.resamplefd = rfd; } if (!kvm_irqfds_enabled()) { return -ENOSYS; } return kvm_vm_ioctl(s, KVM_IRQFD, &irqfd); } # KVM内核代码virt/kvm/eventfd.c kvm_vm_ioctl(s, KVM_IRQFD, &irqfd) --> kvm_irqfd_assign --> vfs_poll(f.file, &irqfd->pt) // 在内核中poll这个irqfd
从上面的流程可以看出,QEMU/KVM使用irqfd机制来模拟MSIx中断, 即设备申请MSIx中断的时候会为MSIx分配一个gsi(这个时候会刷新irq routing table), 并为这个gsi绑定一个irqfd,最后在内核中去poll这个irqfd。 当QEMU处理完IO之后,就写MSIx对应的irqfd,给前端注入一个MSIx中断,告知前端我已经处理好IO了你可以来取结果了。
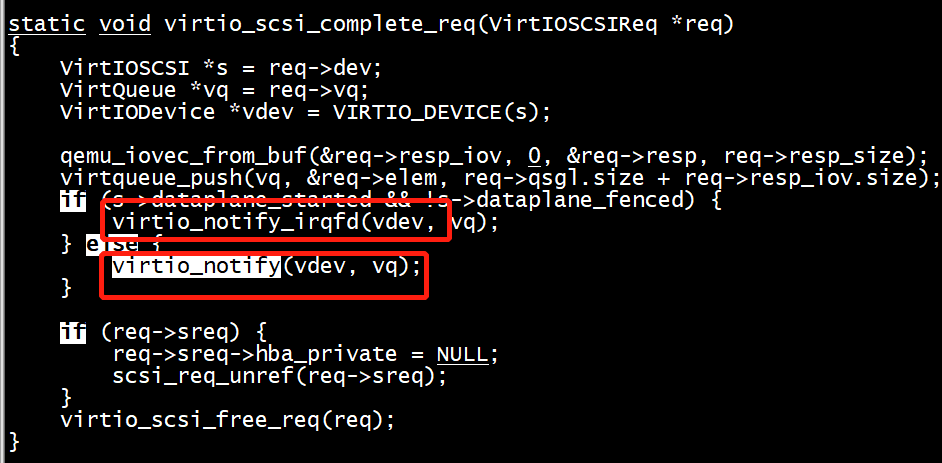
例如,virtio-scsi从前端取出IO请求后会取做DMA操作(DMA是异步的,QEMU协程中负责处理)。 当DMA完成后QEMU需要告知前端IO请求已完成(Complete),那么怎么去投递这个MSIx中断呢? 答案是调用virtio_notify_irqfd注入一个MSIx中断。
#0 0x00005604798d569b in virtio_notify_irqfd (vdev=0x56047d12d670, vq=0x7fab10006110) at hw/virtio/virtio.c:1684 #1 0x00005604798adea4 in virtio_scsi_complete_req (req=0x56047d09fa70) at hw/scsi/virtio-scsi.c:76 #2 0x00005604798aecfb in virtio_scsi_complete_cmd_req (req=0x56047d09fa70) at hw/scsi/virtio-scsi.c:468 #3 0x00005604798aee9d in virtio_scsi_command_complete (r=0x56047ccb0be0, status=0, resid=0) at hw/scsi/virtio-scsi.c:495 #4 0x0000560479b397cf in scsi_req_complete (req=0x56047ccb0be0, status=0) at hw/scsi/scsi-bus.c:1404 #5 0x0000560479b2b503 in scsi_dma_complete_noio (r=0x56047ccb0be0, ret=0) at hw/scsi/scsi-disk.c:279 #6 0x0000560479b2b610 in scsi_dma_complete (opaque=0x56047ccb0be0, ret=0) at hw/scsi/scsi-disk.c:300 #7 0x00005604799b89e3 in dma_complete (dbs=0x56047c6e9ab0, ret=0) at dma-helpers.c:118 #8 0x00005604799b8a90 in dma_blk_cb (opaque=0x56047c6e9ab0, ret=0) at dma-helpers.c:136 #9 0x0000560479cf5220 in blk_aio_complete (acb=0x56047cd77d40) at block/block-backend.c:1327 #10 0x0000560479cf5470 in blk_aio_read_entry (opaque=0x56047cd77d40) at block/block-backend.c:1387 #11 0x0000560479df49c4 in coroutine_trampoline (i0=2095821104, i1=22020) at util/coroutine-ucontext.c:115 #12 0x00007fab214d82c0 in __start_context () at /usr/lib64/libc.so.6
在virtio_notify_irqfd函数中,会去写irqfd,给内核发送一个信号。
具体通知方式:
前面已经提到前端或者后端完成某个操作需要通知另一端的时候需要某种notify机制。这个notify机制是啥呢?这里分为两个方向
1、guest->host
前面也已经介绍,当前端想通知后端时,会调用virtqueue_kick函数,继而调用virtqueue_notify,对应virtqueue结构中的notify函数,在初始化的时候被初始化成vp_notify(virtio_pci.c中),看下该函数的实现

static void vp_notify(struct virtqueue *vq)
{
struct virtio_pci_device *vp_dev = to_vp_device(vq->vdev);
/* we write the queue's selector into the notification register to
* signal the other end */
iowrite16(vq->index, vp_dev->ioaddr + VIRTIO_PCI_QUEUE_NOTIFY);
}
可以看到这里仅仅是吧vq的index编号写入到设备的IO地址空间中,实际上就是设备对应的PCI配置空间中VIRTIO_PCI_QUEUE_NOTIFY位置。这里执行IO操作会引发VM-exit,继而退出到KVM->qemu中处理。看下后端驱动的处理方式。在qemu代码中virtio-pci.c文件中有函数virtio_ioport_write专门处理前端驱动的IO写操作,看
case VIRTIO_PCI_QUEUE_NOTIFY:
if (val < VIRTIO_PCI_QUEUE_MAX) {
virtio_queue_notify(vdev, val);
}
break;
这里首先判断队列号是否在合法范围内,然后调用virtio_queue_notify函数,而最终会调用到virtio_queue_notify_vq,该函数其实仅仅调用了VirtQueue结构中绑定的处理函数handle_output,该函数根据不同的设备有不同的实现,比如网卡有网卡的实现,而块设备有块设备的实现。以网卡为例看看创建VirtQueue的时候给绑定的是哪个函数。在virtio-net,c中的virtio_net_init,可以看到这里给接收队列绑定的是virtio_net_handle_rx,而给发送队列绑定的是virtio_net_handle_tx_bh或者virtio_net_handle_tx_timer。而对于块设备则对应的是virtio_blk_handle_output函数。
2、host->guest
host通知guest当然是通过注入中断的方式,首先调用的是virtio_notify,继而调用virtio_notify_vector并把中断向量作为参数传递进去。这里就调用了设备关联的notify函数,具体实现为virtio_pci_notify函数,常规中断(非MSI)会调用qemu_set_irq,在8259a中断控制器的情况下回调用kvm_pic_set_irq,然后到了kvm_set_irq,这里就会通过kvm_vm_ioctl和KVM交互,接口为KVM_IRQ_LINE,通知KVM对guest进行中断的注入。KVm里的kvm_vm_ioctl函数会对此调用进行处理,具体就是调用kvm_vm_ioctl_irq_line,之后就调用kvm_set_irq函数进行注入了。之后的流程参看中断虚拟化部分。
virtio_notify_irqfd & virtio_notify
void virtio_notify_irqfd(VirtIODevice *vdev, VirtQueue *vq) { WITH_RCU_READ_LOCK_GUARD() { if (!virtio_should_notify(vdev, vq)) { return; } } trace_virtio_notify_irqfd(vdev, vq); /* * virtio spec 1.0 says ISR bit 0 should be ignored with MSI, but * windows drivers included in virtio-win 1.8.0 (circa 2015) are * incorrectly polling this bit during crashdump and hibernation * in MSI mode, causing a hang if this bit is never updated. * Recent releases of Windows do not really shut down, but rather * log out and hibernate to make the next startup faster. Hence, * this manifested as a more serious hang during shutdown with * * Next driver release from 2016 fixed this problem, so working around it * is not a must, but it's easy to do so let's do it here. * * Note: it's safe to update ISR from any thread as it was switched * to an atomic operation. */ virtio_set_isr(vq->vdev, 0x1); event_notifier_set(&vq->guest_notifier); } static void virtio_irq(VirtQueue *vq) { virtio_set_isr(vq->vdev, 0x1); virtio_notify_vector(vq->vdev, vq->vector); }
virtio_notify
static void virtio_irq(VirtQueue *vq) { virtio_set_isr(vq->vdev, 0x1); virtio_notify_vector(vq->vdev, vq->vector); } void virtio_notify(VirtIODevice *vdev, VirtQueue *vq) { WITH_RCU_READ_LOCK_GUARD() { if (!virtio_should_notify(vdev, vq)) { return; } } trace_virtio_notify(vdev, vq); virtio_irq(vq); }
virtio backend solution vhost
vhost is another solution of virtio, used to skip qemu and reduce the overhead of context switching between qemu and the kernel, especially for network IO. There are currently two implementations of vhost, kernel mode and user mode. This article focuses on kernel mode vhost
The vhost kernel module mainly handles the data plane, and the control plane is still handed over to qemu. The data structure of vhost is as follows
struct vhost_dev {
MemoryListener memory_listener;/* MemoryListener is a collection of callback functions for physical memory operations */
struct vhost_memory * mem;
int n_mem_sections;
MemoryRegionSection * mem_sections;
struct vhost_virtqueue * vqs;/* vhost_virtqueue list and number */
int nvqs;
/* the first virtuque which would be used by this vhost dev */
int vq_index;
unsigned long long features;/* features supported by vhost device */
unsigned long long acked_features;/* guest acked features */
unsigned long long backend_features;/* backend, eg tap device, supported features */
bool started;
bool log_enabled;
vhost_log_chunk_t * log;
unsigned long long log_size;
Error * migration_blocker;
bool force;
bool memory_changed;
hwaddr mem_changed_start_addr;
hwaddr mem_changed_end_addr;
const VhostOps * vhost_ops;/* VhostOps has different implementations based on the two forms of kernel and user. The implementation of the kernel is finally completed by calling ioctl */
void * opaque;
};
struct vhost_virtqueue {
int kick;
int call;
void * desc;
void * avail;
void * used;
int num;
unsigned long long used_phys;
unsigned used_size;
void * ring;
unsigned long long ring_phys;
unsigned ring_size;
EventNotifier masked_notifier;
};
The memory layout of vhost is also composed of a set of vhost_memory_region,
struct vhost_memory_region {
__u64 guest_phys_addr;
__u64 memory_size;/* bytes */
__u64 userspace_addr;
__u64 flags_padding;/* No flags are currently specified. */
};
/* All region addresses and sizes must be 4K aligned. */
#define VHOST_PAGE_SIZE 0x1000
struct vhost_memory {
__u32 nregions;
__u32 padding;
struct vhost_memory_region regions[0];
};
The control plane of vhost is controlled by qemu, and the kernel module of vhost_xxx is operated by ioctl, eg
long vhost_dev_ioctl(struct vhost_dev *d, unsigned int ioctl, unsigned long arg)
{
void __user *argp = (void __user *)arg;
struct file *eventfp, *filep = NULL;
struct eventfd_ctx *ctx = NULL;
u64 p;
long r;
int i, fd;
/* If you are not the owner, you can become one */
if (ioctl == VHOST_SET_OWNER) {
r = vhost_dev_set_owner(d);
goto done;
}
/* You must be the owner to do anything else */
r = vhost_dev_check_owner(d);
if (r)
goto done;
switch (ioctl) {
case VHOST_SET_MEM_TABLE:
r = vhost_set_memory(d, argp);
break;
...
default:
r = vhost_set_vring(d, ioctl, argp);
break;
}
done:
return r;
}
VHOST_SET_OWNER, used to associate the qemu process corresponding to the current guest with the vhost kernel thread
VHOST_SET_OWNER
/* Caller should have device mutex */
static long vhost_dev_set_owner (struct vhost_dev * dev)
{
struct task_struct * worker;
int err;
/* Is there an owner already? */
if (dev-> mm) {
err = -EBUSY;
goto err_mm;
}
/* No owner, become one */
dev-> mm = get_task_mm (current);/* Get the mm_struct of the qemu process, which is the memory distribution structure of the guest
worker = kthread_create (vhost_worker, dev, "vhost-% d", current-> pid);/* Create vhost thread */
if (IS_ERR (worker)) {
err = PTR_ERR (worker);
goto err_worker;
}
dev-> worker = worker;
wake_up_process (worker);/* avoid contributing to loadavg */
err = vhost_attach_cgroups (dev);
if (err)
goto err_cgroup;
err = vhost_dev_alloc_iovecs (dev);/* allocate iovec memory space for vhost_virtqueue */
if (err)
goto err_cgroup;
return 0;
err_cgroup:
kthread_stop (worker);
dev-> worker = NULL;
err_worker:
if (dev-> mm)
mmput (dev-> mm);
dev-> mm = NULL;
err_mm:
return err;
}
VHOST_SET_MEM_TABLE, initialize vhost_memory memory member of vhost_devstatic long vhost_set_memory (struct vhost_dev * d, struct vhost_memory __user * m)
{
struct vhost_memory mem, * newmem, * oldmem;
unsigned long size = offsetof (struct vhost_memory, regions);
if (copy_from_user (& mem, m, size))
return -EFAULT;
if (mem.padding)
return -EOPNOTSUPP;
if (mem.nregions> VHOST_MEMORY_MAX_NREGIONS)
return -E2BIG;
newmem = kmalloc (size + mem.nregions * sizeof * m-> regions, GFP_KERNEL);/* allocate multiple vhost_memory_region */
if (! newmem)
return -ENOMEM;
memcpy (newmem, & mem, size);
if (copy_from_user (newmem-> regions, m-> regions,
mem.nregions * sizeof * m-> regions)) {
kfree (newmem);
return -EFAULT;
}
if (! memory_access_ok (d, newmem, vhost_has_feature (d, VHOST_F_LOG_ALL))) {
kfree (newmem);
return -EFAULT;
}
oldmem = d-> memory;
rcu_assign_pointer (d-> memory, newmem);
synchronize_rcu ();
kfree (oldmem);
return 0;
}
VHOST_GET_FEATURES, VHOST_SET_FEATURES, used to read and write features supported by vhost, currently only used by vhost_net module,
enum {
VHOST_FEATURES = (1ULL << VIRTIO_F_NOTIFY_ON_EMPTY) |
(1ULL << VIRTIO_RING_F_INDIRECT_DESC) |
(1ULL << VIRTIO_RING_F_EVENT_IDX) |
(1ULL << VHOST_F_LOG_ALL) |
(1ULL << VHOST_NET_F_VIRTIO_NET_HDR) |
(1ULL << VIRTIO_NET_F_MRG_RXBUF),
};
static long vhost_net_ioctl(struct file *f, unsigned int ioctl,
unsigned long arg)
{
....
case VHOST_GET_FEATURES:
features = VHOST_FEATURES;
if (copy_to_user(featurep, &features, sizeof features))
return -EFAULT;
return 0;
case VHOST_SET_FEATURES:
if (copy_from_user(&features, featurep, sizeof features))
return -EFAULT;
if (features & ~VHOST_FEATURES)
return -EOPNOTSUPP;
return vhost_net_set_features(n, features);
....
}
VHOST_SET_VRING_CALL, set irqfd, and inject the interrupt into the guest
VHOST_SET_VRING_KICK, set ioeventfd, get guest notify
case VHOST_SET_VRING_KICK:
if (copy_from_user (& f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1? NULL: eventfd_fget (f.fd);
if (IS_ERR (eventfp)) {
r = PTR_ERR (eventfp);
break;
}
if (eventfp! = vq-> kick) {/* eventfp is different from vq-> kick, you need to stop vq-> kick and start eventfp at the same time */
pollstop = filep = vq-> kick;
pollstart = vq-> kick = eventfp;
} else
filep = eventfp;/* Both are the same, no stop & start */
break;
case VHOST_SET_VRING_CALL:
if (copy_from_user (& f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1? NULL: eventfd_fget (f.fd);
if (IS_ERR (eventfp)) {
r = PTR_ERR (eventfp);
break;
}
if (eventfp! = vq-> call) {/* eventfp is different from vq-> call, then you need to stop vq-> call and start eventfp */
filep = vq-> call;
ctx = vq-> call_ctx;
vq-> call = eventfp;
vq-> call_ctx = eventfp?
eventfd_ctx_fileget (eventfp): NULL;
} else
filep = eventfp;
break;
if (pollstop && vq-> handle_kick)
vhost_poll_stop (& vq-> poll);
if (ctx)
eventfd_ctx_put (ctx);/* After pollstop, release the previously used ctx */
if (filep)
fput (filep);/* After pollstop, release the previously occupied filep */
if (pollstart && vq-> handle_kick)
vhost_poll_start (& vq-> poll, vq-> kick);
mutex_unlock (& vq-> mutex);
if (pollstop && vq-> handle_kick)
vhost_poll_flush (& vq-> poll);
return r;
Let's take a look at the data flow of vhost. Eventvd is implemented between vhost and kvm module. The kick event from guest to host is implemented through ioeventfd. The call event from host to guest is implemented through irqfd.host to guest direction
First, the host processes the used ring, and then judges that if KVM_IRQFD is successfully set, the kvm module will inject the interrupt into the guest through irqfd. qemu is via virtio_pci_set_guest_notifiers-> kvm_virtio_pci_vector_use-> kvm_virtio_pci_irqfd_use-> kvm_irqchip_add_irqfd_notifier-> kvm_irqchip_assign_irqfd including fvm and kvm_fird of fq (d) and fvm (kfd)
static int kvm_virtio_pci_vector_use(VirtIOPCIProxy *proxy, int nvqs)
{
PCIDevice *dev = &proxy->pci_dev;
VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);
VirtioDeviceClass *k = VIRTIO_DEVICE_GET_CLASS(vdev);
unsigned int vector;
int ret, queue_no;
MSIMessage msg;
for (queue_no = 0; queue_no < nvqs; queue_no++) {
if (!virtio_queue_get_num(vdev, queue_no)) {
break;
}
vector = virtio_queue_vector(vdev, queue_no);
if (vector >= msix_nr_vectors_allocated(dev)) {
continue;
}
msg = msix_get_message(dev, vector);
ret = kvm_virtio_pci_vq_vector_use(proxy, queue_no, vector, msg);
if (ret < 0) {
goto undo;
}
/* If guest supports masking, set up irqfd now.
* Otherwise, delay until unmasked in the frontend.
*/
if (k->guest_notifier_mask) {
ret = kvm_virtio_pci_irqfd_use(proxy, queue_no, vector);
if (ret < 0) {
kvm_virtio_pci_vq_vector_release(proxy, vector);
goto undo;
}
}
}
return 0;
undo:
while (--queue_no >= 0) {
vector = virtio_queue_vector(vdev, queue_no);
if (vector >= msix_nr_vectors_allocated(dev)) {
continue;
}
if (k->guest_notifier_mask) {
kvm_virtio_pci_irqfd_release(proxy, queue_no, vector);
}
kvm_virtio_pci_vq_vector_release(proxy, vector);
}
return ret;
}
If irqfd is not set, guest notifier fd will notify the qemu process waiting for fd, enter the registration function virtio_queue_guest_notifier_read, call virtio_irq, and finally call virtio_pci_notify
static void virtio_queue_guest_notifier_read(EventNotifier *n)
{
VirtQueue *vq = container_of(n, VirtQueue, guest_notifier);
if (event_notifier_test_and_clear(n)) {
virtio_irq(vq);
}
}
void virtio_irq(VirtQueue *vq)
{
trace_virtio_irq(vq);
vq->vdev->isr |= 0x01;
virtio_notify_vector(vq->vdev, vq->vector);
}
static void virtio_notify_vector(VirtIODevice *vdev, uint16_t vector)
{
BusState *qbus = qdev_get_parent_bus(DEVICE(vdev));
VirtioBusClass *k = VIRTIO_BUS_GET_CLASS(qbus);
if (k->notify) {
k->notify(qbus->parent, vector);
}
}
static void virtio_pci_notify(DeviceState *d, uint16_t vector)
{
VirtIOPCIProxy *proxy = to_virtio_pci_proxy_fast(d);
if (msix_enabled(&proxy->pci_dev))
msix_notify(&proxy->pci_dev, vector);
else {
VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);
pci_set_irq(&proxy->pci_dev, vdev->isr & 1);
}
}
guest to host direction
The guest generates VMEXIT by writing to the pci configuration space, and after being intercepted by kvm, it triggers the notification of registration fd
kvm_init:
memory_listener_register(&kvm_memory_listener, &address_space_memory);
memory_listener_register(&kvm_io_listener, &address_space_io);
static MemoryListener kvm_memory_listener = {
.region_add = kvm_region_add,
.region_del = kvm_region_del,
.log_start = kvm_log_start,
.log_stop = kvm_log_stop,
.log_sync = kvm_log_sync,
.log_global_start = kvm_log_global_start,
.log_global_stop = kvm_log_global_stop,
.eventfd_add = kvm_mem_ioeventfd_add,
.eventfd_del = kvm_mem_ioeventfd_del,
.coalesced_mmio_add = kvm_coalesce_mmio_region,
.coalesced_mmio_del = kvm_uncoalesce_mmio_region,
.priority = 10,
};
static MemoryListener kvm_io_listener = {
.eventfd_add = kvm_io_ioeventfd_add,
.eventfd_del = kvm_io_ioeventfd_del,
.priority = 10,
};
static void kvm_io_ioeventfd_add(MemoryListener *listener,
MemoryRegionSection *section,
bool match_data, uint64_t data,
EventNotifier *e)
{
int fd = event_notifier_get_fd(e);
int r;
r = kvm_set_ioeventfd_pio(fd, section->offset_within_address_space,
data, true, int128_get64(section->size),
match_data);
if (r < 0) {
fprintf(stderr, "%s: error adding ioeventfd: %s
",
__func__, strerror(-r));
abort();
}
}
And kvm_io_ioeventfd_add finally called kvm_set_ioeventfd_pio, which called kvm_vm_ioctl (kvm_state, KVM_IOEVENTFD, & kick) into kvm.ko
static int kvm_set_ioeventfd_pio(int fd, uint16_t addr, uint16_t val,
bool assign, uint32_t size, bool datamatch)
{
struct kvm_ioeventfd kick = {
.datamatch = datamatch ? val : 0,
.addr = addr,
.flags = KVM_IOEVENTFD_FLAG_PIO,
.len = size,
.fd = fd,
};
int r;
if (!kvm_enabled()) {
return -ENOSYS;
}
if (datamatch) {
kick.flags |= KVM_IOEVENTFD_FLAG_DATAMATCH;
}
if (!assign) {
kick.flags |= KVM_IOEVENTFD_FLAG_DEASSIGN;
}
r = kvm_vm_ioctl(kvm_state, KVM_IOEVENTFD, &kick);
if (r < 0) {
return r;
}
return 0;
}
KVM_IOEVENTFD's ioctl finally calls kvm's kvm_ioeventfd function, which will call kvm_assign_ioeventfd or kvm_deassign_ioeventfd
int
kvm_ioeventfd (struct kvm * kvm, struct kvm_ioeventfd * args)
{
if (args-> flags & KVM_IOEVENTFD_FLAG_DEASSIGN)
return kvm_deassign_ioeventfd (kvm, args);
return kvm_assign_ioeventfd (kvm, args);
}
static int
kvm_assign_ioeventfd (struct kvm * kvm, struct kvm_ioeventfd * args)
{
int pio = args-> flags & KVM_IOEVENTFD_FLAG_PIO;
enum kvm_bus bus_idx = pio? KVM_PIO_BUS: KVM_MMIO_BUS;
struct _ioeventfd * p;/* ioeventfd: translate a PIO/MMIO memory write to an eventfd signal. */
struct eventfd_ctx * eventfd;/* mostly wait_queue_head_t */
int ret;
/* must be natural-word sized */
switch (args-> len) {
case 1:
case 2:
case 4:
case 8:
break;
default:
return -EINVAL;
}
/* check for range overflow */
if (args-> addr + args-> len <args-> addr)
return -EINVAL;
/* check for extra flags that we don't understand */
if (args-> flags & ~ KVM_IOEVENTFD_VALID_FLAG_MASK)
return -EINVAL;
eventfd = eventfd_ctx_fdget (args-> fd);/* file-> private_data */
if (IS_ERR (eventfd))
return PTR_ERR (eventfd);
p = kzalloc (sizeof (* p), GFP_KERNEL);/* allocate a _ioeventfd, and associate the memory address, length, eventfd_ctx with it */
if (! p) {
ret = -ENOMEM;
goto fail;
}
INIT_LIST_HEAD (& p-> list);
p-> addr = args-> addr;
p-> length = args-> len;
p-> eventfd = eventfd;
/* The datamatch feature is optional, otherwise this is a wildcard */
if (args-> flags & KVM_IOEVENTFD_FLAG_DATAMATCH)
p-> datamatch = args-> datamatch;
else
p-> wildcard = true;
mutex_lock (& kvm-> slots_lock);
/* Verify that there isnt a match already */
if (ioeventfd_check_collision (kvm, p)) {
ret = -EEXIST;
goto unlock_fail;
}
kvm_iodevice_init (& p-> dev, & ioeventfd_ops);
ret = kvm_io_bus_register_dev (kvm, bus_idx, & p-> dev);/* Register to kvm's pio bus or mmio bus */
if (ret <0)
goto unlock_fail;
list_add_tail (& p-> list, & kvm-> ioeventfds);/* Add to the list of ioeventfds of kvm.ko */
mutex_unlock (& kvm-> slots_lock);
return 0;
unlock_fail:
mutex_unlock (& kvm-> slots_lock);
fail:
kfree (p);
eventfd_ctx_put (eventfd);
return ret;
}
In kvm_assign_ioeventfd, by registering a pio/mmio address segment and an fd, the VMEXIT generated when accessing this memory will be converted into fd event notification in kvm.ko,static const struct kvm_io_device_ops ioeventfd_ops = {
.write = ioeventfd_write,
.destructor = ioeventfd_destructor,
};
/* MMIO/PIO writes trigger an event if the addr/val match */
static int
ioeventfd_write(struct kvm_io_device *this, gpa_t addr, int len,
const void *val)
{
struct _ioeventfd *p = to_ioeventfd(this);
if (!ioeventfd_in_range(p, addr, len, val))
return -EOPNOTSUPP;
eventfd_signal(p->eventfd, 1);
return 0;
}
Finally, take vhost-net as an example to explain the initialization and sending and receiving process of vhost network packets, eg
qemu uses netdev tap, vhost = on to specify the backend based on vhost when creating a network device. net_init_tap will call net_init_tap_one to initialize vhost for each queue of vhost. The initialization work is done through vhost_net_init
typedef struct VhostNetOptions {
VhostBackendType backend_type;/* vhost kernel or userspace */
NetClientState * net_backend;/* TAPState device */
void * opaque;/* ioctl vhostfd,/dev/vhost-net */
bool force;
} VhostNetOptions;
static int net_init_tap_one (const NetdevTapOptions * tap, NetClientState * peer,
const char * model, const char * name,
const char * ifname, const char * script,
const char * downscript, const char * vhostfdname,
int vnet_hdr, int fd)
{
...
if (tap-> has_vhost? tap-> vhost:
vhostfdname || (tap-> has_vhostforce && tap-> vhostforce)) {
VhostNetOptions options;
options.backend_type = VHOST_BACKEND_TYPE_KERNEL;
options.net_backend = & s-> nc;
options.force = tap-> has_vhostforce && tap-> vhostforce;
if ((tap-> has_vhostfd || tap-> has_vhostfds)) {
vhostfd = monitor_handle_fd_param (cur_mon, vhostfdname);
if (vhostfd == -1) {
return -1;
}
} else {
vhostfd = open ("/dev/vhost-net", O_RDWR);/* open/dev/vhost-net for ioctl usage */
if (vhostfd <0) {
error_report ("tap: open vhost char device failed:% s",
strerror (errno));
return -1;
}
}
qemu_set_cloexec (vhostfd);
options.opaque = (void *) (uintptr_t) vhostfd;
s-> vhost_net = vhost_net_init (& options);/* initialize struct vhost_net */
if (! s-> vhost_net) {
error_report ("vhost-net requested but could not be initialized");
return -1;
}
}
...
}
struct vhost_net {
struct vhost_dev dev;
struct vhost_virtqueue vqs [2];
int backend;
NetClientState * nc;
};
vhost_dev_init
struct vhost_net * vhost_net_init (VhostNetOptions * options)
{
int r;
bool backend_kernel = options-> backend_type == VHOST_BACKEND_TYPE_KERNEL;
struct vhost_net * net = g_malloc (sizeof * net);
if (! options-> net_backend) {
fprintf (stderr, "vhost-net requires net backend to be setup
");
goto fail;
}
if (backend_kernel) {
r = vhost_net_get_fd (options-> net_backend);
if (r <0) {
goto fail;
}
net-> dev.backend_features = qemu_has_vnet_hdr (options-> net_backend)
? 0: (1 << VHOST_NET_F_VIRTIO_NET_HDR);
net-> backend = r;/* backend is set to fd corresponding to NetClientState */
} else {
net-> dev.backend_features = 0;
net-> backend = -1;
}
net-> nc = options-> net_backend;/* nc is set to NetClientState */
net-> dev.nvqs = 2;/* TX queue and RX queue */
net-> dev.vqs = net-> vqs;/* vhost_dev, vhost_net public vhost_virtqueue */
r = vhost_dev_init (& net-> dev, options-> opaque,
options-> backend_type, options-> force);/* Initialize vhost_dev, here create vhost kthread by ioctl of VHOST_SET_OWNER */
if (r <0) {
goto fail;
}
if (! qemu_has_vnet_hdr_len (options-> net_backend,
sizeof (struct virtio_net_hdr_mrg_rxbuf))) {
net-> dev.features & = ~ (1 << VIRTIO_NET_F_MRG_RXBUF);
}
if (backend_kernel) {
if (~ net-> dev.features & net-> dev.backend_features) {
fprintf (stderr, "vhost lacks feature mask%" PRIu64
"for backend
",
(uint64_t) (~ net-> dev.features & net-> dev.backend_features));
vhost_dev_cleanup (& net-> dev);
goto fail;
}
}
/* Set sane init value. Override when guest acks. */
vhost_net_ack_features (net, 0);
return net;
fail:
g_free (net);
return NULL;
}
When the guest starts successfully, qemu will configure the corresponding vhost, call virtio_net_set_status to turn on/off virtio-net devices and queues, virtio_net_set_status will call to vhost_net_start to open the vhost queue, and call vhost_net_stop to close the vhost queue
int vhost_net_start (VirtIODevice * dev, NetClientState * ncs,
int total_queues)
{
BusState * qbus = BUS (qdev_get_parent_bus (DEVICE (dev)));
VirtioBusState * vbus = VIRTIO_BUS (qbus);
VirtioBusClass * k = VIRTIO_BUS_GET_CLASS (vbus);
int r, e, i;
if (! vhost_net_device_endian_ok (dev)) {
error_report ("vhost-net does not support cross-endian");
r = -ENOSYS;
goto err;
}
if (! k-> set_guest_notifiers) {
error_report ("binding does not support guest notifiers");
r = -ENOSYS;
goto err;
}
for (i = 0; i <total_queues; i ++) {
vhost_net_set_vq_index (get_vhost_net (ncs [i] .peer), i * 2);
}
/* Call virtio_pci_set_guest_notifiers to configure information such as irqfd; if there is no enable vhost, qemu will also call here */
r = k-> set_guest_notifiers (qbus-> parent, total_queues * 2, true);
if (r <0) {
error_report ("Error binding guest notifier:% d", -r);
goto err;
}
/* If tun supports multi-queue scenarios, there will be multiple NetClientStates, one for each tap device queue, and each NetClientState will correspond to a vhost_net structure */
for (i = 0; i <total_queues; i ++) {
r = vhost_net_start_one (get_vhost_net (ncs [i] .peer), dev);/* call vhost_net_start_one for each queue */
if (r <0) {
goto err_start;
}
}
return 0;
err_start:
while (--i> = 0) {
vhost_net_stop_one (get_vhost_net (ncs [i] .peer), dev);
}
e = k-> set_guest_notifiers (qbus-> parent, total_queues * 2, false);
if (e <0) {
fprintf (stderr, "vhost guest notifier cleanup failed:% d
", e);
fflush (stderr);
}
err:
return r;
}
static int vhost_net_start_one (struct vhost_net * net,
VirtIODevice * dev)
{
struct vhost_vring_file file = {};
int r;
if (net-> dev.started) {
return 0;
}
net-> dev.nvqs = 2;/* vqs contains a TX virtqueue and an RX virtqueue */
net-> dev.vqs = net-> vqs;
/* Call <span style = "font-family: Arial, Helvetica, sans-serif;"> virtio_pci_set_guest_notifiers to enable vhost ioeventfd */</span>
r = vhost_dev_enable_notifiers (& net-> dev, dev);/* Stop processing guest IO notifications in qemu and start processing guest IO notifications in vhost */
if (r <0) {
goto fail_notifiers;
}
r = vhost_dev_start (& net-> dev, dev);
if (r <0) {
goto fail_start;
}
if (net-> nc-> info-> poll) {
net-> nc-> info-> poll (net-> nc, false);
}
if (net-> nc-> info-> type == NET_CLIENT_OPTIONS_KIND_TAP) {
qemu_set_fd_handler (net-> backend, NULL, NULL, NULL);
file.fd = net-> backend;
for (file.index = 0; file.index <net-> dev.nvqs; ++ file.index) {
const VhostOps * vhost_ops = net-> dev.vhost_ops;
r = vhost_ops-> vhost_call (& net-> dev, VHOST_NET_SET_BACKEND,
& file);
if (r <0) {
r = -errno;
goto fail;
}
}
}
return 0;
fail:
file.fd = -1;
if (net-> nc-> info-> type == NET_CLIENT_OPTIONS_KIND_TAP) {
while (file.index--> 0) {
const VhostOps * vhost_ops = net-> dev.vhost_ops;
int r = vhost_ops-> vhost_call (& net-> dev, VHOST_NET_SET_BACKEND,
& file);
assert (r> = 0);
}
}
if (net-> nc-> info-> poll) {
net-> nc-> info-> poll (net-> nc, true);
}
vhost_dev_stop (& net-> dev, dev);
fail_start:
vhost_dev_disable_notifiers (& net-> dev, dev);
fail_notifiers:
return r;
}
The relationship between the various data structures of vhost net is shown in the figure below
Let's take a look at the definition of vhost_net by the kernel, eg
static const struct file_operations vhost_net_fops = {
.owner = THIS_MODULE,
.release = vhost_net_release,
.unlocked_ioctl = vhost_net_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = vhost_net_compat_ioctl,
#endif
.open = vhost_net_open,
};
static struct miscdevice vhost_net_misc = {
MISC_DYNAMIC_MINOR,
"vhost-net",
& vhost_net_fops,
};
enum {
VHOST_NET_VQ_RX = 0,
VHOST_NET_VQ_TX = 1,
VHOST_NET_VQ_MAX = 2,
};
enum vhost_net_poll_state {
VHOST_NET_POLL_DISABLED = 0,
VHOST_NET_POLL_STARTED = 1,
VHOST_NET_POLL_STOPPED = 2,
};
struct vhost_net {
struct vhost_dev dev;
struct vhost_virtqueue vqs [VHOST_NET_VQ_MAX];/* vhost's virtqueue package, its handle_kick callback function will be awakened by ioeventfd */
struct vhost_poll poll [VHOST_NET_VQ_MAX];/* socket IO corresponding to NetClientState, using two vhost_poll structures */
/* Tells us whether we are polling a socket for TX.
* We only do this when socket buffer fills up.
* Protected by tx vq lock. */
enum vhost_net_poll_state tx_poll_state;
};
static int vhost_net_open (struct inode * inode, struct file * f)
{
struct vhost_net * n = kmalloc (sizeof * n, GFP_KERNEL);
struct vhost_dev * dev;
int r;
if (! n)
return -ENOMEM;
dev = & n-> dev;
n-> vqs [VHOST_NET_VQ_TX] .handle_kick = handle_tx_kick;/* TX virtqueue-> kick callback function */
n-> vqs [VHOST_NET_VQ_RX] .handle_kick = handle_rx_kick;/* RX virtqueue-> kick callback function */
r = vhost_dev_init (dev, n-> vqs, VHOST_NET_VQ_MAX);
if (r <0) {
kfree (n);
return r;
}
vhost_poll_init (n-> poll + VHOST_NET_VQ_TX, handle_tx_net, POLLOUT, dev);/* initialize TX vhost_poll of vhost_net */
vhost_poll_init (n-> poll + VHOST_NET_VQ_RX, handle_rx_net, POLLIN, dev);/* RX vhost_poll to initialize vhost_net */
n-> tx_poll_state = VHOST_NET_POLL_DISABLED;
f-> private_data = n;
return 0;
}
The implementation of handle_tx_kick/handle_rx_kick is exactly the same as handle_tx_net/handle_rx_net. Why are there two different functions here? After reading the following code analysis, you will have an answer, but I will first spoiler here, handle_tx_kick/handle_rx_kick is the callback function blocked on the kick fd of TX queue/RX queue, handle_tx_net/handle_rx_net is blocked in vhost_net TX poll The blocking function on/RX poll, whether for TX or RX, the path of the message is a two-stage process, eg
TX is first the kick virtqueue's fd, then the buffering of the vring is transmitted, and finally it is sent through the socket fd of NetClientState, but the socket may have insufficient buffers, or the quota sent this time is not enough, etc. At this time, the poll needs to be in the socket. Block waiting on fd. The same is true for RX, which is blocked on the socket fd in the first stage and blocked on the virtqueue kick fd in the second stage
As mentioned in the previous analysis, qemu will obtain the rfd of the host_notifier of VirtQueue when vhost_virtqueue_start, and pass the fd to kvm.ko through VHOST_SET_VRING_KICK, so that kvm.ko will notify this fd through eventfd_signal later. The vhost module will associate this fd with vhost_virtqueue-> kick, and eventually call vhost_poll_start to block on this poll fd.
When the guest sends a message, ioeventfd triggers the kick fd of vhost_virtqueue, the POLLIN event causes vhost_poll_wakeup to be called, and finally wakes up the vhost worker thread, the thread will call the registered handle_kick function, namely handle_tx_kick
static void handle_tx_kick (struct vhost_work * work)
{
struct vhost_virtqueue * vq = container_of (work, struct vhost_virtqueue,
poll.work);
struct vhost_net * net = container_of (vq-> dev, struct vhost_net, dev);
handle_tx (net);
}
static void handle_tx (struct vhost_net * net)
{
struct vhost_virtqueue * vq = & net-> dev.vqs [VHOST_NET_VQ_TX];
unsigned out, in, s;
int head;
struct msghdr msg = {
.msg_name = NULL,
.msg_namelen = 0,
.msg_control = NULL,
.msg_controllen = 0,
.msg_iov = vq-> iov,
.msg_flags = MSG_DONTWAIT,
};
size_t len, total_len = 0;
int err, wmem;
size_t hdr_size;
struct vhost_ubuf_ref * uninitialized_var (ubufs);
bool zcopy;
struct socket * sock = rcu_dereference (vq-> private_data);/* The socket corresponding to NetClientState is stored in vhost_virtqueue as private_data */
if (! sock)
return;
wmem = atomic_read (& sock-> sk-> sk_wmem_alloc);
if (wmem> = sock-> sk-> sk_sndbuf) {/* The socket write memory that has been applied for exceeds the send buffer */
mutex_lock (& vq-> mutex);
tx_poll_start (net, sock);/* Cannot send at this time, blocking waiting on sock */
mutex_unlock (& vq-> mutex);
return;
}
mutex_lock (& vq-> mutex);
vhost_disable_notify (& net-> dev, vq);/* disable notify notification of virtqueue, through VRING_USED_F_NO_NOTIFY flag bit */
if (wmem <sock-> sk-> sk_sndbuf/2)
tx_poll_stop (net);
hdr_size = vq-> vhost_hlen;
zcopy = vq-> ubufs;
for (;;) {
/* Release DMAs done buffers first */
if (zcopy)
vhost_zerocopy_signal_used (vq);
head = vhost_get_vq_desc (& net-> dev, vq, vq-> iov,/* Starting from last_avail_idx, copy the avail desc content */
ARRAY_SIZE (vq-> iov),
& out, & in,
NULL, NULL);
/* On error, stop handling until the next kick. */
if (unlikely (head <0))
break;
/* Nothing new? Wait for eventfd to tell us they refilled. */
if (head == vq-> num) {/* At this time vq-> avail_idx == vq-> last_avail_idx, there is no new buf coming from the front end
int num_pends;
wmem = atomic_read (& sock-> sk-> sk_wmem_alloc);
if (wmem> = sock-> sk-> sk_sndbuf * 3/4) {
tx_poll_start (net, sock);
set_bit (SOCK_ASYNC_NOSPACE, & sock-> flags);
break;
}
/* If more outstanding DMAs, queue the work.
* Handle upend_idx wrap around
*/
num_pends = likely (vq-> upend_idx> = vq-> done_idx)?
(vq-> upend_idx-vq-> done_idx):
(vq-> upend_idx + UIO_MAXIOV-vq-> done_idx);
if (unlikely (num_pends> VHOST_MAX_PEND)) {
tx_poll_start (net, sock);
set_bit (SOCK_ASYNC_NOSPACE, & sock-> flags);
break;
}
if (unlikely (vhost_enable_notify (& net-> dev, vq))) {/* Recall vhost_enable_notify to open the event notify flag */
vhost_disable_notify (& net-> dev, vq);/* vhost_enable_notify returns false, indicating that avail_idx has changed, then continue */
continue;
}
break;
}
if (in) {/* Tx should all be out */
vq_err (vq, "Unexpected descriptor format for TX:"
"out% d, int% d
", out, in);
break;
}
/* Skip header. TODO: support TSO. */
s = move_iovec_hdr (vq-> iov, vq-> hdr, hdr_size, out);/* hdr_size is the metadata of VNET_HDR, there is no actual message content */
msg.msg_iovlen = out;
len = iov_length (vq-> iov, out);
/* Sanity check */
if (! len) {
vq_err (vq, "Unexpected header len for TX:"
"% zd expected% zd
",
iov_length (vq-> hdr, s), hdr_size);
break;
}
/* use msg_control to pass vhost zerocopy ubuf info to skb */
if (zcopy) {
vq-> heads [vq-> upend_idx] .id = head;
if (len <VHOST_GOODCOPY_LEN) {
/* copy don't need to wait for DMA done */
vq-> heads [vq-> upend_idx] .len =
VHOST_DMA_DONE_LEN;
msg.msg_control = NULL;
msg.msg_controllen = 0;
ubufs = NULL;
} else {
struct ubuf_info * ubuf = & vq-> ubuf_info [head];
vq-> heads [vq-> upend_idx] .len = len;
ubuf-> callback = vhost_zerocopy_callback;
ubuf-> arg = vq-> ubufs;
ubuf-> desc = vq-> upend_idx;
msg.msg_control = ubuf;
msg.msg_controllen = sizeof (ubuf);
ubufs = vq-> ubufs;
kref_get (& ubufs-> kref);
}
vq-> upend_idx = (vq-> upend_idx + 1)% UIO_MAXIOV;
}
/* TODO: Check specific error and bomb out unless ENOBUFS? */
err = sock-> ops-> sendmsg (NULL, sock, & msg, len);
if (unlikely (err <0)) {
if (zcopy) {
if (ubufs)
vhost_ubuf_put (ubufs);
vq-> upend_idx = ((unsigned) vq-> upend_idx-1)%
UIO_MAXIOV;
}
vhost_discard_vq_desc (vq, 1);/* Send failed, roll back last_avail_idx */
if (err == -EAGAIN || err == -ENOBUFS)
tx_poll_start (net, sock);/* Block waiting for vhost_net-> poll and then try to send again */
break;
}
if (err! = len)
pr_debug ("Truncated TX packet:"
"len% d! =% zd
", err, len);
if (! zcopy)
vhost_add_used_and_signal (& net-> dev, vq, head, 0);/* Update virtqueue used ring part, eg used_elem, last_used_idx */
else
vhost_zerocopy_signal_used (vq);
total_len + = len;
if (unlikely (total_len> = VHOST_NET_WEIGHT)) {
vhost_poll_queue (& vq-> poll);/* Exceed the quota, re-enter the queue and wait for scheduling */
break;
}
}
mutex_unlock (& vq-> mutex);
}
In the process of receiving packets, the vhost is blocked on the NetClientState socket, eg
vhost_poll_init (n-> poll + VHOST_NET_VQ_RX, handle_rx_net, POLLIN, dev)
static void handle_rx_net (struct vhost_work * work)
{
struct vhost_net * net = container_of (work, struct vhost_net,
poll [VHOST_NET_VQ_RX] .work);
handle_rx (net);
}
static void handle_rx (struct vhost_net * net)
{
struct vhost_virtqueue * vq = & net-> dev.vqs [VHOST_NET_VQ_RX];
unsigned uninitialized_var (in), log;
struct vhost_log * vq_log;
struct msghdr msg = {
.msg_name = NULL,
.msg_namelen = 0,
.msg_control = NULL,/* FIXME: get and handle RX aux data. */
.msg_controllen = 0,
.msg_iov = vq-> iov,
.msg_flags = MSG_DONTWAIT,
};
struct virtio_net_hdr_mrg_rxbuf hdr = {
.hdr.flags = 0,
.hdr.gso_type = VIRTIO_NET_HDR_GSO_NONE
};
size_t total_len = 0;
int err, headcount, mergeable;
size_t vhost_hlen, sock_hlen;
size_t vhost_len, sock_len;
struct socket * sock = rcu_dereference (vq-> private_data);
if (! sock)
return;
mutex_lock (& vq-> mutex);
vhost_disable_notify (& net-> dev, vq);/* disable virtqueue event notify mechanism */
vhost_hlen = vq-> vhost_hlen;
sock_hlen = vq-> sock_hlen;
vq_log = unlikely (vhost_has_feature (& net-> dev, VHOST_F_LOG_ALL))?
vq-> log: NULL;
mergeable = vhost_has_feature (& net-> dev, VIRTIO_NET_F_MRG_RXBUF);
while ((sock_len = peek_head_len (sock-> sk))) {/* Length of next message */
sock_len + = sock_hlen;
vhost_len = sock_len + vhost_hlen;
headcount = get_rx_bufs (vq, vq-> heads, vhost_len,/* get_rx_bufs is used to get multiple avail desc from virtqueue, */
& in, vq_log, & log,/* until all these iovs are added together to accommodate the length of the next message */
likely (mergeable)? UIO_MAXIOV: 1);/* is equivalent to calling <span style = "font-family: Arial, Helvetica, sans-serif;"> vhost_get_vq_desc */</span>
/* On error, stop handling until the next kick. */
if (unlikely (headcount <0))
break;
/* OK, now we need to know about added descriptors. */
if (! headcount) {
if (unlikely (vhost_enable_notify (& net-> dev, vq))) {
/* They have slipped one in as we were
* doing that: check again. */
vhost_disable_notify (& net-> dev, vq);
continue;
}
/* Nothing new? Wait for eventfd to tell us
* they refilled. */
break;
}
/* We don't need to be notified again. */
if (unlikely ((vhost_hlen)))
/* Skip header. TODO: support TSO. */
move_iovec_hdr (vq-> iov, vq-> hdr, vhost_hlen, in);
else
/* Copy the header for use in VIRTIO_NET_F_MRG_RXBUF:
* needed because sendmsg can modify msg_iov. */
copy_iovec_hdr (vq-> iov, vq-> hdr, sock_hlen, in);
msg.msg_iovlen = in;
err = sock-> ops-> recvmsg (NULL, sock, & msg,
sock_len, MSG_DONTWAIT | MSG_TRUNC);/* message was received in virtqueue-> iov */
/* Userspace might have consumed the packet meanwhile:
* it's not supposed to do this usually, but might be hard
* to prevent. Discard data we got (if any) and keep going. */
if (unlikely (err! = sock_len)) {
pr_debug ("Discarded rx packet:"
"len% d, expected% zd
", err, sock_len);
vhost_discard_vq_desc (vq, headcount);/* roll back used ring */
continue;
}
if (unlikely (vhost_hlen) &&
memcpy_toiovecend (vq-> hdr, (unsigned char *) & hdr, 0,
vhost_hlen)) {
vq_err (vq, "Unable to write vnet_hdr at addr% p
",
vq-> iov-> iov_base);
break;
}
/* TODO: Should check and handle checksum. */
if (likely (mergeable) &&
memcpy_toiovecend (vq-> hdr, (unsigned char *) & headcount,
offsetof (typeof (hdr), num_buffers),
sizeof hdr.num_buffers)) {
vq_err (vq, "Failed num_buffers write");
vhost_discard_vq_desc (vq, headcount);
break;
}
vhost_add_used_and_signal_n (& net-> dev, vq, vq-> heads,
headcount);/* Add multiple vring_used_elem and notify the front end */
if (unlikely (vq_log))
vhost_log_write (vq, vq_log, log, vhost_len);
total_len + = vhost_len;
if (unlikely (total_len> = VHOST_NET_WEIGHT)) {
vhost_poll_queue (& vq-> poll);/* Exceed the quota, re-enter the queue and wait. Please note that the vq poll is added at this time, and the handle_rx_kick will be called next time
break;
}
}
mutex_unlock (& vq-> mutex);
}